The iPhone 5 Review
by Anand Lal Shimpi, Brian Klug & Vivek Gowri on October 16, 2012 11:33 AM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone 5
Decoding Swift
Section by Anand Shimpi
Apple's A6 provided a unique challenge. Typically we learn about a new CPU through an architecture disclosure by its manufacturer, tons of testing on our part and circling back with the manufacturer to better understand our findings. With the A6 there was no chance Apple was going to give us a pretty block diagram or an ISSCC paper on its architecture. And on the benchmarking side, our capabilities there are frustratingly limited as there are almost no good smartphone benchmarks. Understanding the A6 however is key to understanding the iPhone 5, and it also gives us a lot of insight into where Apple may go from here. A review of the iPhone 5 without a deep investigation into the A6 just wasn't an option.
The first task was to know its name. There's the old fantasy that knowing something's name gives you power over it, and the reality that it's just cool to know a secret code name. A tip from a reader across the globe pointed us in the right direction (thanks R!). Working backwards through some other iOS 6 code on the iPhone 5 confirmed the name. Apple's first fully custom ARM CPU core is called Swift.
Next we needed to confirm clock speed. Swift's operating frequency would give us an idea of how much IPC has improved over the Cortex A9 architecture. Geekbench was updated after our original iPhone 5 performance preview to more accurately report clock speed (previously we had to get one thread running in the background then launch Geekbench to get a somewhat accurate frequency reading). At 1.3GHz, Swift clearly ran at a higher frequency than the 800MHz Cortex A9 in Apple's A5 but not nearly as high as solutions from Qualcomm, NVIDIA, Samsung or TI. Despite the only 62.5% increase in frequency, Apple was promising up to a 2x increase in performance. It's clear Swift would have to be more than just a clock bumped Cortex A9. Also, as Swift must remain relevant through the end of 2013 before the next iPhone comes out, it had to be somewhat competitive with Qualcomm's Krait and ARM's Cortex A15. Although Apple is often talked about as not being concerned with performance and specs, the truth couldn't be farther from it. Shipping a Cortex A9 based SoC in its flagship smartphone through the end of 2013 just wouldn't cut it. Similarly, none of the SoC vendors would have something A15-based ready in time for volume production in Q3 2012 which helped force Apple's hand in designing its own core.
With a codename and clock speed in our hands, we went about filling in the blanks.
Some great work on behalf of Chipworks gave us a look at the cores themselves, which Chipworks estimated to be around 50% larger than the Cortex A9 cores used in the A5.

Two Apple Swift CPU cores, photo courtesy Chipworks, annotations ours
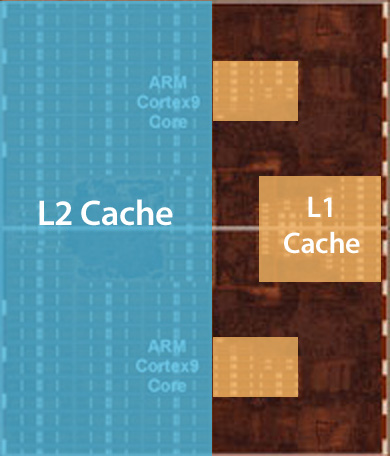
Two ARM Cortex A9 cores , photo courtesy Chipworks, annotations ours
Looking at the die shots you see a much greater logic to cache ratio in Swift compared to ARM's Cortex A9. We know that L1/L2 cache sizes haven't changed (32KB/1MB, respectively) so it's everything else that has grown in size and complexity.
The first thing I wanted to understand was how much low level compute performance has changed. Thankfully we have a number of microbenchmarks available that show us just this. There are two variables that make comparisons to ARM's Cortex A9 difficult: Swift presumably has a new architecture, and it runs at a much higher clock speed than the Cortex A9 in Apple's A5 SoC. For the tables below you'll see me compare directly to the 800MHz Cortex A9 used in the iPhone 4S, as well as a hypothetical 1300MHz Cortex A9 (1300/800 * iPhone 4S result). The point here is to give me an indication of how much performance has improved if we take clock speed out of the equation. Granted the Cortex A9 won't see perfect scaling going from 800MHz to 1300MHz, however most of the benchmarks we're looking at here are small enough to fit in processor caches and should scale relatively well with frequency.
Our investigation begins with Geekbench 2, which ends up being a great tool for looking at low level math performance. The suite is broken up into integer, floating point and memory workloads. We'll start with the integer tests. I don't have access to Geekbench source but I did my best to map the benchmarks to the type of instructions and parts of the CPU core they'd be stressing in the descriptions below.
| Geekbench 2 | ||||||
| Integer Tests | Apple A5 (2 x Cortex A9 @ 800MHz | Apple A5 Scaled (2 x Cortex A9 @ 1300MHz | Apple A6 (2 x Swift @ 1300MHz | Swift / A9 Perf Advantage @ 1300MHz | ||
| Blowfish | 10.7 MB/s | 17.4 MB/s | 23.4 MB/s | 34.6% | ||
| Blowfish MT | 20.7 MB/s | 33.6 MB/s | 45.6 MB/s | 35.6% | ||
| Text Compression | 1.21 MB/s | 1.97 MB/s | 2.79 MB/s | 41.9% | ||
| Text Compression MP | 2.28 MB/s | 3.71 MB/s | 5.19 MB/s | 40.1% | ||
| Text Decompression | 1.71 MB/s | 2.78 MB/s | 3.82 MB/s | 37.5% | ||
| Text Decompression MP | 2.84 MB/s | 4.62 MB/s | 5.88 MB/s | 27.3% | ||
| Image Compression | 3.32 Mpixels/s | 5.40 Mpixels/s | 7.31 Mpixels/s | 35.5% | ||
| Image Compression MP | 6.59 Mpixels/s | 10.7 Mpixels/s | 14.2 Mpixels/s | 32.6% | ||
| Image Decompression | 5.32 Mpixels/s | 8.65 Mpixels/s | 12.4 Mpixels/s | 43.4% | ||
| Image Decompression MP | 10.5 Mpixels/s | 17.1 Mpixels/s | 23.0 Mpixels/s | 34.8% | ||
| LUA | 215.4 Knodes/s | 350.0 Knodes/s | 455.0 Knodes/s | 30.0% | ||
| LUA MP | 425.6 Knodes/s | 691.6 Knodes/s | 887.0 Knodes/s | 28.3% | ||
| Average | - | - | - | 37.2% | ||
The Blowfish test is an encryption/decryption test that implements the Blowfish algorithm. The algorithm itself is fairly cache intensive and features a good amount of integer math and bitwise logical operations. Here we see the hypothetical 1.3GHz Cortex A9 would be outpaced by Swift by around 35%. In fact you'll see this similar ~30% increase in integer performance across the board.
The text compression/decompression tests use bzip2 to compress/decompress text files. As text files compress very well, these tests become great low level CPU benchmarks. The bzip2 front end does a lot of sorting, and is thus very branch as well as heavy on logical operations (integer ALUs used here). We don't know much about the size of the data set here but I think it's safe to assume that given the short run times we're not talking about compressing/decompressing all of the text in Wikipedia. It's safe to assume that these tests run mostly out of cache. Here we see a 38 - 40% advantage over a perfectly scaled Cortex A9. The MP text compression test shows the worst scaling out of the group at only 27.3% for Swift over a hypothetical 1.3GHz Cortex A9. It is entirely possible we're hitting some upper bound to simultaneous L2 cache accesses or some other memory limitation here.
The image compression/decompression tests are particularly useful as they just show JPEG compression/decompression performance, a very real world use case that's often seen in many applications (web browsing, photo viewer, etc...). The code here is once again very integer math heavy (adds, divs and muls), with some light branching. Performance gains in these tests, once again, span the 33 - 43% range compared to a perfectly scaled Cortex A9.
The final set of integer tests are scripted LUA benchmarks that find all of the prime numbers below 200,000. As with most primality tests, the LUA benchmarks here are heavy on adds/muls with a fair amount of branching. Performance gains are around 30% for the LUA tests.
On average, we see gains of around 37% over a hypothetical 1.3GHz Cortex A9. The Cortex A9 has two integer ALUs already, so it's possible (albeit unlikely) that Apple added a third integer ALU to see these gains. Another potential explanation is that the 3-wide front end allowed for better utilization of the existing two ALUs, although it's also unlikely that we see better than perfect scaling simply due to the addition of an extra decoder. If it's not more data being worked on in parallel, it's entirely possible that the data is simply getting to the execution units faster.
Let's keep digging.
MP
| Geekbench 2 | ||||||
| FP Tests | Apple A5 (2 x Cortex A9 @ 800MHz | Apple A5 Scaled (2 x Cortex A9 @ 1300MHz | Apple A6 (2 x Swift @ 1300MHz | Swift / A9 Perf Advantage @ 1300MHz | ||
| Mandlebrot | 223 MFLOPS | 362 MFLOPS | 397 MFLOPS | 9.6% | ||
| Mandlebrot MP | 438 MFLOPS | 712 MFLOPS | 766 MFLOPS | 7.6% | ||
| Dot Product | 177 MFLOPS | 288 MFLOPS | 322 MFLOPS | 12.0% | ||
| Dot Product MP | 353 MFLOPS | 574 MFLOPS | 627 MFLOPS | 9.3% | ||
| LU Decomposition | 171 MFLOPS | 278 MFLOPS | 387 MFLOPS | 39.3% | ||
| LU Decomposition MP | 348 MFLOPS | 566 MFLOPS | 767 MFLOPS | 35.6% | ||
| Primality | 142 MFLOPS | 231 MFLOPS | 370 MFLOPS | 60.3% | ||
| Primality MP | 260 MFLOPS | 423 MFLOPS | 676 MFLOPS | 60.0% | ||
| Sharpen Image | 1.35 Mpixels/s | 2.19 Mpixels/s | 4.85 Mpixels/s | 121% | ||
| Sharpen Image MP | 2.67 Mpixels/s | 4.34 Mpixels/s | 9.28 Mpixels/s | 114% | ||
| Blur Image | 0.53 Mpixels/s | 0.86 Mpixels/s | 1.96 Mpixels/s | 128% | ||
| Blur Image MP | 1.06 Mpixels/s | 1.72 Mpixels/s | 3.78 Mpixels/s | 119% | ||
| Average | - | - | - | 61.6% | ||
The FP tests for Geekbench 2 provide some very interesting data. While we saw consistent gains of 30 - 40% over our hypothetical 1.3GHz Cortex A9, Swift behaves much more unpredictably here. Let's see if we can make sense of it.
The Mandlebrot benchmark simply renders iterations of the Mandlebrot set. Here there's a lot of floating point math (adds/muls) combined with a fair amount of branching as the algorithm determines whether or not values are contained within the Mandlebrot set. It's curious that we don't see huge performance scaling here. Obviously Swift is faster than the 800MHz Cortex A9 in Apple's A5, but if the A5 were clocked at the same 1.3GHz and scaled perfectly we only see a 9.6% increase in performance from the new architecture. The Cortex A9 only has a single issue port to its floating point hardware that's also shared by its load/store hardware - this data alone would normally indicate that nothing has changed here when it comes to Swift. That would be a bit premature though...
The Dot Product test is simple enough, it computes the dot product of two FP vectors. Once again there are a lot of FP adds and muls here as the dot product is calculated. Overall performance gains are similarly timid if we scale up the Cortex A9's performance: 9 - 12% increase at the same frequency doesn't sound like a whole lot for a brand new architecture.
The LU Decomposition tests factorize a 128 x 128 matrix into a product of two matrices. The sheer size of the source matrix guarantees that this test has to hit the 1MB L2 cache in both of the architectures that we're talking about. The math involved are once again FP adds/muls, but the big change here appears to be the size of the dataset. The performance scales up comparatively. The LU Decomposition tests show 35 - 40% gains over our hypothetical 1.3GHz Cortex A9.
The Primality benchmarks perform the first few iterations of the Lucas-Lehmar test on a specific Mersenne number to determine whether or not it's prime. The math here is very heavy on FP adds, multiplies and sqrt functions. The data set shouldn't be large enough to require trips out to main memory, but we're seeing scaling that's even better than what we saw in the LU Decomposition tests. The Cortex A9 only has a single port for FP operations, it's very possible that Apple has added a second here in Swift. Why we wouldn't see similar speedups in the Mandlebrot and Dot Product tests however could boil down to the particular instruction mix used in the Primarily benchmark. The Geekbench folks also don't specify whether we're looking at FP32 or FP64 values, which could also be handled at different performance levels by the Swift architecture vs. Cortex A9.
The next two tests show the biggest gains of the FP suite. Both the sharpen and blur tests apply a convolution filter to an image stored in memory. The application of the filter itself is a combination of matrix multiplies, adds, divides and branches. The size of the data set likely hits the data cache a good amount.
We still haven't gained too much at this point. Simple FP operations don't see a huge improvement in performance over a perfectly scaled Cortex A9, while some others show tremendous gains. There seems to be a correlation with memory accesses which makes sense given what we know about Swift's memory performance. Improved memory performance also lends some credibility to the earlier theory about why integer performance goes up by so much: data cache access latency could be significantly improved.








{kind=link}
276 Comments
View All Comments
dado023 - Tuesday, October 16, 2012 - link
These days for me is battery life and then screen usability, so my next buy will be 720p, with iPhone5 setting the bar, i hope other android makers will follow.Krysto - Tuesday, October 16, 2012 - link
Are you implying iPhone 5 is setting the bar for 720p displays? Because first of all, it doesn't have an 1280x720 resolution, but a 1136x640 one, and second, Android devices have been sporting 720p displays since a year ago.hapkiman - Tuesday, October 16, 2012 - link
I have an iPhone 5 and my wife has a Samsung Galaxy S III.Her Galaxy S III has a Super AMOLED 1280x720 display.
And yes my iPhone 5 "only" has a 1136 x 640 display.
But guess what - I'm holding both phones side by side right now looking at the exact same game and there is no perceivable difference. I looked at it, my son looked at it, and my wife looked at it. On about five or six different games, videos, apps, and a few photos. The difference is academic. You cant tell a difference unless you have a bionic eye.
They both look freakin' fantastic.
reuthermonkey1 - Tuesday, October 16, 2012 - link
I think you're missing Krysto's point. Of course looking at a 4" 1136 x 640 and a 4.8" 1280x720 display side by side will look equivalent to the eye. But his response wasn't to whether they're similar, but to the minimum requirement dado023 has set for their next purchase to be 720p.The iPhone5's screen looks fantastic, but it's not 720p, so it's not exactly setting the bar for 720p.
Samus - Wednesday, October 17, 2012 - link
I'm no Apple fan, but in their defense, it is completely unneccessary to have 720p resolution on a 4" screen.The ppi of the screen is already 20% higher than is discernible by the human eye. Having the resolution any higher would be a waste of processing power.
afkrotch - Wednesday, October 17, 2012 - link
More screen real estate. Higher resolution, more crap you can throw on it. Course ih a 4" or 4.8" display, how many icons can you really place on the screen. I have a 4" screen and I wished I could shrink my icons though. Would love to get more icons on there.I can't do large phones anymore. I had a 5" Dell Streak...no thanks. Too big.
rarson - Wednesday, October 17, 2012 - link
"The ppi of the screen is already 20% higher than is discernible by the human eye."Uh, no it's not. The resolution of a human retina is higher than 326 ppi.
Silma - Thursday, October 18, 2012 - link
This doesn't mean anything. It depends on how far away the reading material is from the eye.720p may not be needed for such a small screen but it is better than "not exactly" 720p in that the phone doesn't have to rescale 720p material.
In the same way retina marketing for macbook is pure BS as for the screen size and eye distance from the screen such a high resolution is not needed and will only burn batteries faster and make laptops warmer for next to no visual benefit. In addition 1080p materials will have to be rescaled.
rarson - Thursday, October 18, 2012 - link
Right, so if you have good vision, like I do, then at a foot away, you can see those pixels.MobiusStrip - Friday, October 19, 2012 - link
Yawn.