NVIDIA’s GeForce GTX 460: The $200 King
by Ryan Smith on July 11, 2010 11:54 PM EST- Posted in
- GPUs
- GeForce GTX 400
- GeForce GTX 460
- NVIDIA
GF104: NVIDIA Goes Superscalar
When the complete GF100 GPU was presented to us back at CES 2010 in January, NVIDIA laid out a design that in turn had a very obvious roadmap to go with it. With GF100’s modular design, derivatives of the card would be as simple as fabricating GPUs with fewer GPCs and ROPs (at least until you got to the sub-$100 market). This is the route we expected NVIDIA to take with GF104, removing 1 or 2 GPCs to make a smaller chip.
What they threw us instead was a curveball we were not expecting.
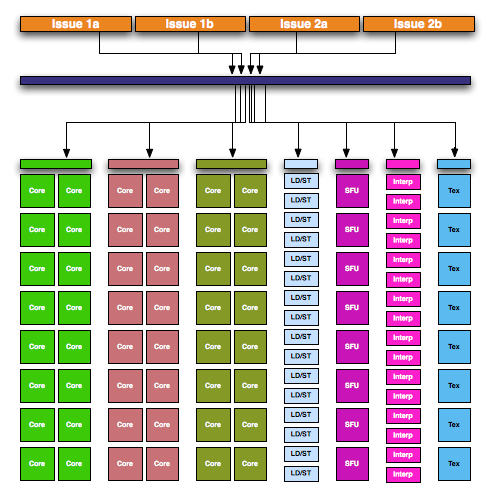
Let’s start at a high level. On GF100, there were 4 GPCs each containing a Raster Engine and 4 SMs. In turn each SM contained 32 CUDA cores, 16 load/store units, 4 special function units, 4 texture units, 2 warp schedulers with 1 dispatch unit each, 1 Polymorph unit (containing NVIDIA’s tessellator) and then the L1 cache, registers, and other glue that brought an SM together.
NVIDIA GF100 - Full Implementation, No Disabled Logic

GF104 in turn contains 2 GPCs, which are effectively the same as a GF100 GPC. Each GPC contains 4 SMs and a Raster Engine. However when we get to GF104’s SMs, we find something that has all the same parts as a GF100 SM, but in much different numbers.
NVIDIA GF104 - Full Implementation, No Disabled Logic

The biggest and most visible change is that NVIDIA beefed up the number of various execution units per SM. The 32 CUDA cores from GF100 are now 48 CUDA cores, while the number of SFUs went from 4 to 8 along with the texture units. As a result, per SM GF104 has more compute and more texturing power than a GF100 SM. This is how a “full” GF104 GPU has 384 CUDA cores even though it only has half the number of SMs as GF100.
One thing we haven’t discussed up until now is how an SM is internally divided up for the purposes of executing instructions. Since the introduction of G80 in 2006, the size of a warp has stayed constant at 32 threads wide. For Fermi, a warp is executed over 2 (or more) clocks of the CUDA cores – 16 threads are processed and then the other 16 threads in that warp are processed. For full SM utilization, all threads must be running the same instruction at the same time. For these reasons a SM is internally divided up in to a number of execution units that a single dispatch unit can dispatch work to:
- 16 CUDA cores (#1)
- 16 CUDA cores (#2)
- 16 Load/Store Units
- 16 Interpolation SFUs (not on NVIDIA's diagrams)
- 4 Special Function SFUs
- 4 Texture Units
With 2 warp scheduler/dispatch unit pairs in each SM, GF100 can utilize at most 2 of 6 execution units at any given time. It’s also because of the SM being divided up like this that it was possible for NVIDIA to add to it. GF104 in comparison has the following:
- 16 CUDA cores (#1)
- 16 CUDA cores (#2)
- 16 CUDA cores (#3)
- 16 Load/Store Units
- 16 Interpolation SFUs (not on NVIDIA's diagrams)
- 8 Special Function SFUs
- 8 Texture Units
This gives GF104 a total of 7 execution units, the core of which are the 3 blocks of 16 CUDA cores.
GF104 Execution Units
With 2 warp schedulers, GF100 could put all 32 CUDA cores to use if it had 2 warps where both required the use of CUDA cores. With GF104 this gets more complex since there are now 3 blocks of CUDA cores but still only 2 warp schedulers. So how does NVIDIA feed 3 blocks of CUDA cores with only 2 warp schedulers? They go superscalar.
In a nutshell, superscalar execution is a method of extracting Instruction Level Parallelism from a thread. If the next instruction in a thread is not dependent on the previous instruction, it can be issued to an execution unit for completion at the same time as the instruction preceding it. There are several ways to extract ILP from a workload, with superscalar operation being something that modern CPUs have used as far back as the original Pentium to improve performance. For NVIDIA however this is new – they were previously unable to use ILP and instead focused on Thread Level Parallelism (TLP) to ensure that there were enough warps to keep a GPU occupied.
NVIDIA GF100 SM
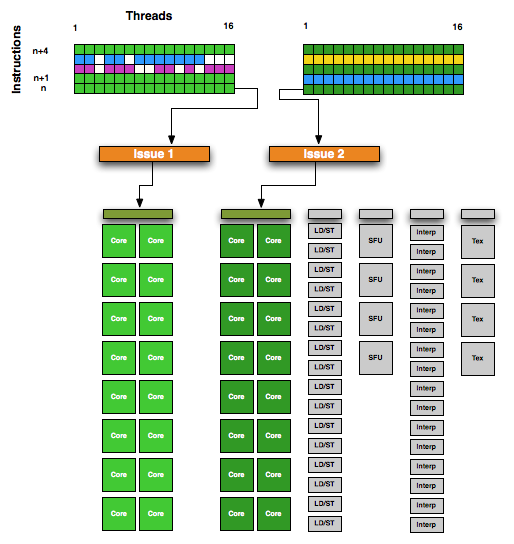
In order to facilitate superscalar operation, NVIDIA made some changes to both the warp scheduler and the dispatch unit for GF104. Each warp scheduler is now connected to 2 dispatch units, giving it the ability to dual-issue instructions. Along with its regular duties, a warp scheduler is now responsible for organizing its superscalar operation by analyzing the next instruction in its warp to determine if that instruction is ILP-safe, and whether there is an execution unit available to handle it. The result is that NVIDIA’s SMs now handle superscalar operation similar to that of a CPU, with the hardware taking the responsibility for dispatching parallel instructions. This in turn means that GF104 can execute a warp in a superscalar fashion for any code and including old CUDA code, allowing it to extract ILP out of old and new code alike. The GF104 compiler in NVIDIA’s drivers will try to organize code to better match GF104’s superscalar abilities, but it’s not critical to the ability.
NVIDIA GF104 SM - Note, more instructions in flight per SM vs. GF100
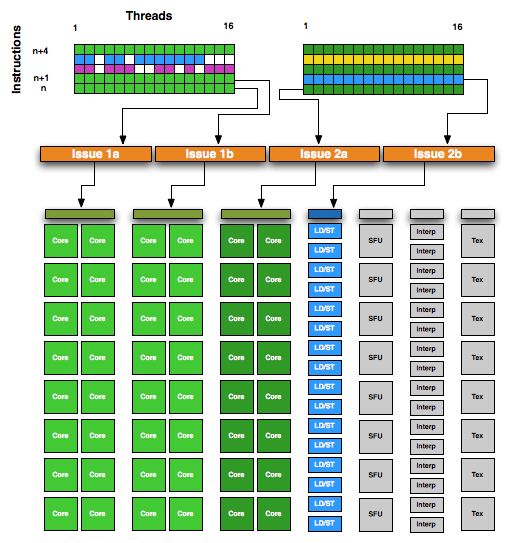
Ultimately superscalar execution serves 2 purposes on GF104: to allow it to issue instructions to the 3rd CUDA core block with only 2 warps in flight, and to improve overall efficiency. In a best-case scenario GF104 can utilize 4 of 7 execution units, while GF100 could only utilize 2 of 6 execution units.
The upside to this is that on average GF104 should be more efficient per clock than GF100, which is quite a remarkable feat. The downside to this is that now NVIDIA has a greater degree of best and worst case scenarios, as requiring superscalar execution to utilize the 3rd CUDA core block means that it’s harder to use that 3rd block than the previous 2. The ability to extract ILP from a warp will result in GF104’s compute abilities performing like a 384 CUDA core part some of the time, and like a 256 CUDA core part at other times. It will be less consistent, but on average faster than a pure 256 CUDA core part would be.
With the addition of superscalar abilities, GF104 marks the slow-but-steady merger of the CPU and the GPU. GF104 is now just a bit more CPU-like than GF100 was, a particularly interesting turn of events since we’re looking at a waterfall part and not a new architecture today.








93 Comments
View All Comments
san1s - Monday, July 12, 2010 - link
I hope this is the card that finally brings price drops, they have been stagnant for far too long.JGabriel - Monday, July 12, 2010 - link
It should. The 768MB version seems to perform about 5% better than the 5830, and the 1GB version comes to ~90% of the 5850.
Just on a performance per dollar basis, that means ATI should drop the 5830 to $189 max, with somewhere in the $170-$180 range being more reasonable, and the 5850 needs to drop down to about $249. Basically, we should be looking at 10%-20% price cuts for the 5670, 5750, 5770, 5830, and 5850.
It should force the GTX 470 under $300, too.
.
medi01 - Monday, July 12, 2010 - link
Best way to drop prices would be to ramp up production. Now, if what I've heard is true (fab treats nVidia as a preferred customer, unlike AMD) we will get yet another round of unfair competition, which in the end will hurt us, customers. :(PS
Is it me, or articles on this side seem quite a bit to be more positive on what nVidia does, than what would feel neutral? Marketing hints like "it’s not a simple reduced version of GF100 like what AMD did" all over... :(
jonup - Monday, July 12, 2010 - link
It is you! Only need to go to the GTX465 review to disptove your point.teohhanhui - Monday, July 12, 2010 - link
Giving credit where it is due?nafhan - Monday, July 12, 2010 - link
Ryan said that because the GF104 isn't a simple reduced version of GF100. Did you notice the part of the article where they talked about superscalar processing? That's not only a marketing bullet point, it's a pretty big change from an architecture point of view, too!medi01 - Tuesday, July 13, 2010 - link
And this detail brings what particular benefit to the user? In particular, contrasting it with competitors (otherwise superior, cooler and faster) solution? Someone makes something wrong, then he has to rework it (the competitor, that did it right from the beginning, doesn't) and this somehow makes he deserve "some credit"?Ben90 - Monday, July 12, 2010 - link
About that "marketing" comment about not a shrink of GF100, its completely true and how does that make this site pro-NVIDIA?You should check out the next article; very first paragraph:
"In 2007 we reviewed NVIDIA’s GeForce 8800 GT. At the time we didn’t know it would be the last NVIDIA GPU we would outright recommend at launch."
medi01 - Tuesday, July 13, 2010 - link
It's completely true, yet it is confusing at best. Piece of silicon is "praised" for something, that has no practical value to the consumer.And please, don't compare nVidia article to nVidia article, compare it to AMD:
When 5830 was reviewed, and mind you, it's a nice card that runs cooler, has eyefinity, but is a tad slower than older 49xx, this fact was PUT INTO TITLE, mind you. It was mentioned in the very NAME of the article, that new 200$ card is a tad slower than older ones. (basically the only "bad thing" that one could say about the card)
In case of 465 it's barely mentioned "oh, it's slower than older 200$ cards".
=(
Lonyo - Tuesday, July 13, 2010 - link
Anandtech is a tech site that often goes more into the under the hood bits.On some sites you will see them calculating performance per currency numbers, or performance per watt.
On Anandtech you will have them discussing things like changes to the architecture, the way the threading works etc.
That's not a new thing, and it's not a biased thing, that's just what they do here at AT in their reviews. It just so happens that the GTX460 has some of those under the hood changes compared to the earlier cards based on the same architecture, so they are discussed in the article.
If you don't care too much about that sort of thing, you can just skip to the benchmarks. If you are interested in it, then it's a nice addition.