Bulldozer for Servers: Testing AMD's "Interlagos" Opteron 6200 Series
by Johan De Gelas on November 15, 2011 5:09 PM ESTMeasuring Real-World Power Consumption, Part One
The Equal Workload (EWL) version of vApus FOS is very similar to our previous vApus Mark II "Real-world Power" test. To create a real-world “equal workload” scenario, we throttle the number of users in each VM to a point where you typically get somewhere between 20% and 80% CPU load on a modern dual CPU server. The amount of requests is the same for each system, hence "equal workload".
The CPU Load on the Opteron 6276 looked like this:
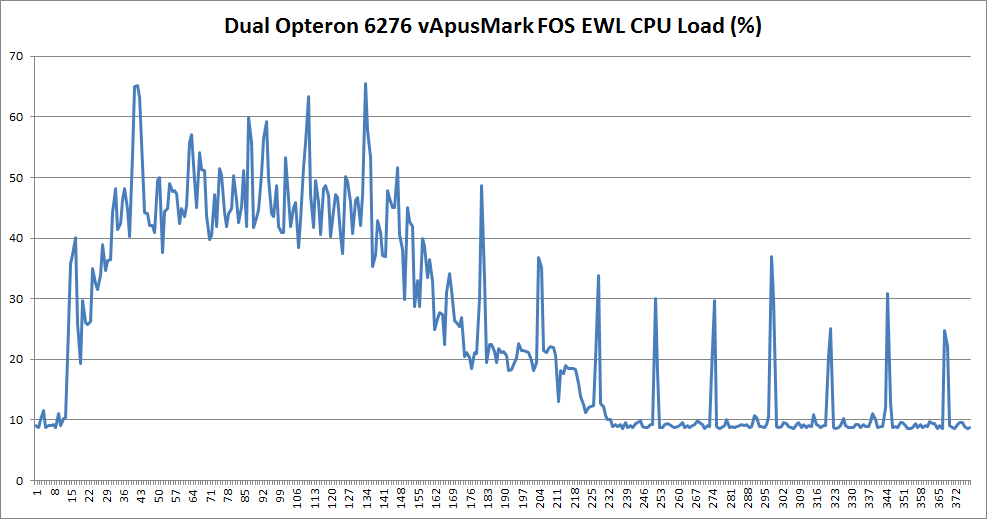
The CPU load is typically around 30-50%, with peaks up to 65%. At the end of the test, we get to a low 10%, which is ideal for the machine to boost to higher CPU clocks (Turbo) and race to idle. First we check out the response times.
| vApus FOS Response times (ms) | ||||||||
| CPU | PhpBB1 | PHPBB2 | MySQL OLAP | Zimbra | ||||
| AMD Opteron 6276 | 134 | 47 | 3.6 | 44 | ||||
| AMD Opteron 6174 | 118 | 41 | 3.8 | 45 | ||||
| Intel Xeon X5670 | 76 | 27 | 2.2 | 28 | ||||
ESXi and our Interlagos "Opteron" probably don't understand each other fully, given the newness of the architecture. Some extensive monitoring with ESXtop shows that the lower CPU load is spread among all the cores, and the result is that the Opteron 6276 never reaches its highest clock speed (3.2GHz). That helps make the response times significantly higher than on the Xeon, although they are acceptable. Again, the Interlagos Opteron fails to really beat the "Magny-cours" Opteron.
Our main focus of this benchmark is of course energy consumption.
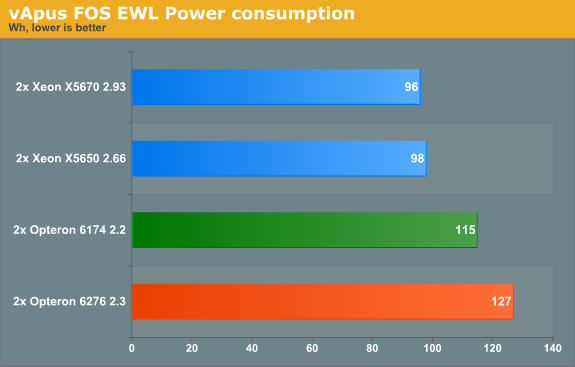
The Xeon consumes 25% less power, and the older Opteron about 10% less. The performance/Watt ratio of the newest Opteron looks rather bad when running on top of ESX. We shall delve into this deeper in the next several pages.








106 Comments
View All Comments
DigitalFreak - Tuesday, November 15, 2011 - link
Good to see that CPU-Z correctly reports the 6276 as 8 core, 16 thread, instead of falling for AMD's marketing BS.N4g4rok - Tuesday, November 15, 2011 - link
If each module possess two integer cores to a shared floating point core, what's to say that it can't be considered as a practical 16 core?phoenix_rizzen - Tuesday, November 15, 2011 - link
Each module includes 2x integer cores, correct. But the floating point core is "shared-separate", meaning it an be used as two separate 128-bit FPUs or as a single 256 FPU.Thus, each Bulldozer module can run either 3 or 4 threads simultaneously:
- 2x integer + 2x 128-bit FP threads, or
- 2x integer + 1x 256-bit FP threads
It's definitely a dual-core module. It's just that the number of threads it can run is flexible.
The thing to remember, though, is that these are separate hardware pipelines, not mickey-moused hyperthreaded pipelines.
JohanAnandtech - Tuesday, November 15, 2011 - link
You can get into a long discussion about that. The way that I see it, is that part of the core is "logical/virtual", the other part is real in Bulldozer . What is the difference between an SMT thread and CMT thread when they enter the fetch-decode stages? Nothing AFAIK, both instructions are interleaved, and they both have a "thread tag".The difference is when they are scheduled, the instructions enters a real core with only one context in the CMT Bulldozer. With SMT, the instructions enter a real core which still interleave two logical contexts. So the core still consists of two logical cores.
It is gets even more complicated when look at the FP "cores". AFAIK, the FP cores of Interlagos are nothing more than 8 SMT enabled cores.
alpha754293 - Tuesday, November 15, 2011 - link
I think that Johan is partially correct.The way I see it, the FPU on the Interlagos is this:
It's really a 256-bit wide FPU.
It can't really QUITE separate the ONE physical FPUs into two 128-bit wide FPUs, but it more probably in reality, interleaves them (which is really just code for "FPU-starved").
Intel's original HTT had this as a MAJOR problem, because the test back then can range from -30% to +30% performance increase. Floating-point intensive benchmarks have ALWAYS suffered mostly because suppose you're writing a calculator using ONLY 8-byte (64-bit) double precision.
NORMALLY, that should mean that you should be able to crunch through four DWORDs at the same time. And that's kinda/sorta true.
Now, if you are running two programs, really...I don't think that the CPU, the compiler (well..maybe), the OS, or the program knows that it needs to compile for 128-bit-wide FPUs if you're going to run two instances or two (different) calculators.
So it's resource starved in trying to do the calculation processes at the same time.
For non-FPU-heavy workloads, you can get away with that. For pretty much the entire scientific/math/engineering (SME) community; it's an 8-core processor or a highly crippled 16-core processor.
Intel's latest HTT seems to have addressed a lot of that, and in practical terms, you can see upwards of 30% performance advantage even with FPU-heavy workloads.
So in some cases, the definition of core depends on what you're going to be doing with it. For SME/HPC; it's good cuz it can do 12-actual-cores worth of work with 8 FPUs (33% more efficient), but sucks because unless they come out with a 32-thread/16-core monolithic die; as stated, it's only marginally better than the last. It's just cheaper. And going to get incrementally faster with higher clock speeds.
alpha754293 - Tuesday, November 15, 2011 - link
P.S. Also, like Anand's article about nVidia Optimus:Context switching even at the CPU level, while faster, is still costly. Perhaps maybe not nearly as costly as shuffling data around; but it's still pretty costly.
Samus - Wednesday, November 16, 2011 - link
Ouch, this is going to be AMD's Itanium. That is, it has architecture adoption problems that people simply won't build around. Maybe less substantial than IA64, but still a huge performance loss because of underutilized integer units.leexgx - Wednesday, November 16, 2011 - link
think they way CPU-z reporting it for BD cpus is correct each core has 2 FP, so 8 cores and 16 threads is correctto bad windows does not understand how to spread the load correctly on an amd cpu (windows 7 with HT cpus Intel works fine, spreads the load correctly, SP1 improves that more but for Intel cpus only)
windows 7 sp1 makes biger use of core parking and gives better cpu use on Intel cpus as i have been seeing on 3 systems most work loads now stay on the first 2 cores and the other 2 stay parked, on amd side its still broke with cool and quite enabled
Stuka87 - Tuesday, November 15, 2011 - link
So, what is your definition of a core?Bulldozers do not utilize hyper threading, which takes a single integer core and can at times put two threads into that single integer core. A Bulldozer core has actual hardware two run two threads at the same time. This would suggest there are two physical cores.
Does it perform like an intel 16 core (if there was such a thing), no. But that does not mean that it is not in fact a 16 core device. As the hardware is there. Yes they share an FPU, but that doesn't mean they are not cores.
Filiprino - Tuesday, November 15, 2011 - link
Actually, Bulldozer is 16 cores. It has two dedicated integer units and a float point unit which can act as two 128 bit units or one 256 bit unit for AVX. So, you can have 2 and 2 per module.Bulldozer does not use hyperthreading.