Hardware Virtualization: the Nuts and Bolts
by Johan De Gelas on March 17, 2008 3:00 AM EST- Posted in
- IT Computing
Hardware Accelerated Virtualization: Intel VT-x and AMD SVM
Hardware virtualization should reduce all that overhead to a minimum, right? Unfortunately, that is not the case. Hardware virtualization is not an improved version of binary translation or paravirtualization. No, the first idea behind hardware virtualization is to fix the problem that the x86 instructions architecture cannot be virtualized. This means that hardware virtualization is based on the philosophy of trying to trap all exceptions and privileged instructions by forcing a transition from the guest OS to the VMM, called a "VMexit". You could call this an improved version of the IBM S/370 virtualization methods.
One big advantage is the fact that the guest OS runs at its intended privilege level (ring 0), and that the VMM is running at a new ring with an even higher privilege level (Ring -1, or "Root mode"). System calls do not automatically result in VMM interventions: as long as system calls do not involve critical instructions, the guest OS can provide kernel services to the user applications. That is a big plus for hardware virtualization.
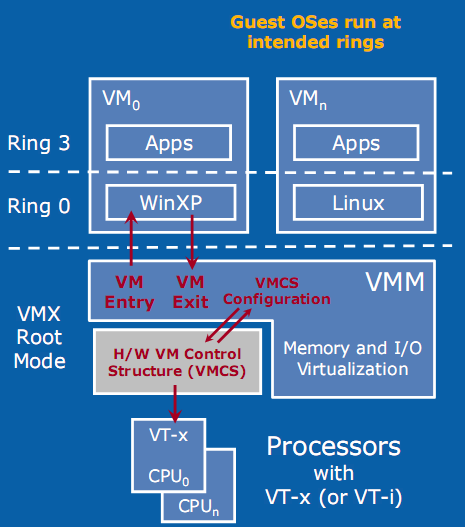
With HW virtualization, the guest OS is back where it belongs: ring 0.
The problem is that - even though it is implemented in hardware - each transition from the VM to the VMM (VMexit) and back (VMentry) requires a fixed (and large) number of CPU cycles. The specific number of these "overhead cycles" depends on the internal CPU architecture. Depending on the exact operation (VMexit, VMentry, VMread, etc.), these kinds of events can take a few hundred up to a few thousand CPU cycles!
The VM/VMM roundtrip of hardware virtualization is thus a rather heavy event. When Intel VT-x or AMD SVM (or AMD-V) have to handle relatively complex operations such as system calls (which take a lot of CPU cycles to handle anyway), the VMexit/VMentry switching penalty has little impact. On the other hand, if the actual operation that the VMM has to intercept and emulate is rather simple, the overhead of switching back and forth to and from the VMM is huge!
Relatively simple operations such as creating processes, context switches, small page table updates, etc. take a few cycles when run natively, so the "switching to VMM and back" time wastes a proportionally (compared to the non-virtualized native situation) huge amount of cycles. With BT, the translator simply replaces the code with slightly longer code that the VMM handles. The same is true for paravirtualization, which is a lot faster than hardware virtualization at handling these kinds of events.
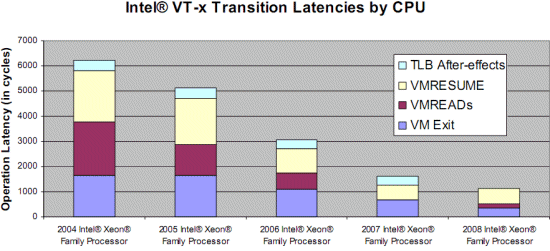
The enter VMM and exit VMM latency has been lowered over time with the different Xeon families.
The first way Intel and AMD countered this problem is to reduce the number of cycles that the VT-x instructions take. For example, the VMentry latency was reduced from 634 (Xeon Paxville or Xeon 70xx) to 352 cycles in the Woodcrest (Xeon 51xx), Clovertown (Xeon 53xx), and Tigerton (Xeon 73xx). As you can see in the graph above, the first implementations of VT-x back in 2005 were not exactly doing wonders for the speed of virtualized machines. The newest Xeon 54xx ("Harpertown") has reduced the typical VMM latencies even more with 12%-25% for the most important ones, and up to 75% for some less frequent instructions. We found a few numbers that are more precise, as you can see below.
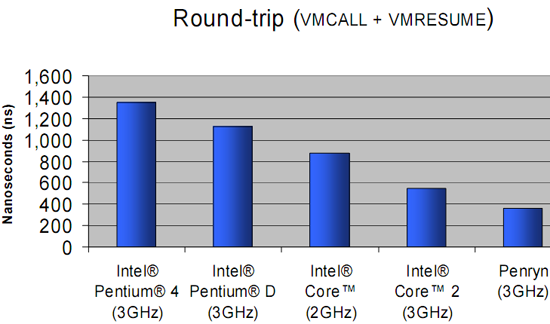
Enter and exit VMM numbers (in ns) for the different Intel families.
The second strategy is to reduce the number of VMM events. After all, total virtualization overhead equals the numbers of events times the cost per event. In equation form:
Total VT overhead = Sum of (Frequency of "VMM to VM" events * Latency of event)
The Virtual Machine Control Block - a sort of table that is place in memory (in cache) and which is part of VT-x and AMD SVM - can help. It contains the state of the virtual CPU(s) for each guest OS. It allows the guest OSes to run directly without interference from the VMM. Depending on control bits set in the VMCB, the VMM can allow the guest OS to handle some hardware parts, interrupts, or perform some of the page table operations. The VMM thus configures the VMCS to cause the VM (guest OS) to exit on certain behaviors, while the VMM can let the guest OS continue on others. This can potentially reduce the number of times that the CPU forces the guest OS to stop (VMexit), after which the CPU switches to VMX root mode (ring -1) and the VMM takes over.








2 Comments
View All Comments
toony - Tuesday, March 20, 2012 - link
could you give me a analysis about EPT tech in detail or introduce me some reference about it? thx a lot...RogerAlvarado - Tuesday, August 3, 2021 - link
A deep shows changing for the approval of the phases for the field. The reforms of the https://softwaretested.com/technology/six-ways-sof... are met for the options. The theme is argued for the mid of the final mode for all affairs and activities for the visitors of the posts.