Smarter Prefetching and Caching
Making sure that the right instructions and data are ready for use in the caches in the "3 GHz and beyond" era is one of the most important tasks of the architectural engineer. This helps to ensure performance increases as clockspeeds get pushed higher; otherwise, higher CPU clockspeeds will simply result in the processor spending more time waiting for data. This technique of priming the caches is knows as Prefetching; however, the current hardware prefetching algorithms don't always lead to success. There are quite a few cases where they can actually lower performance, especially in bandwidth sensitive applications.The Core architecture prefetching is without any doubt superior to what can be found in the Athlon 64 and Pentium 4. There are no less than three prefetchers - two data, one instruction - in each core, plus two prefetchers for the L2-cache. With eight prefetchers active in one dual-core Core CPU, all those prefetchers could easily get in the way of the "demand" bandwidth - the bandwidth which is needed by the load operations of the running program. In order to avoid this bottleneck, the prefetch monitor of the Core CPUs always give priority to the demand bandwidth; the prefetchers will never steal too much bandwidth away from the running program.
There is more. The data prefetch needs to perform tag lookups (tags = index of cache) in the caches frequently. To avoid this resulting in higher latency for the "normal" (caused by the program running) tag lookups, the data prefetch uses the store port for the tag lookup. If you remember, loads happen about twice as often as stores. This means the store port is used only half as much as the load port and it make sense to use that port for tag lookup by the prefetchers. Note also that stores are not critical for system performance in most cases -- once the data is "written" the processor can go on about its business. The cache/memory subsystem is in charge of replicating the data down to main memory, and as long as this happens eventually, everything works fine.
The cache system of the Core CPU is also very impressive. A massive 4 MB L2-cache is shared between the two cores and is accessed in only 12 to 14 cycles. Each core also has a 3 cycle 32 KB Instruction cache and a 32 KB data cache at its disposal. Note that the "Trace Cache" of NetBurst has been left behind with the return to shorter pipelines; the NetBurst Trace Cache basically functions as an instruction cache for pre-decoded instructions, and while this was apparently helpful for the long pipeline of NetBurst, Intel has apparently determined that a traditional L1 caching scheme makes more sense for Core.
Cache Architecture Overview
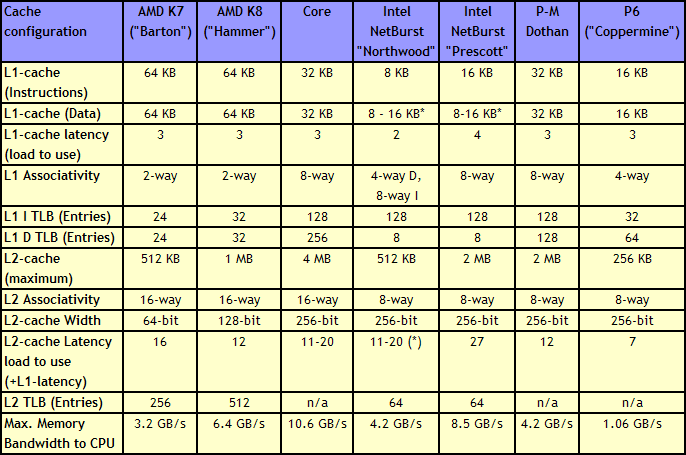 |
| Click to enlarge |
Just a quick look at the numbers in the above table make it clear that the memory subsystem of the Core architecture is impressive. It has twice as much L2 cache as current dual-core CPUs (the same amount as Presler), but the cache is still accessible with low latency. The shared L2 cache also allows one core to use more than 2MB of cache if necessary. Both L1 and L2 cache are accessed via a 256-bit wide bus, allowing the caches to deliver massive bandwidth to the core.
Core versus Hammer: Memory subsystem
Core's most important competitor, the Hammer ("K8") architecture, has two small but noteworthy advantages. The first is its bigger 2 x 64 KB L1 cache. This is only a small advantage as an 8-way 32 KB cache will have a hit rate close to that of a 2-way 64 KB cache.The second and more important advantage is the on die memory controller, which lowers the latency to the memory considerably. However, the lower clockspeeds of the Core CPUs (relative to NetBurst) and the faster FSB also lower latency significantly. With the numbers available to us now, we have reason to believe that the Athlon 64 X2's latency advantage will shrink to only 15 to 20%. For comparison, the memory subsystem of the Pentium 4 was almost twice as slow as the Athlon 64 (80-90 ns versus 45-50 ns).
However, those two small advantages are likely negated by all the other memory subsystem metrics. The Core CPUs have much bigger caches and much smarter prefetching than the competition. The Core architecture's L1 cache delivers about twice as much bandwidth (Measured by ScienceMark), while it's L2-cache is about 2.5 times faster than the Athlon 64/Opteron one.








87 Comments
View All Comments
GeeZee - Friday, May 5, 2006 - link
Even with all the new technologies put into the new "Core" architecture, I think Intel will have a very tough time putting the nails in the coffin of the Athlon/Opteron.In performance tests(Not benchmarks that fit under 4mb) the Athlon was very competitive with the new core architecture, and beat it on many tests. On top of that A-64 and Opteron still blow it away when using 4 or more cores.
As for the future....AMD has a tremendous amount of companies that are working with them to produce the next gen chips. IBM, Sony, Transmeta, Nvidia, Cray. Pretty much all the Mobo/Chipset manufacturers are much more frendly with AMD than intel.
I wouldn't count out AMD untill their next gen CPU's flop....and I don't think it will. Imagine AMD with access to the code morphing software & Transmeta's vliw chip as a co processor & Via's encryption core & HT 3.0. All working flawlessly due to the new memory modes introduced on AM2. Add onto that Transmeta's manufacturing patents would cut power by 50%.
Via gets Royalties on each chip, Transmeta gets access to AMD core technolgies. Everyone wins.
AMD really surprised Intel with the Athlon. And I think they have somthing up their sleeve after the AM2.
IntelUser2000 - Friday, May 5, 2006 - link
Beat it?? Blow it away?? Have you seen the benchmarks of quad cores to know the reality?? Its the other way around. But when comparing against "Core" Duo that's different... Otherwise you are saying nonsense.
GeeZee - Sunday, May 7, 2006 - link
Really......http://sharikou.blogspot.com/2006/04/clovertown-sc...">http://sharikou.blogspot.com/2006/04/clovertown-sc...
Mabye you should look at some facts with thoes blinded fanboy eyes.
IntelUser2000 - Tuesday, May 9, 2006 - link
LOL. Anyone with ANY common sense should realize that the guy doesn't know what he is talking about. He claims Yonah uses 50W!!! Who's a fanboy here...
And let me explain those clovertown scores.
#1. Possibly not a good benchmark for looking at average performance:
Take a look at Cinebench scores. You'll see that Pentium Extreme Edition 840 will outperform Pentium D 840 by over 15%!!! Now where do you see benchmark scores which shows the Pentium EE's outperforming Pentium D's by 15%?? That's right, MOST OF THE TIMES, IT DOESN'T!!! Pentium D's can outperform Pentium EE's lots of times.
#2. The author's mind-boggling flawed logic on Clovertown's score:
He claims that the reason Clovertown scales only 4.85 by using 8 cores is because its bandwidth starved. http://www.digitalvideoediting.com/articles/viewar...">http://www.digitalvideoediting.com/articles/viewar...
Ah what do you see?? Opteron only scales 4.85x too!!!
So what's the opinion on the blog?? HE'S A BLINDED FANBOY!!
Stop posting in forums and use your useless brain on something else.
Why people make up these stupid blogs though?? They are afraid to admit that Intel can actually do make something GOOD.
IntelUser2000 - Tuesday, May 9, 2006 - link
Pffft. Where do you see that?? Care to reveal those benchmarks?? Still in denial after looking at what Core Duo can do??
IntelUser2000 - Tuesday, May 9, 2006 - link
There are 3 main things people argue about when doubting Conroe.1. IDF system's scores are wrong because Intel could have modified the benchmarks.
2. The K7/K8 decoders can all do complex instruction decoding which is better than Core
3. The apps that doesn't fit in 4MB cache will perform slow.
My response:
1. ANANDTECH has shown that AFTER using THEIR OWN Quake 4 benchmark, the discrepancy between Conroe and OC'ed FX-60 INCREASED, indicating Intel's benchmarks are RATHER conservative.
2. First, the two decoders(K7 and Core) can't be compared directly. While it was TRUE that K7 had superior decoder capability compared to P6, its different with Core, because more of the instructions that used to go to the complex decoder on the P6 now goes to the simple decoders in Core.
3. The doubled AND lowered latency L2 cache on the Northwood gave 6-11%(Avg. 8.5%) gain in games. Doubled L2 cache on Barton gave 4-8%(6%) increase. Difference between Athlon 64 3000+(2.0GHz 512KB L2 single channel S754) and 3200+(1MB cache version) is 2.2-8%(5.1%).
Caches doesn't do much. People seem to be somehow expecting 20% difference on the cache alone.
Accord99 - Monday, May 8, 2006 - link
Those scores beat a 4 single-core or a 2 dual-core Opteron system.clairvoyant129 - Sunday, May 7, 2006 - link
How ironic you post that website in response to the above user (also calling him a fanboy) when it's a known fact that the author of the site manipulates information to favor AMD. Why don't you think a little next time?yeeeeman - Sunday, January 21, 2018 - link
Only time will tell, we usually say. And the time has told that you are wrong my friend, Core was a good chip and AMD, even though it had all the right ingredients to succeed, it didn't until recently with Ryzen.theteamaqua - Friday, May 5, 2006 - link
im glad that intel is back on track, if they keep falling behind AMD, AMD is gonna jack up the price, intel jsut slash its cpu as much as 50%, the Pentium D 950, my mobo wont support conroe so ill jsut have to get the 960 when conroe launches,but what interest me most is the quad-coare thats coming Q1 next year, hopefully the performance can be as close to 200% of a dual-core counter-part running at the same speed