Apple's M1 Pro, M1 Max SoCs Investigated: New Performance and Efficiency Heights
by Andrei Frumusanu on October 25, 2021 9:00 AM EST- Posted in
- Laptops
- Apple
- MacBook
- Apple M1 Pro
- Apple M1 Max
Huge Memory Bandwidth, but not for every Block
One highly intriguing aspect of the M1 Max, maybe less so for the M1 Pro, is the massive memory bandwidth that is available for the SoC.
Apple was keen to market their 400GB/s figure during the launch, but this number is so wild and out there that there’s just a lot of questions left open as to how the chip is able to take advantage of this kind of bandwidth, so it’s one of the first things to investigate.
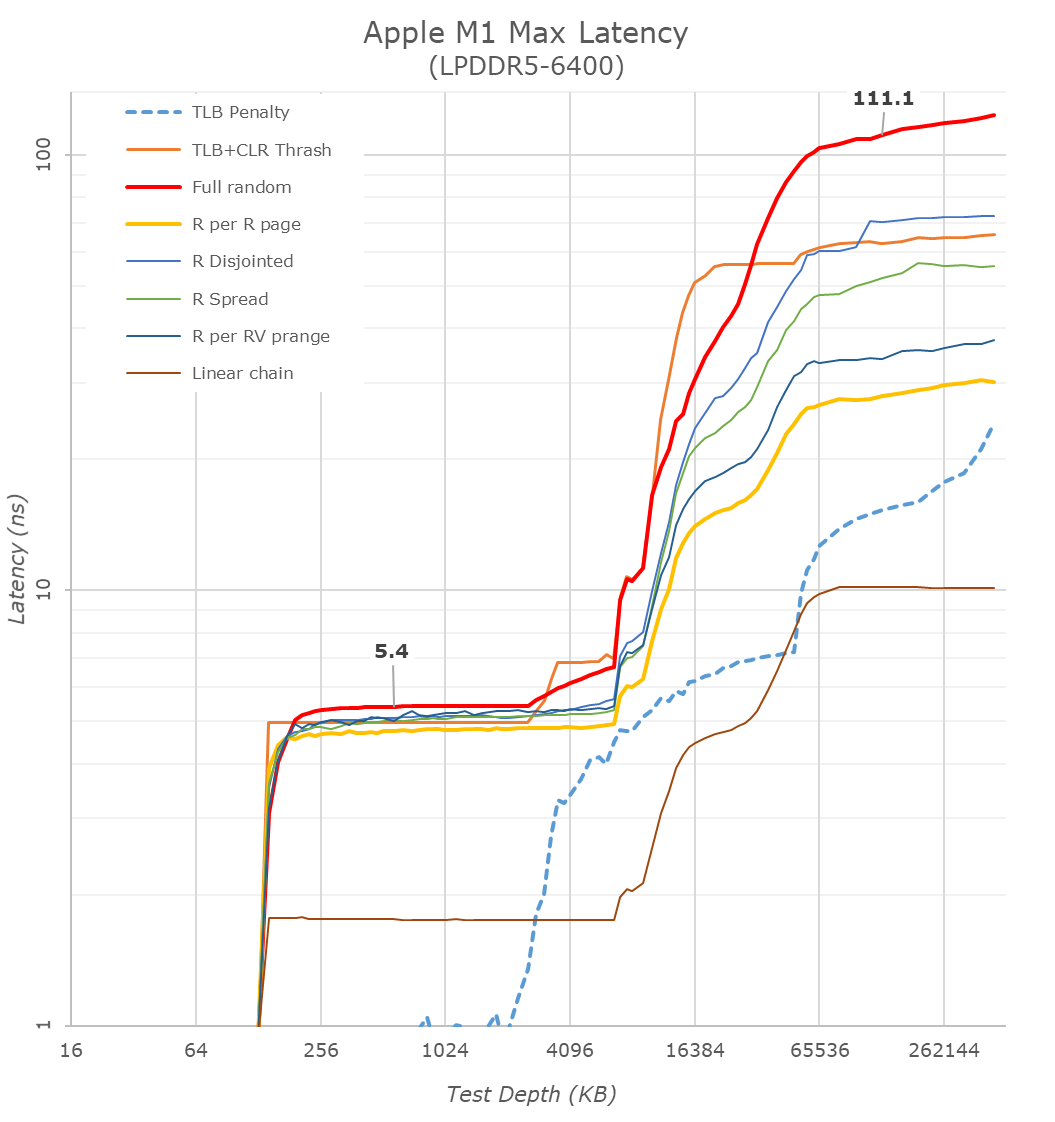
Starting off with our memory latency tests, the new M1 Max changes system memory behaviour quite significantly compared to what we’ve seen on the M1. On the core and L2 side of things, there haven’t been any changes and we consequently don’t see much alterations in terms of the results – it’s still a 3.2GHz peak core with 128KB of L1D at 3 cycles load-load latencies, and a 12MB L2 cache.
Where things are quite different is when we enter the system cache, instead of 8MB, on the M1 Max it’s now 48MB large, and also a lot more noticeable in the latency graph. While being much larger, it’s also evidently slower than the M1 SLC – the exact figures here depend on access pattern, but even the linear chain access shows that data has to travel a longer distance than the M1 and corresponding A-chips.
DRAM latency, even though on paper is faster for the M1 Max in terms of frequency on bandwidth, goes up this generation. At a 128MB comparable test depth, the new chip is roughly 15ns slower. The larger SLCs, more complex chip fabric, as well as possible worse timings on the part of the new LPDDR5 memory all could add to the regression we’re seeing here. In practical terms, because the SLC is so much bigger this generation, workloads latencies should still be lower for the M1 Max due to the higher cache hit rates, so performance shouldn’t regress.
A lot of people in the HPC audience were extremely intrigued to see a chip with such massive bandwidth – not because they care about GPU or other offload engines of the SoC, but because the possibility of the CPUs being able to have access to such immense bandwidth, something that otherwise is only possible to achieve on larger server-class CPUs that cost a multitude of what the new MacBook Pros are sold at. It was also one of the first things I tested out – to see exactly just how much bandwidth the CPU cores have access to.
Unfortunately, the news here isn’t the best case-scenario that we hoped for, as the M1 Max isn’t able to fully saturate the SoC bandwidth from just the CPU side;
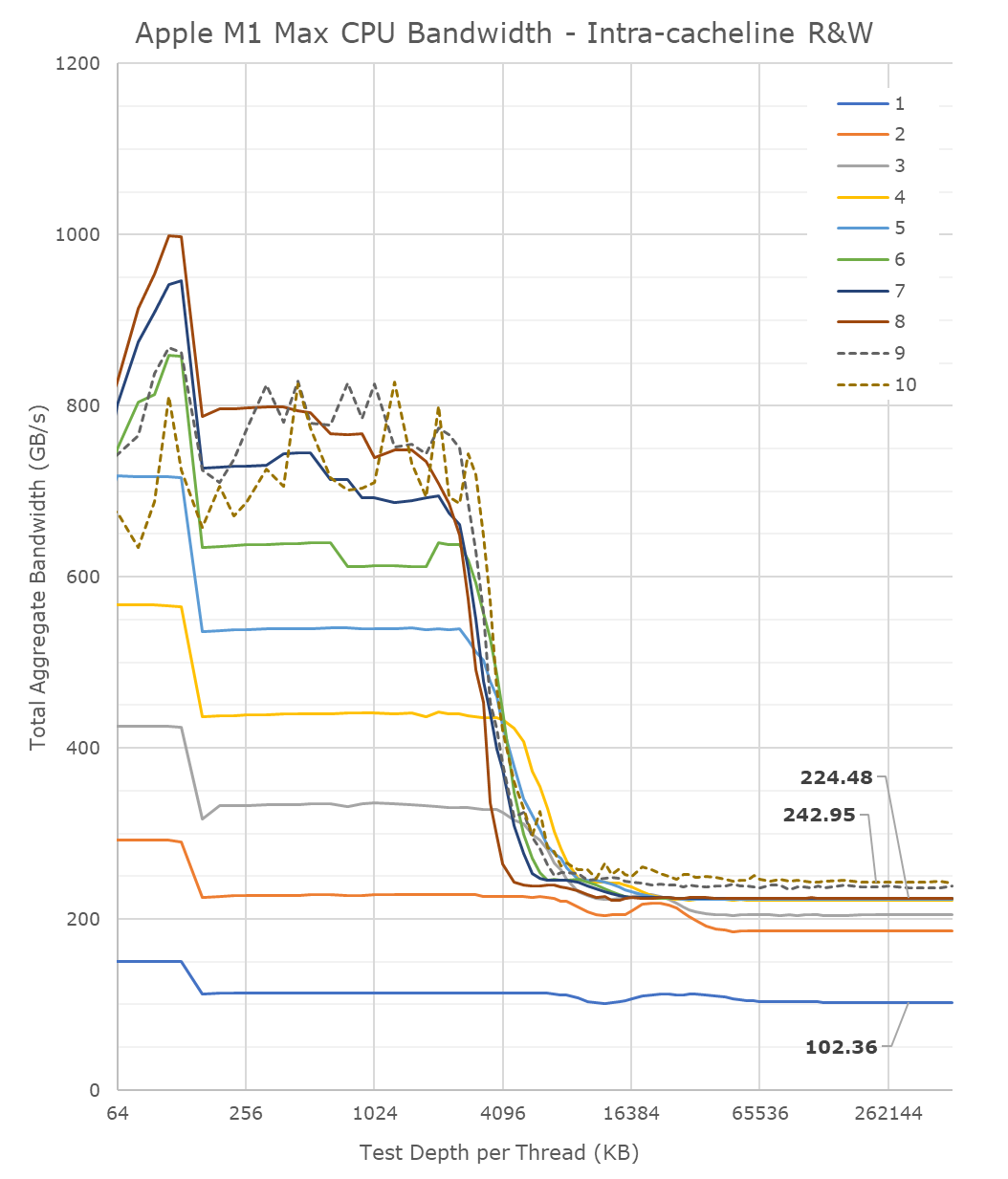
From a single core perspective, meaning from a single software thread, things are quite impressive for the chip, as it’s able to stress the memory fabric to up to 102GB/s. This is extremely impressive and outperforms any other design in the industry by multiple factors, we had already noted that the M1 chip was able to fully saturate its memory bandwidth with a single core and that the bottleneck had been on the DRAM itself. On the M1 Max, it seems that we’re hitting the limit of what a core can do – or more precisely, a limit to what the CPU cluster can do.
The little hump between 12MB and 64MB should be the SLC of 48MB in size, the reduction in BW at the 12MB figure signals that the core is somehow limited in bandwidth when evicting cache lines back to the upper memory system. Our test here consists of reading, modifying, and writing back cache lines, with a 1:1 R/W ratio.
Going from 1 core/threads to 2, what the system is actually doing is spreading the workload across the two performance clusters of the SoC, so both threads are on their own cluster and have full access to the 12MB of L2. The “hump” after 12MB reduces in size, ending earlier now at +24MB, which makes sense as the 48MB SLC is now shared amongst two cores. Bandwidth here increases to 186GB/s.
Adding a third thread there’s a bit of an imbalance across the clusters, DRAM bandwidth goes to 204GB/s, but a fourth thread lands us at 224GB/s and this appears to be the limit on the SoC fabric that the CPUs are able to achieve, as adding additional cores and threads beyond this point does not increase the bandwidth to DRAM at all. It’s only when the E-cores, which are in their own cluster, are added in, when the bandwidth is able to jump up again, to a maximum of 243GB/s.
While 243GB/s is massive, and overshadows any other design in the industry, it’s still quite far from the 409GB/s the chip is capable of. More importantly for the M1 Max, it’s only slightly higher than the 204GB/s limit of the M1 Pro, so from a CPU-only workload perspective, it doesn’t appear to make sense to get the Max if one is focused just on CPU bandwidth.
That begs the question, why does the M1 Max have such massive bandwidth? The GPU naturally comes to mind, however in my testing, I’ve had extreme trouble to find workloads that would stress the GPU sufficiently to take advantage of the available bandwidth. Granted, this is also an issue of lacking workloads, but for actual 3D rendering and benchmarks, I haven’t seen the GPU use more than 90GB/s (measured via system performance counters). While I’m sure there’s some productivity workload out there where the GPU is able to stretch its legs, we haven’t been able to identify them yet.
That leaves everything else which is on the SoC, media engine, NPU, and just workloads that would simply stress all parts of the chip at the same time. The new media engine on the M1 Pro and Max are now able to decode and encode ProRes RAW formats, the above clip is a 5K 12bit sample with a bitrate of 1.59Gbps, and the M1 Max is not only able to play it back in real-time, it’s able to do it at multiple times the speed, with seamless immediate seeking. Doing the same thing on my 5900X machine results in single-digit frames. The SoC DRAM bandwidth while seeking around was at around 40-50GB/s – I imagine that workloads that stress CPU, GPU, media engines all at the same time would be able to take advantage of the full system memory bandwidth, and allow the M1 Max to stretch its legs and differentiate itself more from the M1 Pro and other systems.








493 Comments
View All Comments
JfromImaginstuff - Monday, October 25, 2021 - link
Huh, niceKangal - Monday, October 25, 2021 - link
What isn't nice is gaming on macOS.We all know how bad emulation is, and whilst Apple seems to have pulled "magic" with their implementation of Metal/Rosetta2's hybrid-translation strong performance.... at the end of the day it isn't enough.
The M1X is slightly slower than the RTX-3080, at least on-paper and in synthetic benchmarks. This is the sort of hardware that we've been denied for the past 3 years. Should be great. It isn't. When it comes to the actual Gaming Performance, the M1X is slightly slower than the RTX-3060. A massive downgrade.
The silver lining is that developers will get excited, and we might see some AAA-ports over to the macOS system. Even if it's the top-100 games (non-exclusives), and if they get ported over natively, it should create a shock. We might see designers then developing games for PS5, XSX, OSX and Windows. And maybe SteamOS too. And in such a scenario, we can see native-coded games tapping into the proper M1X hardware, and show impressive performance.
The same applies for professional programs for content creators.
at_clucks - Monday, October 25, 2021 - link
"The silver lining is that developers will get excited, and we might see some AAA-ports over to the macOS"I think that's their whole point. Make developers optimize for Mac knowing that gamers would very likely choose to have their performant gaming machine in a Mac format (light, cool, low power) rather than in a hot and heavy DTR format if they had the choice of natively optimized games.
bernstein - Monday, October 25, 2021 - link
we now have 3 primary gpu api‘s:- directx (xbox, windows)
- vulkan (ps5, switch, steamos, android)
- metal (macos, ios & derivates)
Because they’re all low level & similar, most bigger engines support them all.
There used to be two for pc, one for mobile and three for consoles. And vastly different ones at that.
So it will come down to the addressable market and how fast apple evolves the api‘s. Historically windows, with its build once run two decades later has made it much much easier on devs.
yetanotherhuman - Tuesday, October 26, 2021 - link
"how fast apple evolves the api‘s"That'll be a very slow, given their history. Why they invented another API, I have no idea. Vulkan could easily be universal. It runs on Windows, which you didn't note, with great results.
Dribble - Tuesday, October 26, 2021 - link
Vulkan is too low level, it assumes nothing which means you have to right a ton of code to get to the level of Metal which assumes you have an apple device. If metal/dx are like writing in assembly language, for vulkan you start of with just machine code and have to write your own assembler first. Hence it's not really a great language to work with, if you were working with apple then metal is so much nicer.Gracemont - Wednesday, October 27, 2021 - link
Vulkan is too low level? It’s literally comparable to DX12. Like bruh, if anything the Metal API is even more low level for Apple devices cuz of it being built specifically for Apple devices. Just like how the NVAPI for the Switch is the lowest level API for that system cuz it was specifically tailored for that system, not Vulkan.Ppietra - Wednesday, October 27, 2021 - link
Gracemont, the Metal API was already being used with Intel and AMD GPUs, so not exactly a measure of "low level"NPPraxis - Tuesday, October 26, 2021 - link
"Why they invented another API, I have no idea. Vulkan could easily be universal."You're misremembering the history. Metal predates Vulkan.
Apple was basically stuck with OpenGL for a long time, which fell further and further behind as DirectX got lower level and faster. That made all of Apple's devices at a huge gaming handicap.
Then Apple invented Metal for iOS in 2014 which gave them a huge performance rendering lead on mobile devices.
They led the Mac languish for a couple years, not even updating the OpenGL version. Macs got worse and worse for games. In 2016, Vulcan came out. People speculated that Apple could adopt it.
In 2017, Apple released Metal 2 which was included in the new MacOS.
Basically, Apple had to pick between unifying MacOS (Metal) with iOS or with Linux gaming (Vulkan). Apple has gotten screwed over before by being reliant on open source third parties that fell further and further behind (OpenGL, web browsers before they helped build WebKit, etc) so it's kind of understandable that they went the Metal-on-MacOS direction since they had already built it for iOS.
I still wish Apple would add support for it (Mac: Metal and Vulkan, Windows: DirectX and Vulkan, Linux: Vulkan only), because it would really help destroy any reason for developers to target DirectX first, but I understand that they really want to push devs to Metal to make porting to iOS easier.
Eric S - Friday, October 29, 2021 - link
Everyone has their own graphics stack- Microsoft, Sony, Apple, and Nintendo all have proprietary stacks. Vulcan wants to change that, but that doesn’t solve everything. Developers still need to optimize for differences in GPUs. Apple is looking for full vertical integration which helps to have their own stack.