Crucial M550 Review: 128GB, 256GB, 512GB and 1TB Models Tested
by Kristian Vättö on March 18, 2014 8:00 AM ESTNAND Lesson: Why Die Capacity Matters
SSDs are basically just huge RAID arrays of NAND. A single NAND die isn't very fast but when you put a dozen or more of them in parallel, the performance adds up. Modern SSDs usually have between 8 and 64 NAND dies depending on the capacity and the rule of "the more, the better" applies here, at least to a certain degree. (Controllers are usually designed for a certain amount of NAND die, so too many dies can negatively impact performance because the controller has more pages/blocks to track and process.) But die parallelism is just a part of the big picture—it all starts inside the die.
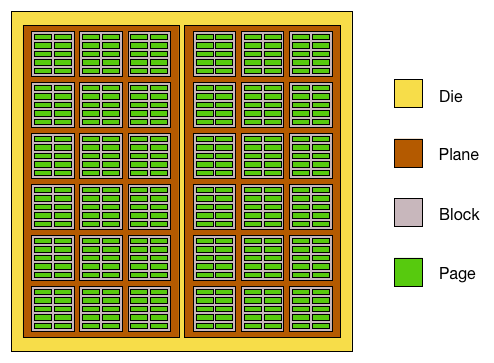
Meet the inside version of our Mr. NAND die. Each die is usually divided into two planes, which are further divided into blocks that are then divided into pages. In the early NAND days there were no planes, just blocks and pages, but as the die capacities increased the manufacturers had to find a way to get more performance out of a single die. The solution was to divide the die into two planes, which can be read from or written to (nearly) simultaneously. Without planes you could only read or program one page per die at a time but two-plane reading/programming allows two pages to be read or programmed at the same time.
The reason I said "nearly" is because programming the NAND involves more than just the programming time. There is latency from all the command, address and data inputs, which are marginal compared to the program time but with two-plane programming they take twice the time (you'll still have to send all the necessary commands and addresses separately for both soon-to-be-programmed pages).
I did some rough calculations based on the data I have (though to be honest, it's probably not enough to make my calculations bulletproof) and it seems that the two-plane programming latency is about 2% compared to two individual dies (i.e. it takes 2% longer to program two pages with two-plane programming than with two individual dies). In other words, we can conclude that two-plane programming gives us roughly twice the throughput compared to one-plane programming.
"Okay," you're thinking, "that's fine and all, but what's the point of this? This isn't a new technology and has nothing to do with the M550!" Hold on, it'll make sense as you read further.
Case: M500
| M550 128GB | M500 120GB | |
| NAND Die Capacity | 64Gbit (8GB) | 128Gbit (16GB) |
| NAND Page Size | 16KB | 16KB |
| Sequential Write | 350MB/s | 130MB/s |
| 4KB Random Write | 75K IOPS | 35K IOPS |
The Crucial M500 was the first client SSD to utilize 128Gbit per die NAND. That allowed Crucial to go higher than 512GB without sacrificing performance but also meant a hit in performance at the smaller capacities. As mentioned many times before, the key to SSD performance is parallelism and when the die capacity doubles, the parallelism is cut in half. For the 120/128GB model this meant that instead of having sixteen dies like in the case of 64Gbit NAND, it only had eight 128Gbit dies.
It takes 1600µs to write 16KB (one page) to Micron's 128Gbit NAND. Convert that to throughput and you get 10MB/s. Well, that's the simple version and not exactly accurate. With eight dies, the total write throughput would be only 80MB/s but the 120GB M500 is rated 130MB/s. The big picture is more than just the program time as in reality you have to take into account the interface latency as well as the gains from two-plane programming and cache-mode (the command, address and data latches are cached so there is no need to wait for them between programmings).

Example of cache programming
Like I described above, two-plane programming gives us roughly twice the throughput compared to one-plane programming. As a result, instead of writing one 16KB page in 1600µs, we are able to write two pages with 32KB of data in total. That doubles our throughput from 80MB/s to 160MB/s. There is some overhead from the commands like the picture above shows but thankfully today's interfaces are so fast that it's only in the magnitude of a few percents and in real world the usable throughput should be around 155MB/s. The 120GB M500 manages around 140MB/s in sequential write, so 155MB/s of NAND write throughput sounds reasonable since there is always some additional latency from channel and die switching. Program times are also averages and vary slightly from die to die and it's possible that the set program times may actually be slightly over 1600µs to make sure all dies meet the criteria.
Case: M550
While the M500 used solely 128Gbit NAND, Crucial is bringing back the 64Gbit die for the 128GB and 256GB M550s. The switch means twice the amount of die and as we've now learned, that means twice the performance. This is actually Micron's second generation 64Gbit 20nm NAND with 16KB page size similar to their 128Gbit NAND. The increase in page size is required for write throughput (about 60% increase over 8KB page) but it adds complexity to garbage collection and can increase write amplification if not implemented efficiently (and hence lower endurance).
Micron wouldn't disclose the program time for this part but I'm thinking there is some improvement over the original 128Gbit part. As process nodes mature, you're usually able to squeeze out a little more performance (and endurance) out of the same chip and I'm thinking that is what's happening here. To get ~370MB/s out of the 128GB M550, the program time would have to be 1300-1400µs to be inline with the performance. It's certainly possible that there's something else going on (better channel switching management for instance) but it's clear that Crucial/Micron has been able to better optimize the NAND in the M550.
The point here was to give an idea of where the NAND performance comes from and why there is such dramatical difference between the M550 and M500. Ultimately all the NAND performance characteristics are something the manufacturers won't disclose and hence the figures here may not be accurate but should at least give a rough idea of what is happening at the low level.








100 Comments
View All Comments
tech6 - Tuesday, March 18, 2014 - link
I don't think that the M550 is so much a "performance" variant as it is a direct replacement for the 500. Most likely what is happening here is that the benchmark for value SSDs has just been lifted slightly. Once the M500 disappears the 550 will assume its price point.Kristian Vättö - Tuesday, March 18, 2014 - link
The thing is, the M550 doesn't replace the M500. The M500 will continue to be available and the M550 is simply Crucial's "high-end" offering.ZeDestructor - Tuesday, March 18, 2014 - link
Interesting... Much like tech6, I was expecting the M500 to die off peacefully... Any details from micron on why they're doing that?For now, I should go and buy an M500 480GB already... They're really cheap...
Kristian Vättö - Tuesday, March 18, 2014 - link
There are still some cost savings from the 128Gbit NAND at the smaller capacities and it's possible that the controller/DRAM configurations are slightly cheaper as well. Could be that Crucial/Micron is also using slightly lower quality NAND for the M500 since the extra space reserved for RAIN makes sure that is not an issue.hojnikb - Tuesday, March 18, 2014 - link
Its interesting, that they are not using more dies per package (as opposed to samsung with evos).I'm guessing using less packages and possibly smaller pcb could yield additional cost savings for crucial/micron... Or is this not the case...? Also they could go with dramless like toshiba is doing with their q series ?
V500 anyone ?
hojnikb - Tuesday, March 18, 2014 - link
So basicly m500 is crucials/microns "low" end offering now.Just like the crappy v4 (that drive is really slow and im ashamed to own one) that was in the m4 days.
tim851 - Tuesday, March 18, 2014 - link
I hope so. I find the speed of SSDs to be sufficient for now and I'd like to see them work on pricing rather than performance.hojnikb - Tuesday, March 18, 2014 - link
Yeah i hope so too. I'm planning to buy 480GB/1TB version sometime this year to replace that sandforce joke i'm having now (intel's 330) and ditch HDDs alltogether.StevoLincolnite - Wednesday, March 19, 2014 - link
I'm running a several year old OCZ Vertex 2 64Gb SSD... Been solid.One thing I have never said however was: "Gee this SSD is slow!". - Mostly the main advantage SSD's brought to the arena was the stupidly low latencies compared to mechanical drives.
Price needs to still come down, capacities need to keep increasing in the low-end and mid-range segments.
Literally the single *biggest* upgrade that a majority of PC's could use is simply an SSD, regardless of it's transfer rates.
Even on ancient 6-7 year old Core 2 PC's...
trichome333 - Wednesday, March 19, 2014 - link
I agree mate. Just got a M500 240gb and I literally feel like a dunce for not moving earlier.