Making Sense of the Intel Haswell Transactional Synchronization eXtensions
by Johan De Gelas on September 20, 2012 12:15 AM ESTTSX Performance
Ravi and Marting gave some vague but still rather interesting performance data:
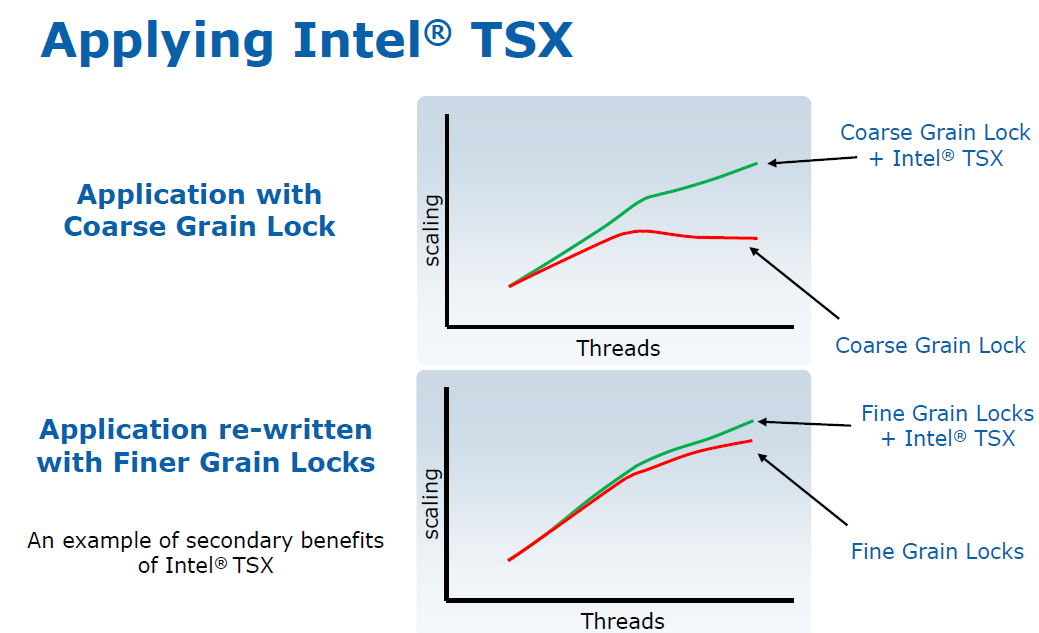
According to Intel, using an application that previously used a coarse grained lock (like the older MyISAM storage engines of MySQL) together with a TSX enabled library should improve scaling spectacularly. What's interesting is that even applications with finely grained locks should benefit from using TSX. As TSX uses the L1-cache to buffer the writes (David Kanter describes this in great detail here) and does not lock (unless re-execute/rollback takes place), there is less memory activity and especially less synchronization traffic. Or in other words, cache lines are less "thrown around".
There are some corner cases for which HLE/RTM will not work of course. The whole "CPU does the fine grained locks" is based upon tagging the L1 (64 B) cachelines and there are 512 of them to be specific (64 x 512 = 32 KB). There is only one "lock tag" per cacheline. More than one lock to the same cacheline will cause HLE/RTM to abort as the CPU cannot track the two locks separately in that case.
Second, all the "to be locked" variables of a TSX enabled piece of code must be placed into the L1-cache. If a piece of critical code needs to lock variables from more than 8 cachelines that all map to the slots of the same set, HLE is not going to work: the L1 is 8-way set-associative. Anything that interrupts the transaction will abort the transaction: non-maskable interrupts (interrupts that cannot be ignored), VM exits, faults...the list goes on. Still, there are many cases where TSX can definitely help, and code can be written to accommodate the requirements and limitations.
Conclusion
TSX will be supported by GCC v4.8, Microsoft's latest Visual Studio 2012, and of course Intel's C compiler v13. GLIBC support (rtm-2.17 branch) is also available. So it looks like the software ecosystem is ready for TSX. The coolest thing about TSX (especially HLE) is that it enables good scaling on our current multi-core CPUs without an enormous investment of time in the fine tuning of locks. In other words, it can give developers "fined grained performance at coarse grained effort" as Intel likes to put it.
In theory, most application developers will not even have to change their code besides linking to a TSX enabled library. Time will tell if unlocking good multi-core scaling will be that easy in most cases. If everything goes according to Intel's plan, TSX could enable a much wider variety of software to take advantage of the steadily increasing core counts inside our servers, desktops, and portables.








29 Comments
View All Comments
Paul Tarnowski - Thursday, September 20, 2012 - link
So it's good that the locking is finally being addressed at the CPU level, but that just means that even fewer developers will bother using fine-grain locking.Which isn't necessarily a bad thing, because they will be able to either spend the time and money on something else, or save, but it does mean that their software will be less efficient on older CPUs. Which in turn means that unless AMD comes up with a similar system that achieves the same effect, they will be even more behind. In the short term, of course, this just means that Haswell might improve any multi-threaded program that has been recompiled using the updated libraries.
The one thing that does make me hesitant is that it works on only one chacheline at a time, as well as all the abort conditions. That makes me think that the graph shown is a best-case scenario, and actual improvements in real world scenarios would be far less.
anubis44 - Thursday, September 20, 2012 - link
AMD and Intel have cross-licensing agreements for instructions each of them come up with. That's why Intel can build AMDx64 compatible CPUs (AMD designed the 64 bit extensions we're all using in both AMD and Intel CPUs) and AMD has SSE instructions. This is an automatic thing, so no further agreements need to be made. You can bet these instructions will show up in the next generation of AMD CPUs after Intel releases them.Brutalizer - Saturday, September 22, 2012 - link
Sun built Transactional Memory years ago with their SPARC ROCK cpu, to be used in the new SuperNova Solaris servers. But for various reasons ROCK was killed (I heard that it used too much wattage, among other problems).The good news is that ROCK research is not wasted, most of it is used in newer products. The new coming SPARC T5 to be released this year, has Transactional Memory. It will probably be the first sold cpu that offers TM.
HibyPrime1 - Thursday, September 20, 2012 - link
I don't really understand why this has to be implemented in hardware.Can't a developer just write the programming assuming the threads wont interfere with each other? After doing that, the program does a simple check to see if something went wrong, and if it did, it falls back to coarse grained locking.
I'm not sure how this is supposed to make it significantly easier for the developers. I'm sure that I'm missing something, but doesn't TSX just mean the developer doesn't have to write code that checks to see if something got broken? seems to me that part would be the easiest part of all this locking coding...
twotwotwo - Thursday, September 20, 2012 - link
The short answer is, an approach like that kind of *does* exist (search for optimistic concurrency control), but it still takes work to detect when things went wrong and be able to clean up.In Intel's bank example, you might need some kind of indexed concurrency-proof transaction history so the bank can know that when I gave $50 to Alice and $60 to Bob, both transactions used a $100 starting balance. And the code needs to know how to undo a transaction that collided with another. To complicate things, many live systems deal with larger transactions than just two-person money transfers like Intel's example. Optimistic control can still be a step up from spinlocks (or people would never use it) but it doesn't come for free.
Tuna-Fish - Thursday, September 20, 2012 - link
Transactional memory can, and has been, implemented in software. The typical examples are Clojure and Haskell. However, doing the tracking in software generally takes a lot of resources, especially because you have to deal with all kinds of race conditions. Remember that without some kind of hardware support for concurrency, every single write and read operation is independent, and something could go wrong at any point, including during the verify/restore phase.name99 - Friday, September 21, 2012 - link
This is not a technology to make parallel programming automatic or even easier. It is a technology to make ONE PART of parallel programming, namely the locking MORE EFFICIENT. That is all.This has the consequence that one can write an app using fewer, coarser grained locks, and have it perform as well as if you'd used finer grained locked, but again, that is all. In particular
- it doesn't do the locking for you, it doesn't tell you what needs to be protected by locks, it doesn't catch stupid usage of locks, etc etc
- it doesn't help with everything else related to parallel programming, from choosing appropriate data structures to choosing appropriate algorithms.
As for doing it in SW, well, yes, at the end of the day you can do EVERYTHING in software. But Intel is in the business of moving as much as possible of what is slow in software into faster hardware. That's why we have everything from branch prediction to AES instructions to QuickSync in modern CPUs.
Finally, it's foolish to obsess too much about implementation details, like how the L1 cache is used. EVERYTHING in HW is a tradeoff and, just like you can invent some pathological code that runs slower under branch prediction, you can invent pathological code that runs slower under this implementation of the locking mechanism. As always, Intel will look at how these extensions are used in practice, and how they fail, and will modify how they are implemented as a result. This is just common sense.
softdrinkviking - Monday, September 24, 2012 - link
hmm. so would you say that recent generation Intel CPUs are well utilized? All of the instructions and features not only make sense, but are well utilized by a majority of developers?epobirs - Thursday, September 27, 2012 - link
That depends on what you consider an acceptable time scale for widespread usage of a hardware feature. Everything has to start somewhere. Nobody today would bother to mention that their software takes advantage of MMX and its successors but at one time it carried some novelty value. The real benefits came when it was so common in the hardware and compiler support that it no longer merited mention.epobirs - Thursday, September 27, 2012 - link
For the traditional reason you create any dedicated function in hardware: performance. Intel is betting this is going to matter hugely to scaling up the value of multi-core processors.Such things have a long history. MMX was the result of examing many, many pieces of of software and looking for functions then done entirely in software on most systems that could be accelerated for a minimal investment in transistor real estate.
There was a period of a few years when a 3D accelerator board was a separate item from the video board. The 3Dfx Voodoo series worked this way for several generations until the company faltered in trying to transition to complete video solutions on a single board. In that time 3D had gone from something exclusively of interest to gamers and some other specialty apps to a thing expected of every system to some extent. It wasn't long before integrated graphics adapters had the kind of 3D performance that formerly lead people to make a costly separate purchase to obtain.
If something is worth putting in the hardware, it will reveal itself through what is done in the software. From there it is only a question of how many transistors does it take to embody and at what cost? If the numbers are right, into the hardware it goes.