Lucid's Multi-GPU Wonder: More Information on the Hydra 100
by Derek Wilson on August 22, 2008 4:00 PM EST- Posted in
- GPUs
What Does This Thing Actually Do?From a high level, Lucid's technology intercepts DirectX or OpenGL API calls, analyzes them, organizes them into distinct tasks, and based on the analysis combined with the historical performance of various cards handling of previous frames' workload, it evenly distributes the tasks across all the GPUs in the system.
After the workload is distributed, the buffers are read back to the Hydra chip and composited before the final scene is sent to the proper graphics card for display. Looking a bit deeper, here is a block diagram of the process itself from Lucid's whitepaper.
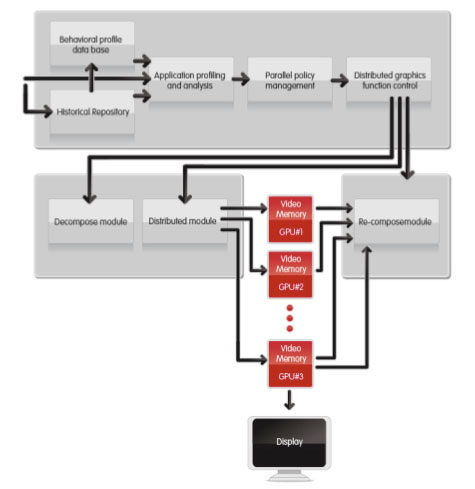
The current implementation can take x16 PCIe in and can switch it to either 2x x16 PCIe channels or up to 4x x16 PCIe channels. This gives it support for 1 to 4 cards depending on how the motherboard or graphics card handles things. They do have the flexibility to scale down to x8 in and 2x x8 out, making lower cost motherboards feasible as well. Future products may support more graphics cards and more PCIe lanes, but right now 4 is what makes sense. Lucid says the hardware can scale up to any number of cards with linear performance improvement.
Some of the implications of this process are that if any graphics card in the system has other work being done on it (say maybe physics or video or something), the load will be dynamically balanced and you'll still be able to squeeze as much juice out of all the hardware in your system as possible. Pretty cool huh? If it works as advertised that is.
The demo we saw behind closed doors with Lucid did show a video playing on one 9800 GT while the combination of it and one other 9800 GT worked together to run Crysis DX9 with the highest possible settings at 40-60 fps (in game) with a resolution of 1920x1200. Since I've not tested Crysis DX9 mode on 9800 GT I have no idea how good this is, but it at least sounds nice.
Since Lucid is analyzing the data, they can even do things like not draw hidden "tasks" (if an entire object is occluded, rather than send it to a graphics card, it just doesn't send it down). I asked about dependent texturing and shader modification of depth, and apparently they also build something like a dependency graph and if something modified affects something else they are able to adjust that on the fly as well.
In theory, tracking and adjusting to dependencies on the fly will completely avoid the issues that keep NVIDIA and AMD from running AFR in all games. And they even claim that this can help give you higher than linear scaling when using their hardware with more than one card.
We asked what the latency of their implementation is, and they said it is negligible. Of course, that's not a real answer, especially for guys like us who want to know the details so we can understand what's going on better. We don't just want to see the end result, we want to know how we get there. Playing Crysis didn't feel laggy, but there is no way this solution doesn't introduce processing time.
An explanation for this is the fact that the Hydra software can keep requesting and queuing up tasks beyond what graphics cards could do, so that the CPU is able to keep going and send more graphics API calls than it would normally. This seems like it would introduce more lag to us, but they assured us that the opposite is true. If the Hydra engine speeds things up over all, that's great. But it certainly takes some time to do its processing and we'd love to know what it is.








57 Comments
View All Comments
Spivonious - Monday, August 25, 2008 - link
I don't think nVidia or AMD will try to force Lucid out of the market. If I can actually get a 100% increase in performance from purchasing a second video card, I will.This chip only means more sales for nVidia and AMD.
7Enigma - Tuesday, August 26, 2008 - link
But that doesn't help their bottom line in the end. Right now CF and SLI are not very popular due to their scaling and custom profile issues. Because of that, many people spring for the highest priced single card they can afford. This keeps the market segment basically tiered the way any business would like. You have low end parts, mid-grade, and uber parts.Now throw in the possibility that this Hydra chip works as specified. That 3 tier system just fell apart. When you look at most of the non-mainstream parts from both sides (for example Nvidia's 280, 200, and say 9800/8800GTS), you'll notice that while the price of those chips are drastically different, the performance is not near as different. This makes sense from an R&D standpoint to recoup costs, but from a logical standpoint shelling out $650 for the 280 when it debuted WOULD NOT make sense if 2 200's or 2 9800's was significantly faster for the same or less total $$$.
That's why both ATI/AMD and Nvidia don't want them in the market. It destroys the pricing structure, and would place much more influence on the bang for the buck part (currently this would hurt Nvidia with their 280 and favor slightly ATI/AMD with their cheaper 4870 and 4850).
Why would I spend twice as much for a 30% increase in performance with a top of the line single card solution, when I could just get two of the cheaper version for a near 60% increase over the single top card (using general performance of the latest cards)? Sure I'd need a board to support it, but it would make the SLI/CF mobo's MUCH MUCH more attractive then they currently are (I have no plans to purchase a dual-slot mobo with my upcoming build....unless we can get some actual data before Jan09...not likely).
jnanster - Tuesday, August 26, 2008 - link
This is terrible!I was all set to buy a new system in a few months.
Now I have to wait again, again.
shin0bi272 - Tuesday, August 26, 2008 - link
lol sorry dude... but hey this way you can wait for 8 core nehalem cpus too.TheDoc9 - Monday, August 25, 2008 - link
This article reads like the same sort of hype-machine dribble that many of the dot-com wonder companies used before the 2001 collapse so they could get investors interested.The writer of this piece is fortunately skeptical and he should be, more so even. I hope I'm wrong and we see this technology in a year or so, but it reminds me of Constellation 3D.
shin0bi272 - Sunday, August 24, 2008 - link
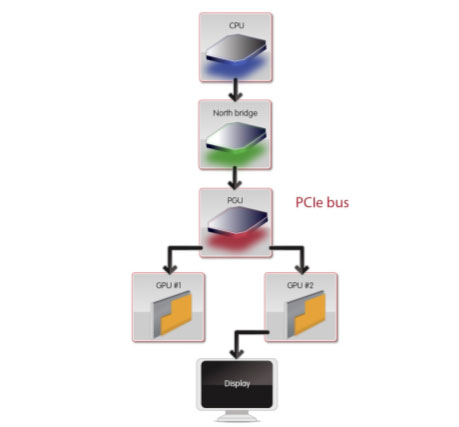
The way they outlined it in one of their diagrams is, an instruction which usually goes from the cpu to the northbridge to the gpus and then the gpu's sort out which card should render the command. The Hydra changes that to, cpu to northbridge to hydra to which ever gpu is ready for a new instruction. Which means its essentially taking the place of the little bridge between the gpus and the chip that makes the decision on which card is rendering the scene.Nvidia and AMD could have put a chip like this on their motherboards yeah but then you wouldn't need to buy 2 of the same card (and it would possibly work for the competitors card too like the hydra does). Nvidia never tried a motherboard chip to my knowledge and ati did at one time do a y cable and software controlled card selection. But I dont believe that they had a chip on the motherboard either. That reminds me of the difference between a software raid5 card and a hardware raid5 card. The hardware raid card has much better performance but it costs 3x as much. Cost could still be a factor with this chip too. I mean if it ads an extra 20 or 50 dollars to a motherboard gamers will have no problem with that. But if its an extra 200 dollars would they? Gotta make back all that R&D money somehow even if Intel backed them.
Another question is will this solution require a multi y-cable type device like ati used to do? If the different cards are rendering the scene at different times it would stand to reason. Or will one card be designated as the output card and all finished scenes be sent to that card? That would probably be a bad idea latency wise but who wants to buy a 4way y-split cable? Then again if im going to get linear performance out of sli I can spring for a cable. Could even make a 4 way hub sort of device so that all of the cards would feed into it and then one into the monitor. Could also do a multi-in and multi-out hub to do multiple monitors (though you might not need to do that it could be easier to add and subtract monitors with one).
computerfarmer - Sunday, August 24, 2008 - link
It is nice to here about new products. I hope to see this work.I am still waiting for the AMD 790GX/SB750 review.
MamiyaOtaru - Sunday, August 24, 2008 - link
What are the odds this will be cross platform? If it relies on drivers for doing a lot of stuff odds are it will not be, which would make it a nonstarter for me. And yes I know close to no one cares ;) I do though and I'd be interested to know.metro15 - Sunday, August 24, 2008 - link
hey. they do not need any motherboard manufacturer. Imagine a Intel Labaree graphic card with many cores synchronized with Lucid chip. The performance would be unbeatable.pool1892 - Sunday, August 24, 2008 - link
larrabee does not need hydra. it will reconfigure itself to suit the load. and with something like larrabee gen2 it will have qpi, which results in much lower latencies and much higher bandwidth.larrabee could even achieve more than linear skaling. (theoretically more cores could result in less context changes, which means more cache hits and less waiting cycles - this will of course not happen in reality)