NVIDIA's GeForce 6800 Go vs. ATI's M28: The Mobile GPU Wars Begin
by Anand Lal Shimpi on November 8, 2004 9:00 AM EST- Posted in
- GPUs
Reducing GPU Power: A Quick Lesson in Clock Gating
In order to prepare a desktop GPU for use in a mobile environment, one of the fundamentals of chip design is violated by introducing something called clock gating. All GPUs are composed of tens of millions of logic gates that make up everything from functional units to memory storage on the GPU itself. Each gate receives an input from the GPU-wide clock to ensure that all parts of the GPU are working at the same frequency. But with GPUs getting larger and larger, it becomes increasingly difficult to ensure that all parts of the chip receive the same clock signal at the same time. In order to compensate, elaborate clock trees are created carrying a network of the same clock signal to all parts of the chip, so that when the clock goes high (instructing all of the logic in the chip to perform their individual tasks, sort of like a green light to begin work) all of the gates get the signal at the same time.
The one principle that is always taught in chip design is to make sure that you never allow the clock signal to pass through any sort of logic gates, it should always go from the source of the signal to its target without passing through anything else. The reason being that if you start putting logic in between the clock signal source and its target, you make the clock tree extremely complicated - since now, you not only have to worry about getting the same clock signal to all parts of the GPU at the same time, but you must also worry about delays introduced by feeding the clock through logic. There are benefits to clock gating however, and they primarily are for power savings.
It turns out that the easiest way to turn off a particular part of a chip is to stop feeding a clock signal to it; if the clock never goes high, then that part of the chip never knows to start working, so it remains in its initial state which is of non-operation. But you obviously don't want the clock disabled all of the time, so you need to implement logic that determines whether or not the clock should be fed to a particular part of the chip.
When you're typing in Word, all your GPU is doing consists of 2D and memory operations. The floating point units of the GPU are not needed, nor is anything related to the 3D pipeline. So let's say we have a part of the chip that detects whether or not you are typing in Word instead of playing a game, and that part of the chip sends a signal called 2D_Power_Save. When you are just in Word and don't need any sort of 3D acceleration, 2D_Power_Save goes high (the signal carries a value of '1', or electrically, whatever the high voltage is on the core), otherwise the signal stays low ('0' or 0V).
Using this 2D_Power_Save signal we could construct some logic using the clock that is fed to all of the parts of the 3D engine on the GPU. The logic could look something like this:
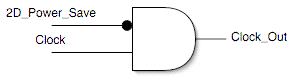
The very simple logic illustrated above is a logical AND gate with two input signals and one output. The 2D_Power_Save signal is inverted, so when it is high the value fed to the AND gate is low and vice versa. If the 2D_Power_Save signal is high, it is inverted and passed to the AND gate as a low signal, meaning that the Clock_Out signal will never be high and thus anything connected to it will always be low. If 2D_Power_Save is low, then the clock gets pass through to the rest of the GPU. That's how clock gating works.
We mentioned earlier that modern day GPUs are composed of tens of millions of gates (each gate is made up of multiple transistors), and while it would be nice to, it's virtually impossible to put this sort of logic in place for every single one of those gates. For starters, you'd have an incredibly huge chip thanks to spending even more transistors on logic for your clock gating, and it would also make your clock tree incredibly difficult to construct. So what happens is that the clock fed to large groups of gates, known as blocks, is gated, instead of gating the clocks to individual gates. The trick here is that the smaller the blocks you gate (or the more granular you clock-gate), the more efficient your power savings will be.
Let's say we've taken our little gated clock from above and fed it to the entire 3D rendering pipeline. So when 3D acceleration is not required (e.g. we're just typing away in MS Word), the entire 3D pipeline and all of its associated functional units are shut off, thus saving us lots of power. But now, when we fire up a game of Doom 3, all of our power savings are lost as the entire 3D engine is turned back on.
What if we could turn off parts of the GPU not only depending on what type of application we're running (2D or 3D) but also based on what the specific requirements of that application are. For example, Doom 3's shaders perform certain operations that will stress some parts of the GPU, while a game like Grand Theft Auto will stress other parts of the GPU. A more granular implementation of clock gating would allow the GPU to differentiate between the requirements of the two applications and thus offer more power savings.
While we're not quite at the level of the latter example, the one thing that is true is that today's mobile GPUs offer more granular clock gating than the previous generation. This will continue to be true for future mobile GPUs as smaller manufacturing processes and improvements in GPU architecture will allow for more and more granular clock gating.
So where are we today with the GeForce 6800 Go?
With the NV3x series of GPUs, as soon as a request hit the 3D pipeline, the entire 3D pipeline powered up and it didn't power down until the last bits of data left the pipeline. With the GeForce 6800 Go, different stages of the 3D pipeline will only power up if they are being used, otherwise they remain disabled thanks to clock gating. What this means is that power consumption in 3D applications and games is much more optimized now than it ever was before and it will continue to improve with future mobile GPUs.
Since ATI's M28 has not officially been launched yet we don't have any information on its power consumption, however given that the X800 consumes less power than the 6800 on the desktop, we wouldn't be too surprised to see a similar situation emerge on the mobile side of things as well.








24 Comments
View All Comments
onix - Tuesday, November 23, 2004 - link
"I'm very disapointed with this article for a few reasons:1) There is no point of reference. Where are the benchmarks for a radeon 9700 Mobility or Radeon 9800 Mobility? We have no idea how much faster these things are than existing mobility parts "
Agreed. I am about to buy a ThinkPad T42p with a 128MB ATI Mobility FireFL T2, and don't know what I'll be passing up.
Neekotin - Friday, November 12, 2004 - link
who plays in a laptop anyway?Shadowmage - Wednesday, November 10, 2004 - link
The Mobility X600 uses 1W idle and 9-10W on max power. I would like to know how the Mobility M28 and nVidia 6800 go compare in wattage and heat. Remember that the X800 whoops the 6800 in both heat and power.stephenbrooks - Tuesday, November 9, 2004 - link
Nice review, though it would have been nice to see the difference in power consumption (and hence battery life) of the desktop vs. notebook GPUs in the previous and current generations, so we could see how much good the 'clock gating' that was nicely explained at the beginning of the article does. Probably a hard thing to do with limited time though.Terr1 - Tuesday, November 9, 2004 - link
Hey im in the proccess of buying a new laptop, which im using with my studies and of cause gaming (since its going to be faster than my stationary computer. I dont want a normal Pentium 4 M, because of the low battery usage. My choice is 100% on centrino (dothan CPU), so my question is, do you think this come to the centrino chipsets as well? Since it prob. require a new chipset that suppports PCI-Express, as far as I know the next chipset will first come in about 3-6 months. I need mine around january, and pref. faster.. So is it stupid to buy ATI 9700PRO 128mb card now?Woodchuck2000 - Tuesday, November 9, 2004 - link
It's hardly surprising that the 6800 loses in the majority of benches given that it's clocked 100/100 lower than the M28 and both are 12 pipe parts.... It would be interesting to compare the solutions at equal clock speeds.Is 400/400 the likely shipping speed of the M28 and if so why is ATi's DDR3 clocked 200MHz slower than nVidia's high end solution?
Live - Tuesday, November 9, 2004 - link
You really should include the minimum FPS recorded in your benchmarks. Average FPS doesn't say it all. Other then that it was a good first look at these new GPUs.Camylarde - Monday, November 8, 2004 - link
# 16 thats nod needed. WIll lack comparison to desktop GPU'sThanks Anand for your review, yet, I agree with all those negative comments about quality of the review. I am considering you as one of the best reviewers on the net and your articles never disappointed me. This one is far from being best and as you wrote, you know that. Rather wait one more day for a full work than "launch not available product".
Cheers, Petr
klah - Monday, November 8, 2004 - link
" I'm hoping to have a shipping version of M28 by the end of this month for more thorough tests."How about some benches using the native resolutions of the displays(1690x1050).
skunkbuster - Monday, November 8, 2004 - link
i think they named it that way to reflect that the mobility 9800 performed on par to a regular desktop radeon 9800.i think that if it performed closer to an x800, then maybe they would have called it that instead...