Intel's Sandy Bridge Architecture Exposed
by Anand Lal Shimpi on September 14, 2010 4:10 AM EST- Posted in
- CPUs
- Intel
- Sandy Bridge
The Ring Bus
With Nehalem/Westmere all cores, whether dual, quad or six of them, had their own private path to the last level (L3) cache. That’s roughly 1000 wires per core. The problem with this approach is that it doesn’t work well as you scale up in things that need access to the L3 cache.
Sandy Bridge adds a GPU and video transcoding engine on-die that share the L3 cache. Rather than laying out another 2000 wires to the L3 cache Intel introduced a ring bus.
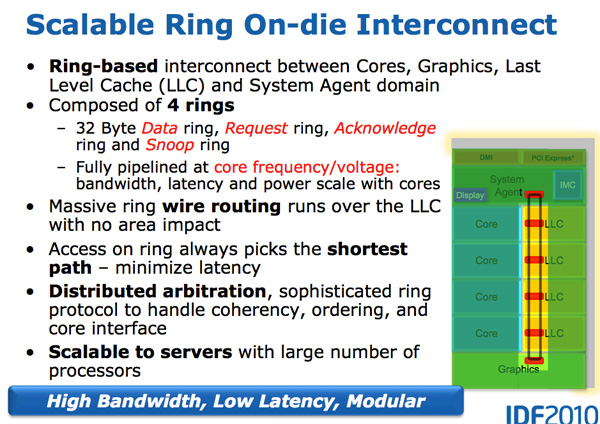
Architecturally, this is the same ring bus used in Nehalem EX and Westmere EX. Each core, each slice of L3 (LLC) cache, the on-die GPU, media engine and the system agent (fancy word for North Bridge) all have a stop on the ring bus.
The bus is made up of four independent rings: a data ring, request ring, acknowledge ring and snoop ring. Each stop for each ring can accept 32-bytes of data per clock. As you increase core count and cache size, your cache bandwidth increases accordingly.
Per core you get the same amount of L3 cache bandwidth as in high end Westmere parts - 96GB/s. Aggregate bandwidth is 4x that in a quad-core system since you get a ring stop per core (384GB/s).
L3 latency is significantly reduced from around 36 cycles in Westmere to 26 - 31 cycles in Sandy Bridge. We saw this in our Sandy Bridge preview and now have absolute numbers in hand. The variable cache latency has to do with what core is accessing what slice of cache.
Also unlike Westmere, the L3 cache now runs at the core clock speed - the concept of the un-core still exists but Intel calls it the “system agent” instead and it no longer includes the L3 cache.
With the L3 cache running at the core clock you get the benefit of a much faster cache. The downside is the L3 underclocks itself in tandem with the processor cores. If the GPU needs the L3 while the CPUs are downclocked, the L3 cache won’t be running as fast as it could had it been independent.
The L3 cache is divided into slices, one associated with each core although each core can address the entire cache. Each slice gets its own stop and each slice has a full cache pipeline. In Westmere there was a single cache pipeline and queue that all cores forwarded requests to, in Sandy Bridge it’s distributed per cache slice.
The ring wire routing runs entirely over the L3 cache with no die area impact. This is particularly important as you effectively get more cache bandwidth without any increase in die area. It also allows Intel to scale the core count and cache size without incurring additional ring-related die area.
Each of the consumers/producers on the ring get their own stop. The ring always takes the shortest path. Bus arbitration is distributed on the ring, each stop knows if there’s an empty slot on the ring one clock before.
The System Agent
For some reason Intel stopped using the term un-core, instead in Sandy Bridge it’s called the System Agent.
The System Agent houses the traditional North Bridge. You get a 16 PCIe 2.0 lanes that can be split into two x8s. There’s a redesigned dual-channel DDR3 memory controller that finally restores memory latency to around Lynnfield levels (Clarkdale moved the memory controller off the CPU die and onto the GPU).
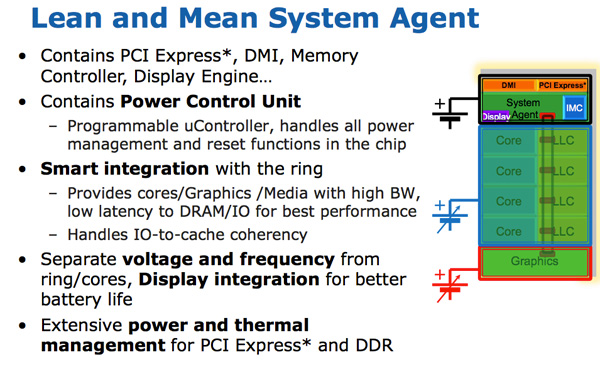
The SA also has the DMI interface, display engine and the PCU (Power Control Unit). The SA clock speed is lower than the rest of the core and it is on its own power plane.








62 Comments
View All Comments
beginner99 - Tuesday, September 14, 2010 - link
AMD's been taking about fusion forever but I can't get rid of the feeling that this Intel implementation will be much more "fused" than the AMD one will be. AMD barley has CPU turbo so adding a comined cpu/gpu turbo at once, maybe they can pull it off but experience makes me doubt that very much.BTW, if it takes like 3mm^2 for a super fast video encoder I ask my self, why wasn't this done before?
duploxxx - Tuesday, September 14, 2010 - link
first or not, doesn't really matter.who says AMD need's GPU turbo? If Liano really is a 400SP GPU it will knock any Intel GPU with or without turbo.
If we see the first results of Anadtech review which seems to be a GT2 part it doesn't have a chance at all.
core i5 is really castrated due to lack of HT, This is exactly where liano will fight against, with a bit less cpu power.
B3an - Tuesday, September 14, 2010 - link
Even if AMD's GPU in Liano is faster, intels GPU is finally decent and good enough for most people, but more importantly more people will care about CPU performance because most users dont play games and this GPU can more than easily handle HD video. And i'm sure SB will be faster than anything AMD has. Then throw in the AVX and i'd say Intel clearly have a better option for the vast majority of people, it just comes down to price now.B3an - Tuesday, September 14, 2010 - link
Sorry, didnt mean AVX, i meant the hardware accelerated video encoding.bitcrazed - Tuesday, September 14, 2010 - link
But it's not just about raw power - it's about power per dollar.If you've got $500 to spend on a mobo and CPU, where do you spend it? On a slower Intel platform or on a faster AMD platform?
If AMD get their pricing right, they could turn this into a no-brainer decision, greatly increasing their sales.
duploxxx - Tuesday, September 14, 2010 - link
now here comes the issue with the real fanboys:"And i'm sure SB will be faster than anything AMD has."
It's exactly price where AMD has the better option. It's people " known brand name" that keeps them at buying the same thing without knowledge... yeah lets buy a Pentium.
takeulo - Wednesday, September 15, 2010 - link
hahahahah yeah i agree AMD is the better option at all if i have the high budget i'll go for Insane i mean Intel but since im only "poor" and i cant afford it so i'll stick to AMD and my money worth itsorry for my bad english XD
MySchizoBuddy - Monday, December 20, 2010 - link
how do you know Intel GPU has reached good enough state (do you have benchmarks to support your hypothesis). they have been trying to reach this state for as long as i can remember.your good enough state might be very different that somebodies else's good enough state.
bindesh - Tuesday, September 20, 2011 - link
Your all doubts will be cleared after watching this video, and related once.http://www.youtube.com/watch?v=XqBk0uHrxII&fea...
I am having 3 AMDs and 1 Intel, Believe me with the price of AMD CPUs, i can only get a celeron in Intel. Which cannot run NFS SHIFT. Or TIme Shift. But other hand, with AMD athlon, i have completed Devil May Cry 4 with decent speed. And the laptop costs 24K, Toshiba C650, psg xxxxx18 model. It has 360 GB SSD, ATI 4200HD.
Can you get such price and performance with Intel?
Best part is that i am running it with 800MHz cpu speed, with performance much much greater than 55K intel dual core laptop of my friend.
vlado08 - Tuesday, September 14, 2010 - link
Still no word ont the 23.976 FPS play back?