Nehalem - Everything You Need to Know about Intel's New Architecture
by Anand Lal Shimpi on November 3, 2008 1:00 PM EST- Posted in
- CPUs
New TLBs, Faster Unaligned Cache Accesses
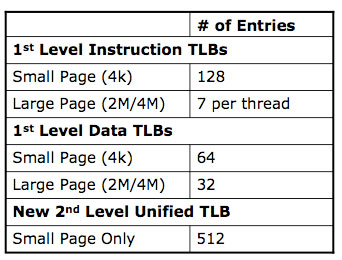
Historically the applications that push a microprocessor’s limits on TLB size and performance are server applications, once again with things like databases. Nehalem not only increases the sizes of its TLBs but also adds a 2nd level unified TLB for both code and data.
Another potentially significant fix that I’ve already talked about before is Nehalem’s faster unaligned cache accesses. The largest size of a SSE memory operation is 16-bytes (128-bits). For any of these load/store operations there are two versions: an op that is aligned on a 16-byte boundary, and an op that is unaligned.
Compilers will use the unaligned operation if they can’t guarantee that a memory access won’t fall on a 16-byte boundary. In all Core 2 processors, the unaligned op was significantly slower than the aligned op, even on aligned data.
The problem is that most compilers couldn’t guarantee that data would be aligned properly and would default to using the unaligned op, even though it would sometimes be used on aligned data.
With Nehalem, Intel has not only reduced the performance penalty of the unaligned op but also made it so that if you use the unaligned op on aligned data, there’s absolutely no performance degradation. Compilers can now always use the unaligned op without any fear of a reduction in performance.
To get around the unaligned data access penalty in previous Core 2 architectures, developers wrote additional code specifically targeted at this problem. Here’s one area where a re-optimization/re-compile would help since on Nehalem they can just go back to using the unaligned op.
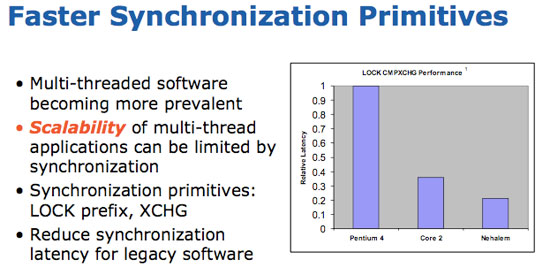
Thread synchronization performance is also improved on Nehalem, which leads us in to the next point.








35 Comments
View All Comments
rflcptr - Wednesday, September 24, 2008 - link
The origin of Turbo Mode isn't Penryn, but rather Intel's DAT first found in the Santa Rosa mobile chipset, of which both Merom and Penryn were compatible (and functioning with the tech activated).hoohoo - Wednesday, September 10, 2008 - link
Outside of games the only area where raw performance matters to me is running high performance code - for me this is graphics processing and 3D rendering code, and it's just a hobby. I have some dealings with the HPC crowd though.In the HPC biz memory bandwidth is a big issue. AMD has won hands down on that metric against Intel until perhaps the past six months. Nehalem server chip looks like it will beat Opteron on this metric.
Another important metric for HPC is linear algebra performance. GPUs are very good at linear algebra, but GPUs have strange programming requirements for the people who understand scientific programming - these people want to worry about the science or engineering and not about the specific cache architecture of an Nvidia or ATI GPU.
Just because I could, last winter I wrote some 2D graphics processing routines for an 8800GT+CUDA+AthlonX2-5200: gaussian blur, sharp filter, the like. I achieved on the order of 20x speed improvement on the 8800GT vs the AthlonX2 all on Linux - but it was a moderately brutal programming experience and I doubt your average researcher will do it. And, well, the PCIe bandwidth bottleneck would be a problem for large scale batch processing for such a simple calculation.
I don't know about ATI GPUs yet. I got a 3870 eight months ago and installed the AMD HPC GPU SDK ('nuff acromyms for ya?), but I can't face the pain of using it if after booting all the way into XP I could be fragging away in HL2 or Q4, or conquering the world in Civ2 Gold instead - and nobody really uses Windows servers for HPC clusters anyway. I think about write Brook+ code on my 3870 sometimes but honestly I don't care that much. It'll be similar performance to the 8800, and it'll be *Windows* code.
If Intel can produce a chip that is somewhere between Larabee and Nehalem, matching memory bandwidth with an easily programmed but highly parallel chip then Intel will have an opportunity to define a new sub-market: HPC processors.
It is indicative of the deficiencies of AMD marketing that it has a good GPGPU and the only way to program it is on the one OS that HPC shies away from: Windows. Clusters mostly run on Linux or UNIX.
But, AMD is working on a CPU+GPU product that could compete in that market.
Which of AMD or Intel will realize that there is money to be made with a chip that combines 2 or 4 CPU cores + 4 or 8 GPU style linear algebra cores, all with IEEE double precision ability?
Whither the Cell?
:-)
hooflung - Monday, November 3, 2008 - link
I think you are minimizing what an operating system is. While it is true that Linux, AIX and Solaris account for a large number of HPC and cluster environments that doesn't mean Windows is poor in this regard.There are solid options for windows HPC where infiniband is very, very solid. Microsoft helped define the spec. However, it isn't done often enough in the public's eye like Linux. Remember, AIX and Windows were the most solid platforms for J2EE for a long, long time.
Also, Windows Clusters can be the better TCO solution for people. EVE-Online used Windows 2000 (now 2003 x86 and x64 ) and wrote their own load balancing software in Stackless ( and now have their own async IO stackless library ) which holds 33k at any given time of the day.
You really just have to decide what market you are trying to reach when considering OS choices. They all can provide similar performance.
Pixy - Friday, September 5, 2008 - link
All this sounds nice... but I have a question: when will laptops become fanless? The CPU is fast enough, work on turning down the heat!Davinchy - Tuesday, August 26, 2008 - link
I thought I read somewhere that if the other processor cores where not working then they shut down and the one that was working got more juice and overclocked.. So wouldn't that suggest that for the average consumer This chip will game much faster than a penryn?Dunno Maybe I read it wrong
jediknight - Sunday, August 24, 2008 - link
For desktop builders.My aging S754 Athlon64 is dying.. so it's time to start thinking of building a new one. My laptop can only hold me out for so long, though..
Will I be able to buy a quad-core Nehalem processor in about the $250-300 range by the end of the year?
UnlimitedInternets36 - Saturday, August 23, 2008 - link
Core i7 wins big time for 3D rendering, modeling, and CAD programs.Turbo is the best feature. I hope, at least in the Extreme Edition we can set the Turbo headroom to like 5Ghz!!! and have a totally dynamic over-clock scaling FTW!
Zbrush can utilize 256 processors, so I think a 2 socket Core i7 will help me out just fine. Sure is don't automatic boost FPS in games, but but that's partially a programming issue as well. Sooner or later the coding will catch up.
munyaka - Friday, August 22, 2008 - link
I have always stuck with amd but this is the final Nail in the coffin.X1REME - Friday, August 22, 2008 - link
Is there anything you see that we don't, please explain why?niva - Friday, August 22, 2008 - link
Well it is another step forward for Intel while AMD is still falling farther and farther behind the times. I want to caution that at this point there is no software actually optimized to run on i7 and any potential new instructions the chips will have. Once that happens and games are patched/recompiled or new games come out to take advantage of the massive CPU/memory bandwidth i7 offers it will be lights out.Waiting on AMD to come out with the next best thing is becoming really old. I have a Phenom system, I won't need a new one for at least another year or two but even though I wish AMD would do better they're just being dominated by intel right now.