Linux Shootout: Opteron 150 vs. Xeon 3.6 Nocona
by Kristopher Kubicki on August 12, 2004 2:35 PM EST- Posted in
- Linux
TSCP
We apologize for the broken TSCP Makefile in the previous review which rendered our initial results inaccurate. Fortunately we posted the file so that others were able to detect the error and not find fault with the processors instead. The large issue many of our readers have brought to our attention are the severe difference in performance between various optimizations. Below you can see how various compile flags affected our benchmark scores.
The first benchmark is run with the optimization flags:
-O2 -funroll-loops -frerun-cse-after-loop
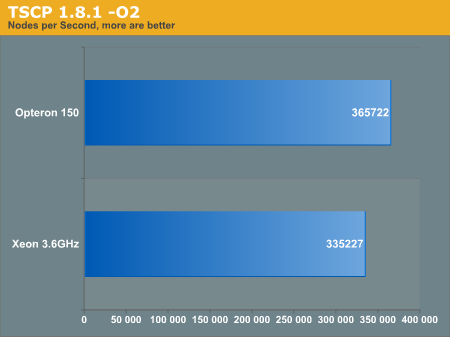
The next benchmark is run with the optimization flags:
-O3 funroll-loops -frerun-cse-after-loop
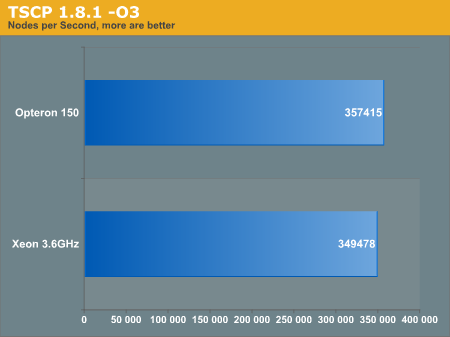
Finally, we have the architecture optimized flags as well:
(Intel) -O3 - march=nocona -funroll-loops -frerun-cse-after-loop
(AMD) -O3 - march=k8 -funroll-loops -frerun-cse-after-loop
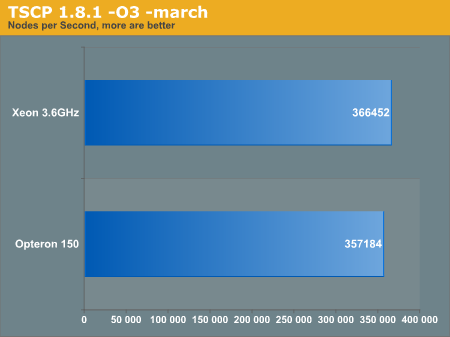
You are reading these charts correctly, the O3 flag actually penalizes the AMD CPU. We also compiled the program with -O2 -march=k8 but we got virtually the same score with or without the march flag.
We were informed others have been capable of much faster nodes per second using GCC 3.4.1 and the flagset:
-O3 -march=athlon-xp -funroll-loops -fomit-frame-pointer -ffast-math -fbranch-probabilities
We did not have time to fully test GCC 3.4.1, although there is a strong likelihood that 3.4 encourages better optimizations (particularly on the x86_64 platforms).
Crafty
For good measure, we have included Crafty into our chess benchmarks section. Crafty was only built using the "make linux-amd64" target. From the Makefile, it seems as though the "AMD64" moniker is slightly inappropriate. The target claims:
# -INLINE_AMD Compiles with the Intel assembly code for FirstOne(), # LastOne() and PopCnt() for the AMD opteron, only tested # with the 64-bit opteron GCC compiler.
The benchmark was generated by running the "bench" command inside the program.
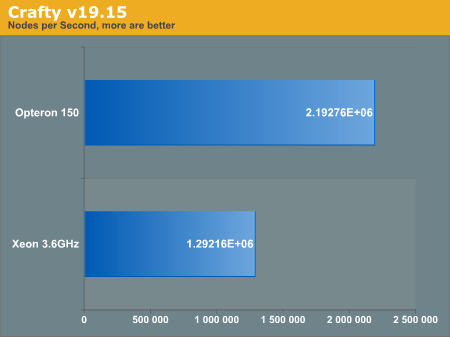
It is clear the difference between both processors is quite severe in this instance. Although it is difficult to pin an exact culprit, there are likely multiple arch optimizations were left untapped, and thus our reasoning for discouraging overusage of optimizations in general.








92 Comments
View All Comments
- Saturday, October 24, 2009 - link
http://www.goph3r.com/mh">http://www.goph3r.com/mh(air jordan, air max, shox tn, rift, puma, dunk sb, adidas) nike jordan shoes 1-24 $32
lv, coach, chane bag $35
COOGI(jeans, tshirts, hoody, jacket) $30
christian audigier(jeans, tshirts, hoody) $13
edhardy(shoes, tshirts, jeans, caps, watche, handbag) $25
Armani(jeans, tshirts,) $24
AF(jeans, coat, hoody, sweater, tshirts)Abercrombie & Fitch $31
http://www.goph3r.com/mh">http://www.goph3r.com/mh
- Saturday, October 24, 2009 - link
sell:nike shoes$32,ed hardy(items),jean$30,handbag$35,polo shirt$13,shox$34snorre - Wednesday, August 18, 2004 - link
Everyobe compare the best P4 against the best A64, and that's 3.6F vs. 3800+ or 3.4EE vs. FX-53. It dosen't make sense to compare the most expensive Intel desktop CPU with the cheapest AMD desktop CPU (for socket 939). So, the best Xeon should always be compared with the best Opteron at any given time. It's that simple, so why argue about the obvious?JGunther - Tuesday, August 17, 2004 - link
Don't be daft ss284.He simply means that if you're gonna compare A64 to P4, you should make sure you're comparing CPUs at similar price points. If the 3.6F will retail for $637 as KK claims, then the 3.6F is positioned against the A64 3800+. No question about it.
ss284 - Monday, August 16, 2004 - link
In regards to: 67 - Posted on Aug 13, 2004 at 12:36 AM by Arias74"I'm still a little confused why KK still thinks that a 3.6GHz P4 will be marketed against a 3500+ A64. They do not occupy the same space, price-wise. If you're looking at a 3500 in the name, even Intel realizes that you can't judge by numbers alone, based on the fact that they are moving to an arbitrary naming convention for their processors. The only way to compare the two different product lines is by price, because that is the only constant. So, if the 3.6GHz P4 is the highest priced desktop cpu, then you would have to compare that to AMD's highest price. "
You're logic doesnt make sense, and you manage to contradict yourself. You are basically saying that I should compare one companies top of the line to anothers' no matter what the price? Did you not just mention that the price was the most important factor for comparison? Comparing the most expensive processors basically factors out price when you compare.
Like Derek Wilson said, it is a valid comparison, and your speculation makes no sense whatsoever, even judging by your own previous statements.
Locutus4657 - Saturday, August 14, 2004 - link
#86, I agree that the fact alone that the Opteron trounces the Xeon does not mean the article is more valid. What does is the fact they Kris took the time to test several cases and was able to show under what conditions the Opteron will trounce the Xeon and under what conditions the Xeon will trounce the Opteron (in the same program depending on compiler options). I would also like to take a second to say that what also helps is the fact that the DB benchmarks make quite a bit more sence in this article. The Opteron's strong suite is DB/Server environments... It did *not* make sence to see the Xeon trouncing an A64 in a DB benchmark like in the first article.acejj26 - Saturday, August 14, 2004 - link
why is it that when the opteron trounces the xeon in a benchmark, you are quick to question the validity of the benchmark, but when the xeon beat the opteron in your previous review, there was no second guessing. perhaps your thought process should have been, since the opteron TROUNCED the xeon in several benchmarks, that the opteron can do those tasks so much better than the xeon. that's how i read benchmarks. also, if you question the validity of john the ripper in your own article, why not just get rid of it? i would have also liked to have seen some more insight to the xeon's 64 bit addressing and processing capability, but if you're leaving that for another review, then that's ok. all in all, much better than the previous review. i'm glad u took the criticism to heart and didn't get angry and defensive.briant - Friday, August 13, 2004 - link
I been a long time AT reader but kept quite for sometimes however this review cuts my silence off. This is a nice review it is indeed informative and better than the first one. Hope to see more reviews like this. Keep it up!briant.
snorre - Friday, August 13, 2004 - link
Kristopher: The P4F is marketed as a workstation CPU and not a desktop CPU like 3x00+/FX-5x. Opteron 1xx/2ss, however, is also marketed as a workstation & server CPU.And there dosen't exist any Xeon MP solutions based on the Nocona core, only DP & UP.
KristopherKubicki - Friday, August 13, 2004 - link
Nocona is just the name of the core. The core refers to both MP/DP and UP solutions.To correct your statement, the 3.6 Xeon DP competes with the Opteron 250. Since the WW31 Intel APAC calls a UP Xeon a Pentium 4, this is where we drew the conclusion that a 3.6F is marketed against a 3x00+/FX-5x/Opteron 1xx.
The 3.6F will retail at $637 according to the APAC by the way. The Xeon DP will retial for $850, correct.
Kristopher