ATI Radeon X800 Pro and XT Platinum Edition: R420 Arrives
by Derek Wilson on May 4, 2004 10:28 AM EST- Posted in
- GPUs
The Pixel Shader Engine
On par with what we have seen from NVIDIA, ATI's top of the line card is offering a GPU with a 16x1 pixel pipeline architecture. This means that it is able to render up to 16 single textured pixels in parallel per clock. As previously alluded to, R420 divides its pixel pipes into groups of four called quads. The new line of ATI GPUs will offer anywhere from one to four quad pipelines. The R3xx architecture offers an 8x1 pixel pipeline layout (grouped into two quad pipelines), delivering half of R420's pixel processing power per clock. For both R420 and R3xx, certain resources are shared between individual pixel pipelines in each quad. It makes a lot of sense to share local memory among quad members, as pixels near eachother on the screen should have (especially texture) data with a high locality of reference. At this level of abstraction, things are essentially the same as NV40's architecture.
Of course, it isn't enough to just look how many pixel pipelines are available: we must also discover how much work each pipeline is able to get done. As we saw in our final analysis of what went wrong with NV3x, the internals of a shader unit can have a very large impact on the ability of the GPU to schedule and execute shader code quickly and efficiently.
At our first introduction, the inside of R420's pixel pipeline was presented as a collection of 2 vector units, 2 scalar units, and one texture unit that can all work in parallel. We've seen the two math and one texture layout of NV40's pixel pipeline, but does this mean that R420 will be able to completely blow NV40 out of the water? In short, no: it's all about what kind of work these different units can do.
Lifting up the hood, we see that ATI has taken a different approach to presenting their architecture than NVIDIA. ATI's presentation of 2 vector units (which are 3 wide at 72bits), 2 scalar units (24bits), and a texture unit may be more reflective of their implementation than what NVIDIA has shown (but we really can't know this without many more low level details). NVIDIA's hardware isn't quite as straight forward as it may end up looking to software. The fact is that we could look at the shader units in NV40's pixel pipeline in the same way as ATI's hardware (with the exception of the fact that the texture unit shares some functionality with one of the math units). We could also look at NV40 architecture as being 4 2-wide vector units or 2 4-wide vector units (though this is still an over simplification as there are special cases NVIDIA's compiler can exploit that allow more work to be done in parallel). If ATI had decided to present it's architecture in the same way as NVIDIA, we would have seen 2 shader math units and one completely independent texture unit.
In order to gain better understanding, here is a diagram of the parallelism and functionality of the shader units within the pixel pipelines of R420 and NV40:
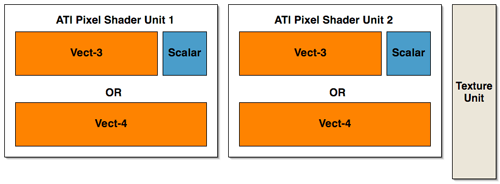
ATI has essentially three large blocks that can push up to 5 operations per clock cycle
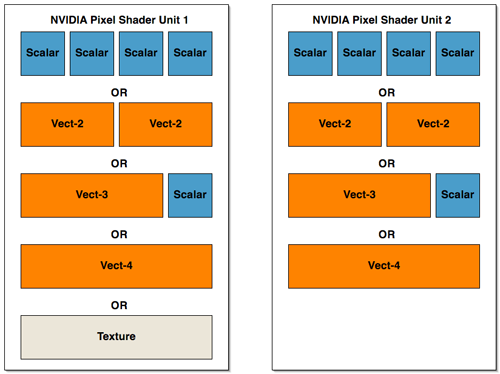
NV40 can be seen two blocks of a more amorphous configuration (but there are special cases that allow some of these parts to work at the same time within each block.
Interestingly enough, there haven't been any changes to the block diagram of a pixel pipeline at this level of detail from R3xx to R420.
The big difference in the pixel pipe architectures that gives the R420 GPU a possible upper hand in performance over NV40 is that texture operations can be done entirely in parallel with the other math units. When NV40 needs to execute a texture operation, it looses much of its math processing power (the texturing unit cannot operate totally independently of the first shader unit in the NV40 pixel pipeline). This is also a feature of R3xx that carried over to R420.
![]()
Understanding what this all means in terms of shader performance depends on the kind of code developers end up writing. We wanted to dedicate some time to hand mapping some shader code to both architecture's pixel pipelines in order to explain how each GPU handled different situations. Trial and error have led us to the conclusion that video card drivers have their work cut out for them when trying to optimize code; especially for NV40. There are multiple special cases that allow NVIDIA's architecture to schedule instructions during texturing operations on the shared math/texture unit, and some of the "OR" cases from our previous diagram of parallelism can be massaged into "and" cases when the right instructions are involved. This also indicates that performance gains due to compiler optimizations could be in NV40's future.
Generally, when running code with mixed math and texturing (with a little more math than texturing) ATI will lead in performance. This case is probably the most indicative of real code.
The real enhancements to the R420 pixel pipeline are deep within the engine. ATI hasn't disclosed to us the number of internal registers their architectures have, or how many pixels each GPU can maintain in flight at any given time, or even cache hit/miss latencies. We do know that, in addition to the extra registers (32 constant and 32 temp registers up from 12) and longer length shaders (somewhere between 512 and 1536 depending on what's being done) available to developers on R420, the number of internal registers has increased and the maximum number of pixels in flight has increased. These facts are really important in understanding performance. The fundamental layout of the pixel pipelines in R420 and NV40 are not that different, but the underlying hardware is where the power comes from. In this case, the number of internal pipeline stages in each pixel pipeline, and the ability of the hardware to hide the latency of a texture fetch are of the utmost importance.
The bottom line is that R420 has the potential to execute more PS 2.0 instructions per clock than NVIDIA in the pixel pipeline because of the way it handles texturing. Even though NVIDIA's scheduler can help to allow more math to be done in parallel with texturing, NV40's texture and math parallelism only approaches that of ATI. Combine that with the fact that R420 runs at a higher clock speed than NV40, and even more pixel shader work can get done in the same amount of time on R420 (which translates into the possibility for frames being rendered faster under the right conditions).
Of course, when working with fp32 data, NV40 is doing 25% more "work" per operation, and it's likely that the support for fp32 from the front of the shader pipeline to the back contributes greatly to the gap in the transistor count (as well as performance numbers). When fp16 is enabled in NV40, internal register pressure is decreased, and less work is being done than in fp32 mode. This results in improved performance for NV40, but questions abound as to real world image quality from NVIDIA's compiler and precision optimized shaders (we are currently exploring this issue and will be following up with a full image quality analysis of now current generation hardware).
As an extension of the fp32 vs. fp24 vs. fp16 debate, NV40's support of Shader Model 3.0 puts it at a slight performance disadvantage. By supporting fp32 all the way through the shader pipeline, flow control, fp16 to the framebuffer and all the other bells and whistles that have come along for the ride, NV40 adds complexity to the hardware, and size to the die. The downside for R420 is that it now lags behind on the feature set front. As we pointed out earlier, the only really new features of the R420 pixel shaders are: higher instruction count shader programs, 32 temporary registers, and a polygon facing register (which can help enable two sided lighting).
To round out the enhancements to the R420's pixel pipeline, ATI's F-Buffer has been tweaked. The F-Buffer is what ATI calls the memory that stores pixels that have come out of the pixel shader but still require another pass (or more) thorough the pixel shader pipeline in order to finish being processed. Since the F-Buffer can require anywhere from no memory to enough memory to handle every pixel coming down the pipeline, ATI have built "improved" memory management hardware into the GPU rather than relegating this task to the driver.








95 Comments
View All Comments
raks1024 - Monday, January 24, 2005 - link
free ati x800: http://www.pctech4free.com/default.aspx?ref=46670Ritalinkid - Monday, June 28, 2004 - link
After reading almost all of the video cards reviews posted on anandtech I start to get the feeling the anandtech has a grudge against nvidia. The reviews seem to put nvidia down no matter what area they excel in. With leading openGL support, ps3.0 support, and the 6850 shadowing the x800 in directX, its seems like nvidia should not be counted out as the "best card."I would love to see a review that tested all the features that both cards offered especially if showed the games that would benefit the most from each cards features (if they are available). Maybe then could I decide which is better, or which could benefit me more.
BlackShrike - Saturday, May 8, 2004 - link
Hey if anyone is gonna be buying one of these new cards, would anyone want to sell their 9700 pro or 9800 por/Xt for like 100-150 bucks? If you do contact me at POT989@hotmail.com. Thanks.DonB - Saturday, May 8, 2004 - link
No TV tuner on this card either? Will there be an "All-In-Wonder" version soon that will include it?xin - Friday, May 7, 2004 - link
(my bad, I didn't notice that I was on the first page of the posts, and replied to a message there heh)Well, since everyone else is throwing their preferences out there... I guess I will too. My last 3 cards have been ATI cards (9700Pro & 9500Pro, and an 8500 "Pro"), and I have not been let down. Right at this moment I lean towards the x800XT.
However, I am not concerned about power since I am running a TruePower550, and I will be interested in seeing what happens with all of this between now and the next 4-6 weeks when these cards actually come to market... and I will make my decision then on which card to buy.
xin - Friday, May 7, 2004 - link
Besides that, even if it were true (which it isn't), there is a world of difference between have *some* level of support, and requiring it. (*some* meaning the intial application of PS3.0 technology to games, that will likely be as sloppy as your first time in the back of a car with your first girlfriend).
Game makers will not require PS3.0 support for a long long long time... because it would alienate the vast majority of the people out there, or at least for the time being any person who doesn't have a NV40 card.
Some games may implement it and look slightly better, or even still look the same only run faster while looking the same.... but I would put money down that by the time PS3.0 usage in games comes anywhere close to mainstream, both mfg's will have their new, latest and greatest cards out, probably a 2 generations or more past these cards.
xin - Friday, May 7, 2004 - link
first of all... "alot of the upcoming topgames will support PS3.0!" ??? They will? Which ones exactly?
Z80 - Friday, May 7, 2004 - link
Good review. Pretty much tells me that I can select either Nvidia or ATI with confidence that I'm getting alot of "bang for my buck". However, my buck bang for video cards rarely exceeds $150 so I'm waiting for the new low to mid range cards before making a purchase.xin - Friday, May 7, 2004 - link
I love how a handful of stores out there feel the need to rip people off by charing $500+ for the x800PRO cards, since the XT isn't available yet.
Anyway, something interesting I noticed today:
http://www.compusa.com/products/product_info.asp?p...
http://www.compusa.com/products/product_info.asp?p...
Notice the "expected ship date"... at least they have their pricing right.
a2y - Friday, May 7, 2004 - link
Trog, I Also agree, the thing is.. its true i do not have complete knowledge of deep details of video cards.. u see my current video card is now 1 year old (Geforce4 mx440) which is terrible for gaming (50fps and less) and some games actually do not support it (like deusEX 2). I wanted a card that would be future proof, every consumer would go thinking this way, I do not spend everything i earned, but to me and some others $400-$500 is O.K. If it means its going to last a bit longer.I especially worry about the technology used more than the other specs of the cards, more technologies mean future games are going to support it. I DO NOT know what i'v just said actually means, but I fealt it during the past few years and have been affected by it right now (like the deus ex 2 problem!) it just doesn't support it, and my card performs TERRIBLY in all games
now my system is relatively slow for hardcore gaming:
P4 2.4GHz - 512MB RDRAM PC800 - 533MHz FSB - 512KB L2 Cache - 128MB Geforce4 mx440 card.
I wanted a big jump in performance especially in gaming so thats why i wanted the best card currently available.