Intel Pentium 4 1.4GHz & 1.5GHz
by Anand Lal Shimpi on November 20, 2000 12:54 AM EST- Posted in
- CPUs
The Pentium 4’s Cache
We mentioned that there is another “trick” Intel implemented to nullify some of the penalties associated with having a 20-stage pipeline. We just discussed the benefits or rather the necessity of double pumping the Pentium 4’s integer units among other parts of the CPU, now it’s time to talk about another feature of Intel’s NetBurst micro-architecture.
The Pentium 4’s branch target buffer is eight times as large as that of the Pentium III, this is the area in which the branch predictor gathers its data that is used to predict branches. This is part of why the Pentium 4 has such a high prediction rate, but even taking that into account, the percentage of mis-predicted branches (as small as they may be) can seriously impact performance.
We mentioned in our article on Intel’s NetBurst micro-architecture that the Pentium 4 will feature a small 8KB L1 data cache. This is exactly half the size of the L1 data cache of the Pentium III (16KB), so why the reduction in size? Smaller caches have lower latencies so in part it was an attempt to decrease the latency of the L1 cache. In comparison, while the Athlon’s 2-way set associative 64KB L1 Data Cache has a better hit rate (larger caches have better hit rates) it has a 50% higher latency (3 clocks vs 2 clocks).
Unfortunately not all programs can fit in this L1 cache, so the Pentium 4’s L2 cache comes into play and must be fairly low latency for performance sake. We know from the introduction of the Pentium III’s Coppermine core that Intel’s on-die L2 cache is superior to that found on the Athlon’s Thunderbird core. The reason behind this is that the L2 cache has a much wider data path on the Pentium III than on the Athlon (256-bit vs 64-bit on the Thunderbird). With the Pentium 4, the L2 cache subsystem gets even better.
Again, remember that Intel’s goal here is to reduce latency while keeping cache hit rate high. By taking the Pentium III’s L2 cache and allowing it to transfer data on every clock, the Pentium 4’s L2 cache is a lower latency and higher bandwidth L2 cache than the Advanced Transfer Cache found on the Pentium III. At 1.5GHz, the Pentium 4’s L2 cache offers a 48GB/s throughput while a theoretical 1.5GHz Pentium III would only offer 24GB/s of available bandwidth. In comparison, a 1.5GHz Athlon (Thunderbird core) would only have 6GB/s of available bandwidth to its L2 cache because of its 64-bit L2 cache data path.
Let’s get back to the issue of dealing with the possibility of a mis-predicted branch. A part of Intel’s NetBurst micro-architecture is the presence of what they’re calling an Execution Trace Cache.
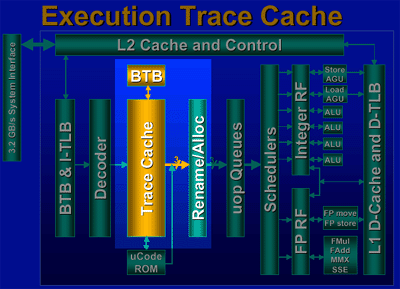
The decoder of any x86 CPU (what takes the fetched instructions and decodes them into a form understandable by the execution units) has one of the highest gate counts out of all of the pieces of logic in the core. This translates into quite a bit of time being spent in the decoding stage when preparing to process an instruction either for the first time or after a branch mis-prediction.
The Execution Trace Cache acts as a middle-man between the decoding stage and the first stage of execution after the decoding has been complete. The trace cache essentially caches decoded micro-ops (the instructions after they have been fetched and decoded, thus ready for execution) so that instead of going through the fetching and decoding process all over again when executing a new instruction, the Pentium 4 can just go straight to the trace cache, retrieve its decoded micro-op and begin execution. On the Pentium 4, the 8-way set associative Trace Cache is said to be able to cache approximately 12K micro-ops.
This helps to hide the penalties associated with a mis-predicted branch later on in the Pentium 4's 20-stage pipeline. Another benefit of the trace cache is that it caches the micro-ops in the predicted path of execution, meaning that if the Pentium 4 fetches 3 instructions from the trace cache they are already presented in their order of execution. This adds potential for an incorrectly predicted path of execution of the cached micro-ops however Intel is confident that these penalties will be minimized because of the prediction algorithms used by the Pentium 4.








22 Comments
View All Comments
g33k - Friday, May 27, 2005 - link
First Post!!!!Seriously how come no one posted on these old articles? It was an interesting read on a bit of history. :)
microAmp - Thursday, November 17, 2005 - link
Maybe because there wasn't a comment section back then? /sarcasim
Rustey118 - Wednesday, August 5, 2015 - link
10 years after first post. 15 years since article.Interesting piece of history. What ever happened to AMD's lead... :(.
For 10 year in the future reader.
I knew AMD would take the performance lead.
ruxandy - Sunday, March 28, 2021 - link
@Rustey118: 6 years into the future reader here: Dayum, man! Can I borrow your crystall ball?fortun83 - Wednesday, September 28, 2016 - link
if you are looking for a great information the best place for holiday you can look at my blog here http://pesonabromo.comBarbaraERenner - Monday, October 3, 2016 - link
Many thanks for sharing! check this page: http://clashroyaleihack.comAnonymous_87 - Wednesday, January 4, 2017 - link
this was the worst CPU by intel ever, much like Phenom launch in 2007, yet this is kind towards intel. a contrast to the phenom review. Its sad the bias.Dr AB - Saturday, May 9, 2020 - link
On the contrary I think this was most interesting ... With much higher memory bandwith, sadly clock speeds were not as impressive in early released models.AndrzejKalach - Friday, February 3, 2017 - link
Yeaa this history is awesome. AMD INTEL this companies needs to fight every time in the market.Good old intels CPUs! That is what i want.
Check my blog: https://proudmedia.eu - In polish but this site is very good like this awesome post!
rosek7302 - Friday, February 3, 2017 - link
hi the 50% higher clock speed very goodhttp://crgenerere.com/