Original Link: https://www.anandtech.com/show/2580
Intel's Larrabee Architecture Disclosure: A Calculated First Move
by Anand Lal Shimpi & Derek Wilson on August 4, 2008 12:00 AM EST- Posted in
- GPUs
Introduction
Oooh this is dangerous.
It started with Intel quietly (but not too quietly) informing many in the industry of its plans to enter the graphics market with something called Larrabee.
NVIDIA responded by quietly (but not too quietly) criticizing the nonexistant Larrabee.
What we've seen for the past several months has been little more than jabs thrown back and forth, admittedly with NVIDIA being a little more public with its swings. Today is a big day, without discussing competing architectures, Intel is publicly unveiling, for the first time, the basis of its Larrabee GPU architecture.

Well, it is important to keep in mind that this is first and foremost NOT a GPU. It's a CPU. A many-core CPU that is optimized for data-parallel processing. What's the difference? Well, there is very little fixed function hardware, and the hardware is targeted to run general purpose code as easily as possible. The bottom lines is that Intel can make this very wide many-core CPU look like a GPU by implementing software libraries to handle DirectX and OpenGL.
It's not quite emulating a GPU as it is directly implementing functionality on a data-parallel CPU that would normally be done on dedicated hardware. And developers will not be limited to just DirectX and OpenGL: this hardware can take pure software renderers and run them as if the hardware was designed specifically for that code.
There is quite a bit here, so let's just jump right in.
The Design Experiment: Could Intel Build a GPU?
Larrabee is fundamentally built out of existing Intel x86 core technology, which not only means that the chip design isn't foreign to Intel, but also has serious implications for the future of desktop microprocessors. Larrabee isn't however built on Intel's current bread and butter, the Core architecture, instead Intel turned to a much older architecture as the basis for Larrabee: the original Pentium.
The original Pentium was manufactured on a 0.80µm process, later shrinking to 0.60µm. The question Intel posed was this: could an updated version of the Pentium core, built on a modern day process and equipped with a very wide vector unit, make a solid foundation for a high-end GPU?
To first test the theory Intel took a standard Core 2 Duo, with a 4MB L2 cache at an undisclosed clock speed (somewhere in the 1.8 - 2.9GHz range I'd guess). Then, on the same manufacturing process, roughly the same die area and power consumption, Intel sought to find out how many of these modified Pentium cores it could fit. The number was 10.
So in the space of a dual-core Core 2 Duo, Intel could construct this hypothetical 10-core chip. Let's look at the stats:
| Intel Core 2 Duo | Hypothetical Larrabee | |
| # of CPU Cores | 2 out of order | 10 in-order |
| Instructions per Issue | 4 per clock | 2 per clock |
| VPU Lanes per Core | 4-wide SSE | 16-wide |
| L2 Cache Size | 4MB | 4MB |
| Single-Stream Throughput | 4 per clock | 2 per clock |
| Vector Throughput | 8 per clock | 160 per clock |
Note that what we're comparing here are operation throughputs, not how fast it can actually execute anything, just how many operations it can retire per clock.
Running a single instruction stream (e.g. single threaded application), the Core 2 can process as many as four operations per clock, since it can issue 4-instructions per clock and it isn't execution unit constrained. The 10-core design however can only issue two instructions per clock and thus the peak execution rate for a single instruction stream is two operations per clock, half the throughput of the Core 2. That's fine however since you'll actually want to be running vector operations on this core and leave your single threaded tasks to your Core 2 CPU anyways, and here's where the proposed architecture spreads its wings.
With two cores, each with their ability to execute 4 concurrent SSE operations per clock, you've got a throughput of 8 ops per clock on Core 2. On the 10-core design? 160 ops per clock, an increase of 20x in roughly the same die area and power budget.
On paper this could actually work. If you had enough of these cores, you could get the vector throughput necessary to actually build a reasonable GPU. Of course there are issues like adapting the x86 instruction set for use in a GPU, getting all of the cores to communicate with one another and actually keeping all of these execution resources busy - but this design experiment showed that it was possible.
Thus Larrabee was born.
Not Quite a Pentium, Not Quite an Atom: The Larrabee Core
Intel gave us enough information about Larrabee to begin a discussion of specifications, but not enough to even begin making any conclusions. We'll start with what we pretty much already know.
Intel's Larrabee is built out of a number of x86 cores that look, at a very high level, like this:
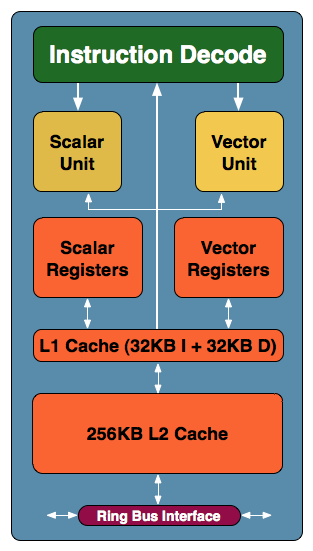
Each core is a dual-issue, in-order architecture loosely derived from the original Pentium microprocessor. The Pentium core was modified to include support for 64-bit operations, the updates to the x86 instruction set, larger caches, 4-way SMT/Hyper Threading and a 16-wide vector ALU.
While the team that ended up working on Atom may have originally worked on the Larrabee cores, there are some significant differences between Larrabee and Atom. Atom is geared towards much higher single threaded performance, with a deeper pipeline, a larger L2 cache and additional microarchitectural tweaks to improve general desktop performance.
| Intel Larrabee Core | Intel Pentium Core (P54C) | Intel Atom Core | |
| Manufacturing Process | 45nm | 0.60µm | 45nm |
| Simultaneous Multi-Threading | 4-way | 1-way | 2-way |
| Issue Width | dual-issue | dual-issue | dual-issue |
| Pipeline Depth | 5-stages (?) | 5-stages | 16-stages |
| Scalar Execution Resources | 2 x Integer ALUs (?) 1 x FPU (?) | 2 x Integer ALUs 1 x FPU | 2 x Integer ALUs 1 x FPU |
| Vector Execution Resources | 16-wide Vector ALU | None | 1 x SIMD SSE |
| L1 Cache (I/D) | 32KB/32KB | 8KB/8KB | 32KB/24KB |
| L2 Cache | 256KB | None (External) | 512KB |
| ISA | 64-bit x86 SSEn support? Parallel/Graphics? | 32-bit x86 | 64-bit x86 Full Merom ISA compatibility |
Larrabee on the other hand is more Pentium-like to begin with; Intel states that Larrabee's execution pipeline is "short" and followed up with us by saying that it's closer to the 5-stage pipeline of the original Pentium than the 16-stage pipeline of Atom. While both Atom and Larrabee support SMT (Simultaneous Multi-Threading), Larrabee can work on four threads concurrently compared to two on Atom and one on the original Pentium.
L1 cache sizes are similar between Larrabee and Atom, but Larrabee gets a full 32KB data cache compared to 24KB on Atom. If you remember back to our architectural discussion of Atom, the smaller L1 D-cache was a side effect of going to a register file instead of a small signal array for the cache. Die size increased but operating voltage decreased, forcing Atom to have a smaller L1 D-cache but enabling it to reach lower power targets. Larrabee is a little less constrained and thus we have conventional balanced L1 caches, at 4x the size of that in the original Pentium.
The Pentium had no on-die L2 cache, it relied on external SRAM to be installed on the motherboard. In order to maintain good desktop performance Atom came equipped with a 512KB L2 cache, while each Larrabee core will feature a 256KB L2 cache. Larrabee's architecture does stress the importance of large, fast caches as you'll soon see, but 256KB is the right size for Intel's architecture at this point. Larrabee's default OpenGL/DirectX renderer is tile based and it turns out that most 64x64 or 128x128 tiles with 32-bit color/32-bit Z can fit in a 128KB space, leaving an additional 128KB left over for caching additional data. And remember, this is just on one Larrabee core - the whole GPU will be built out of many more.
The big difference between Larrabee, Pentium and Atom is in the vector execution side. The original Pentium had no SIMD units, Atom added support for SSE and Larrabee takes a giant leap with a massive 16-wide vector ALU. This unit is able to work on up to 16 32-bit floating point operations simultaneously, making it far wider than any of the aforementioned cores. Given the nature of the applications that Larrabee will be targeting, such a wide vector unit makes total sense.
Other changes to the Pentium core that made it into Larrabee are things like 64-bit x86 support and hardware prefetchers, although it is unknown as to how these compare to Atom's prefetchers. It is a fair guess to say that prefetching will include optimizations for data parallel situations, but whether this is in addition to other prefetch technology or a replacement for it is something we'll have to wait to find out.
Drilling Deeper and Making the AMD/NVIDIA Comparison
Don't be fooled by the initial diagram, this simple x86 core gets far more complex. In the image below, the block to the left is the Larrabee core we mentioned earlier, to the right we've blown up the vector unit and its associated parts:
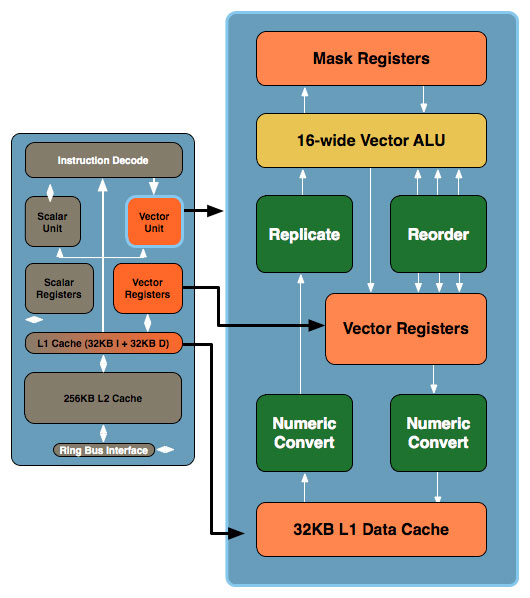
The vector unit is key and within that unit you've got a ton of registers and a very wide vector ALU, which leads us to the fundamental building block of Larrabee. NVIDIA's GT200 is built out of Streaming Processors, AMD's RV770 out of Stream Processing Units and Larrabee's performance comes from these 16-wide vector ALUs:
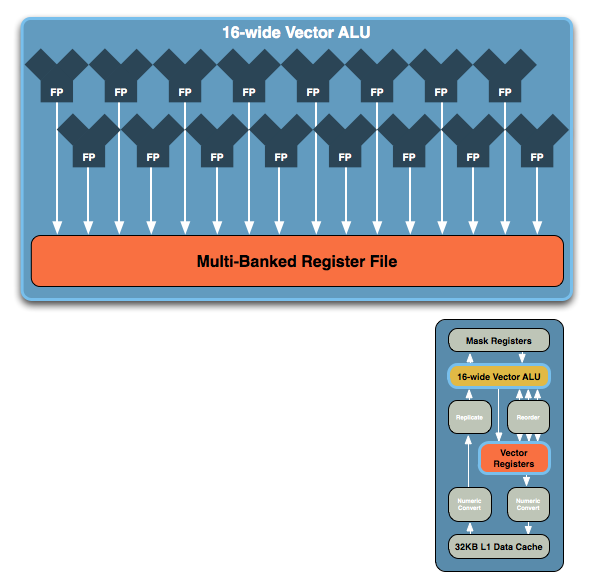
The vector ALU can behave as a 16-wide single precision ALU or an 8-wide double precision, although that doesn't necessarily translate into equivalent throughput (which Intel would not at this point clarify). Compared to ATI and NVIDIA, here's how Larrabee looks at a basic execution unit level:
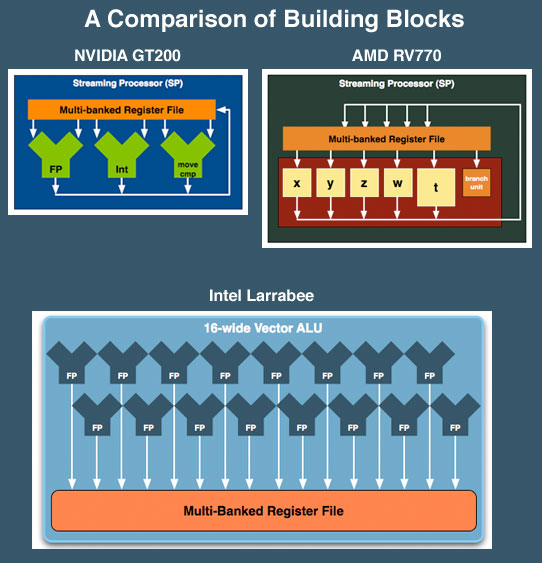
NVIDIA's SPs work on a single operation, AMD's can work on five, and Larrabee's vector unit can work on sixteen. NVIDIA has a couple hundred of these SPs in its high end GPUs, AMD has 160 and Intel is expected to have anywhere from 16 - 32 of these cores in Larrabee. If NVIDIA is on the tons-of-simple-hardware end of the spectrum, Intel is on the exact opposite end of the scale.
We've already shown that AMD's architecture requires a lot of help from the compiler to properly schedule and maximize the utilization of its execution resources within one of its 5-wide SPs, with Larrabee the importance of the compiler is tremendous. Luckily for Larrabee, some of the best (if not the best) compilers are made by Intel. If anyone could get away with this sort of an architecture, it's Intel.
At the same time, while we don't have a full understanding of the details yet, we get the idea that Larrabee's vector unit is sort of a chameleon. From the information we have, these vector units could exectue atomic 16-wide ops for a single thread of a running program and can handle register swizzling across all 16 exectution units. This implies something very AMD like and wide. But it also looks like each of the 16 vector execution units, using the mask registers can branch independently (looking very much more like NVIDIA's solution).
We've already seen how AMD and NVIDIA architectural differences show distinct advantages and disadvantages against eachother in different games. If Intel is able to adapt the way the vector unit is used to suit specific situations, they could have something huge on their hands. Again, we don't have enough detail to tell what's going to happen, but things do look very interesting.
Putting it all Together - Return of the Ring Bus
Intel is keeping two important details of Larrabee very quiet: the details of the instruction set and the configuration of the finished product. Remember that Larrabee won't ship until sometime in 2009 or 2010, the first chips aren't even back from the fab yet, so not wanting to discuss how many cores Intel will be able to fit on a single Larrabee GPU makes sense.
The final product will be some assembly of a multiple of 8 Larrabee cores, we originally expected to see something in the 24-to-32 core range but that largely depends on targeted die size as we'll soon explain:

Intel's own block diagrams indicated two memory controller partitions, but it's unclear whether or not we should read into this. AMD and NVIDIA both use 64-bit memory controllers and simply group multiples of them on a single chip. Given that Intel's Larrabee will be more memory bandwidth efficient than what AMD and NVIDIA have put out, it's quite possible that Larrabee could have a 128-bit memory interface, although we do believe that'd be a very conservative move (we'd expect a 256-bit interface). Coupled with GDDR5 (which should be both cheaper and highy available by the Larrabee timeframe) however, anything is possible.
All of the cores are connected via a bi-directional ring bus (512-bits in each direction), presumably running at core speed. Given that Larrabee is expected to run at 2GHz+, this is going to be one very high-bandwidth bus. This is half the bit-width of AMD's R600/RV670 ring bus, but the higher speed should more than make up the difference.
AMD recently abandoned their ring bus memory architecture citing a savings in die area and a lack of need for such a robust solution as the reason. A ring bus, as memory busses go, is fairly straight forward and less complex than other options. The disadvantage is that it is a lot of wires and it delivers high bandwidth to all the clients on the bus whether they need it or not. Of course, if all your memory clients need or can easily use high bandwidth then that's a win for the ring bus.
Intel may have a better use for going with the ring bus than AMD: cache coherency and inter-core communication. Partitioning the L2 and using the ring bus to maintain coherency and facilitate communication could make good use of this massive amount of data moving power. While Cell also allows for internal communication, Intel's solution of providing direct access to low latency, coherent L1 and L2 partitions while enabling massive bandwidth behind the L2 cache could result in a much faster and easier to program architecture when data sharing is required.
How Many Cores in a Larrabee?
Initial estimates put Larrabee at somewhere in the 16 to 32-core range, we figured 32-cores would be a sweetspot (not in the least because Intel's charts and graphs showed diminishing returns over 32 cores) but 24-cores would be more likely for an initial product. Intel however shared some data that made us question all of that.
Remember the design experiment? Intel was able to fit a 10-core Larrabee into the space of a Core 2 Duo die. Given the specs of the Core 2 Duo Intel used (4MB L2 cache), it appears to be a 65nm Conroe/Merom based Core 2 Duo - with a 143 mm^2 die size.
At 143 mm^2, Intel could fit 10 Larrabee-like cores so let's double that. Now we're at 286mm^2 (still smaller than GT200 and about the size of AMD's RV770) and 20-cores. Double that once more and we've got 40-cores and have a 572mm^2 die, virtually the same size as NVIDIA's GT200 but on a 65nm process.
The move to 45nm could scale as well as 50%, but chances are we'll see something closer to 60 - 70% of the die size simply by moving to 45nm (which is the node that Larrabee will be built on). Our 40-core Larrabee is now at ~370mm^2 on 45nm. If Intel wanted to push for a NVIDIA-like die size we could easily see a 64-core Larrabee at launch for the high end, with 24 or 32-core versions aiming at the mainstream. Update: One thing we did not consider here is power limitations. So while Intel may be able to produce a 64-core Larrabee with a GT200-like die-size, such a chip may exceed physical power limitations. It's far more likely that we'll see something in the 16 - 32 core range at 45nm due to power constraints rather than die size constraints.
This is all purely speculation but it's a discussion that was worth having publicly.
Cache and Memory Hierarchy: Architected for Low Latency Operation
Intel has had a lot of experience building very high performance caches. Intel's caches are more dense than what AMD has been able to produce on the x86 microprocessor front, and as we saw in our Nehalem preview - Intel is also able to deliver significantly lower latency caches than the competition as well. Thus it should come as no surprise to anyone that Larrabee's strengths come from being built on fully programmable x86 cores, and from having very large, very fast coherent caches.
Each Larrabee core features 4x the L1 caches of the original Pentium. The Pentium had an 8KB L1 data cache and an 8KB L1 instruction cache, each Larrabee core has a 32KB/32KB L1 D/I cache. The reasoning is that each Larrabee core can work on 4x the threads of the original Pentium and thus with a 4x as large L1 the architecture remains balanced. The original Pentium didn't have an integrated L2 cache, but each Larrabee core has access to its own L2 cache partition - 256KB in size.
Larrabee's L2 pool increases with each core. An 8-core Larrabee would have 2MB of total L2 cache (256KB per core x 8 cores), a 32-core Larrabee would have an 8MB L2 cache. Each core only has access to its L2 cache partition, it can read/write to its 256KB portion of the pool and that's it. Communication with other Larrabee cores happens over the ring bus; a single core will look for data in its L2 cache, if it doesn't find it there it will place the request on the ring bus and will eventualy find the data in its L2.
Intel doesn't attempt to hide latency nearly as much as NVIDIA does, instead relying on its high speed, low latency caches. The ratio of compute resources to cache size is much lower with Larrabee than either AMD or NVIDIA's architectures.
| AMD RV770 | NVIDIA GT200 | Intel Larrabee | |
| Scalar ops per L1 Cache | 80 | 24 | 16 |
| L1 Cache Size | 16KB | unknown | 32KB |
| Scalar ops per L2 Cache | 100 | 30 | 16 |
| L2 Cache Size | unknown | unknown | 256KB |
While both AMD and NVIDIA are very shy on giving out cache sizes, we do know that RV670 had a 256KB L2 for the entire chip cache and can expect that RV770 to have something larger, but not large enough to come close to what Intel has with Larrabee. NVIDIA is much closer in the compute-to-cache ratio than AMD, which makes sense given its approach to designing much larger GPUs, but we have no reason to believe that NVIDIA has larger caches on the GT200 die than Intel with Larrabee.
The caches are fully coherent, just like they are on a multi-core desktop CPU. The fully coherent caches makes for some interesting cases when looking at multi-GPU configurations. While Intel wouldn't get specific with multi-GPU Larrabee plans, it did state that with a multi-GPU Larrabee setup Intel doesn't "expect to have quite as much pain as they [AMD/NVIDIA] do".
We asked whether there was any limitation to maintaining cache coherence across multiple chips and the anwswer was that it could be possible with enough bandwidth between the two chips. While NVIDIA and AMD are still adding bits and pieces to refine multi-GPU rendering, Intel could have a very robust solution right out of the gate if desired (think shared framebuffer and much more efficient work load division for a single frame).
Programming for Larrabee
The Larrabee programming model is what sets it apart from the competition. While competing GPU architectures have become increasingly programmable over the years, Larrabee starts from a position of being fully programmable. To the developer, it appears as exactly what it is - an arrangement of fully cache coherent x86 microprocessors. The first iteration of Larrabee will hide this fact from the OS through its graphics driver, but future versions of the chip could conceivably populate task manager just like your desktop x86 cores do today.
You have two options for harnessing the power of Larrabee: writing standard DirectX/OpenGL code, or writing directly to the hardware using Larrabee C/C++, which as it turns out is standard C (you can use compilers from MS, Intel, GCC, etc...). In a sense, this is no different than what NVIDIA offers with its GPUs - they will run DirectX/OpenGL code, or they can also run C-code thanks to CUDA. The difference here is that writing directly to Larrabee gives you some additional programming flexibility thanks to the GPU being an array of fully functional x86 GPUs. Programming for x86 architectures is a paradigm that the software community as a whole is used to, there's no learning curve, no new hardware limitations to worry about and no waiting on additional iterations of CUDA to enable new features. You treat Larrabee like you treat your host CPU.
Game developers aren't big on learning new tricks however, especially on an unproven, unreleased hardware platform such as Larrabee. Larrabee must run DirectX/OpenGL code out of the box, and to do this Intel has written its own Larrabee native software renderer to interface between DX/OGL and the Larrabee hardware.
In AMD/NVIDIA GPUs, DirectX/OpenGL instructions map to an internal GPU instruction set at runtime. With Larrabee Intel does this mapping in software, taking DX/OGL instructions, mapping them to its software renderer, and then running its software renderer on the Larrabee hardware.
This intermediate stage should incur a performance penalty, as writing directly to Larrabee is always going to be faster. However Intel has apparently produced a highly optimized software renderer for Larrabee, once that's efficient enough so that any performance penalty introduced by the intermediate stage is made up for by the reduction of memory bandwidth enabled by the software renderer (we'll get to how this is possible in a moment).
Developers can also use a hybrid approach to Larrabee development. Larrabee can run standard DX/OGL code but if there are features developers want to implement that aren't enabled in the current DirectX version, they can simply write those features that they want in Larrabee C/C++.
Without hardware it's difficult to tell exactly how well Larrabee will run DirectX/OpenGL code, but Intel knows it must succeed on running current games very well in order to make this GPU a success.
A Tribute to Michael Abrash: The ISA
Some people idolize athletes. Others gravitate towards entertainers. While Derek is a hockey fan and a musician who loves watching movies, his real passion lead him in a different direction. And he's also going to devolve into first person singular for a minute to tell you a little more about that.
At the time I was a high school student who needed a good project outside the curriculum to teach to our C++ programming class (this was another one of the excellent projects Jo Adams set her students upon). My good friend Tom Macleod and I had just learned enough calculus and advanced geometry to be dangerous: we decided to write a 3D graphics engine in order to learn and teach graphics programming to the class.
To support this endeavor, I spent a bit of cash (well, my parent's cash anyway) on some graphics and game programming books for the occasion, and the one that really stood out (the one that set the course of my life) was Michael Abrash's Graphics Programming Black Book Special Edition. This giant tome contained quite a bit of collected wisdom regarding the art and science of code optimization and graphics programming as well as some great details about the development of Quake.
Not only was his book an incredible source of information and inspiration for me personally, but if there was ever an x86 assembly guru and graphics programming god that could help take the design of an instruction set architecture for Larrabee to a whole other dimension, it is Michael Abrash. And our information indicates that he has done just that.
This isn't to say that others on the Larrabee team don't deserve a spotlight; it's just exciting to see the guy who got me hooked on computer graphics programming (which lead to my interest in hardware) show up on such an impressive graphics hardware design team.
For those who haven't idolized Abrash, his Wikipedia entry helps explain his luminary status in the game industry:
"Michael Abrash is a highly regarded technical writer, and one of the top optimization and 80x86 assembly language programmers, a reputation cemented by his 1990 book Zen of Assembly Language Volume 1: Knowledge. Before getting into technical writing, Abrash was a game programmer, having written his first commercial game in 1982. After working at Microsoft on graphics and assembly code for Windows NT 3.1, he returned to the game industry in the mid-1990s to work on Quake for id Software. Some of the technology behind Quake is documented in Abrash's Graphics Programming Black Book. After Quake was released, Abrash returned to Microsoft to work on natural language research, then moved to the Xbox team, until 2001. In 2002, Abrash went to work for RAD Game Tools, where he co-wrote the advanced Pixomatic software renderer, which emulates the functionality of a DirectX 7-level graphics card and is used as the software renderer in such games as Unreal Tournament 2004."
Intel brought Abrash on as a consultant to help define the Larrabee instruction set. For the longest time, extensions to x86 (e.g. SSE4) were done by Intel engineers at the request of the software community. With every iteration of SSE the game industry was always happier but never truly satisfied with the extensions to x86 that Intel introduced. When Intel set out to define the extensions to x86 that would be used in Larrabee, it sought out visionaries within the game industry to help define that spec rather than creating hardware and defining the ISA internally. One thing we've consistently heard from game developers about Larrabee is that the ISA makes more sense than any other approach they have seen from ATI or NVIDIA. Larrabee's ISA was designed in part by the game industry, for that very industry.
Interestingly enough, while reluctant to go into details about the Larrabee ISA itself, Intel did tell us that fewer than 5% of the instructions are graphics specific. What they found is that creating overly specialized instructions doesn't always do that much good as they can be hard for compilers to use effectively and difficult to hand optimize with as well. Rather, having a good selection of generally applicable and powerful instructions is a better way to go.
One of the advantages of developing the compiler in parallel with the ISA itself is that they can easily test and adapt both as needed to understand how best to balance the ISA. As the vast majority of developers will rely on compilers to generate highly performant code, making sure the ISA is a good fit for compilers is essential. At the same time, because of the renewed interest in software graphics engines Larrabee is stirring up in the Old Guard of real-time 3D computer graphics, having icons like Michael Abrash on the team will help make sure that the ISA is not only compiler friendly but will also be attractive to those who wish to achieve Zen through assembly optimization.
Which brings us to an interesting point.
The Awesome Potential of Fully Programmable Graphics
Certainly we can't judge the applicability and impact Larrabee will have until we see how it handles real-world applications. But we absolutely cannot write off such a giant as Intel when they throw their chips into the pot. Some of the current graphics hardware establishment have tried to suggest to us that Intel is not in touch with the current development community and that the only reason some developers are excited about the extensive low level programmability of Larrabee is because they are nostalgic for the old days of graphics programming where it was all about the software renderer.
I don't think anyone is under the illusion that DirectX and OpenGL performance are irrelevant for Larrabee. If Intel fails at delivering equivalent or greater price/performance in games and applications that use these programming APIs, then no matter how well the hardware could be used for any software engine it will fail. But the potential to customize every part of the rendering pipeline, the capability of supporting a software renderer with the same level of performance as if the hardware was customized to it, adds a level of value to the development community that will absolutely blow away anything NVIDIA or AMD can currently (or will for the foreseeable future) offer.
Re-opening the door for Tim Sweeney, John Carmack, Michael Abrash, and other pioneers and visionaries in the field of 3D graphics to once again have the freedom to take a piece of hardware that can offer the kind of data parallel speed that has heretofore been limited to the GPU and literally do anything they want with it is something to be excited about. Limited much less by the physical design of the hardware to once again only be limited by the performance of any given segment of code could help speed up the transition from SIGGRAPH to games. Larrabee could help create a new wellspring of research, experimentation and techniques for real-time graphics, the likes of which have not been seen since the mid-to-late 1990s.
We have absolutely been seeing the current graphics hardware giants move toward more flexibility and programmability. But if Intel is able to effectively leap-frog their slow trudge toward true general purpose programming DX version by DX version, we will see the end of an era where games are feature limited by hardware. No longer will we need new hardware to handle a new DX version with new techniques and effects: we would only need a driver update to add support for the new API. The only obstacle to running games using future APIs will be performance. The only reason to upgrade in the future will be speed. It will be a different world, altogether different than anything we've known or experienced before yet incredibly similar to the roots from which the industry was born.
It is an exciting time to be in the field of computer graphics.
Thread and Data Management: It's Time to Blow Your Mind
With both the recent NIVIDA and AMD graphics hardware launches, we spent quite a bit of time talking about thread management. Since Larrabee is designed to be more of a collection of general purpose scalar and vector processing units, and vertex, primitive and pixel data (along with associate shader programs) are software managed. As we discussed what a context is for AMD and NVIDIA graphics hardware, a true context is going to be a different thing altogether on Larrabee.
We do have to make a point of saying before proceeding that NVIDIA and AMD are under no obligation to actually tell us how their architecture is physically implemented. It is entirely possible that much of the attributes of the hardware are not actually attributes of the hardware but simply reflections of how hardware resources are used. In recent discussions with both companies about certain realities of their hardware revealed to us that the belief is if the system behaves like a specific physical implementation then it effectively is the same as that physical implementation.
Of course, we disagree. And it is possible that some of this has more similarity with NVIDIA and AMD than they are letting on. But we'll go on what we've got for now, and assume that what Intel is doing is as divergent as it sounds.
Each Larrabee core on a chip (of which it seems likely there will be some multiple of 8 in the final product) can maintain 4 simultaneous software threads (4 contexts are kept active at a time). This gives the appearance of 4 virtual physical processors to software running directly on the hardware even though all four threads are sharing a single resource. It is very likely that the major purpose of this is to hide some of the long latency we hit when going to memory for texture data and the like.
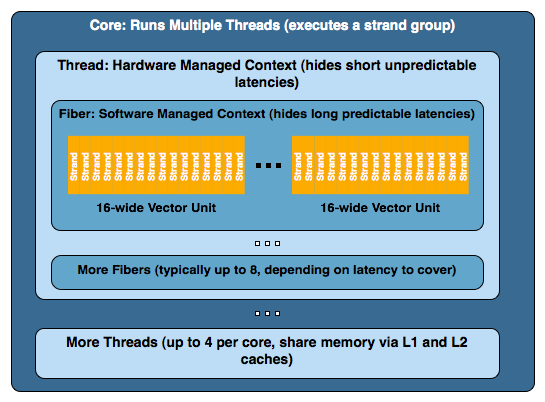
Now, for the purpose of graphics rendering using Intel's software rendering library or as it emulates DirectX and OpenGL, a thread is set up to manage the resources for a larger group of instructions and data that Intel calls a "fiber". Normally a thread will manage 8 fibers at a time. The hardware thread maintains a context in software for the fiber. The fiber's job is to manage the execution data parallel kernels on multiple groups of 16 "strands" (because the vector processor is 16-wide). A strand is what we have traditionally called a thread on other graphics hardware. The problem here is that Intel hardware is actually executing threads in a way that emulates hardware features of other architectures.
To put it together a little better, imagine one of Intel's threads as one of NVIDIA's TPCs, a fiber as an SM, and a strand as a thread. Okay, so it isn't that simple (simple?). But it is a sort of rough way of looking at it and a quick way of understand why naming is different here.
Let's take a deeper look at what goes on. With 4 threads per core (with at least 8 and hopefully something more like 32 cores), 8 fibers per thread, and some multiple of 16 strands per fiber, we could end up with a huge number of strands being managed simultaneously. This is active, running threads we are looking at as well. Since Larrabee will be a CPU in a true sense of the term, we can have as many threads as necessary live and waiting for a time slice. In the context of a normal CPU, this would be managed by the operating system, but as Larrabee will see the light of day as a graphics card, the driver will probably be managing timesharing issues an OS would normally perform.
While running ridiculous numbers of threads per core at a time might kill performance, unlike current GPUs, resource availability doesn't disrupt the creation of threads. Six of one, half dozen of the other? Maybe, and maybe not. Having active threads with data available to context switch to is key to hiding latency in NVIDIA and AMD hardware. If enough threads cannot be actively maintained, stalls happen and kill performance. Similar issues will impact Intel, and keeping dual-issue in-order hardware busy with multiple threads might be more easily managed if it can fall back on traditional CPU thread management paradigms to handle an abundance of threads that manage software that manages data parallel kernels.
Building an Optimized Rasterizer for Larrabee
We've touched on the latency focus. We talked about caches and internal memory busses. But what about external memory? To be honest, the answer is that we don't know. But we have an idea of the direction they want to move in. Lower external bandwidth and possibly lower framebuffer size than traditional hardware seems to be the goal. If they can maintain good performance, reducing the amount of memory and the number of traces on the board will reduce the cost to add-in card vendors who may want to sell cards based on Larrabee (and in turn could reduce cost to the end user).
This bit of speculation isn't just based on what we know about the hardware so far. It's also based on the direction they decided to take with their rasterizer: Intel is implementing a tile based rasterizer to support DirectX and OpenGL as well as their own software renderer. Speaking of their software renderer, they did state that it would be available for use by developers so that they don't have to start from nothing. When asked whether it would be available only as a set of binaries or as source, our answer was that this was still under discussion. We put in our two cents and suggested that distributing the source is the way to go.
Anyway, we haven't discussed tile based rasterization in quite a while on AnandTech as the Kyro line didn't stick around on the desktop. To briefly run it down, screen space is broken up into tiles. For each tile, primitives (triangles) are set aside. Fragments are created for a tile based on all the geometry therein. Since none of these fragments are further processed or shaded until the entire tile is finished, only visible fragments are sent on to be shaded (at least, this is how it used to be: some aspects of DX10+ may require occluded fragments to hang around in some cases). Occluded fragments are thrown out during rasterization. Intel does also support Z culling at geometry, fragment and pixel levels, which is also very useful as the actual rasterization, blending etc. must occur in software as well. Cutting down work at every point possible is the modus operandi of optimizing graphics.
This is in stark contrast to immediate mode renderers, which are what ATI and NVIDIA have been building for the past decade. Immediate mode rendering requires more memory bandwidth as it processes every fragment in the scene, sometimes even those that aren't visible (that can't easily be thrown out by pre-shading depth test techniques). Immediate mode renderers have some tricks that can let them know what fragments will be visible in the scene to help cut down on work, but there are still cases where the GPU does extra work that it doesn't need to because the fragment it is processing and shading isn't even visible in the scene. Immediate mode renderers require more memory bandwidth than tile based renderers, but some algorithms and features have been easier to implement with immediate mode.
STMicro had a short run of popular tile (or deferred) renderers in the early 2000s with the Kyro series. This style of rendering still lives on in cell phone/smart phone and other ultra low power devices that need graphics. While performance on this hardware is very low, memory efficiency is important in this space and thus tile based renderers are preferred.
The technique dropped out of the desktop space not because it was inherently unable to perform, but simply because the players that won out in the era didn't choose to make use of it. With smaller process technology, larger on die cache sizes, larger tiles sizes, and smaller geometry (meaning less triangles span multiple tiles), some advantages of tile based rendering have gotten ... well, more advantageous with advancements in technology.
Getting into the details of tile based rendering is a bit beyond where we want to go right now. But the point is that this technique results fewer occluded fragments end up being shaded. Additionally, the grouping of fragments into tiles helps with breaking up the workload and could help to optimize prefetching and caching so that fragments are only ever fetched once from external memory (tiles on Larrabee will fit into less than half the L2 space per core). These and other features help to reduce bandwidth needs compared to immediate mode renderers.
Looking a little deeper, it is both the burden and advantage of Larrabee that it implements all steps of the traditional graphics pipeline in software. While current GPUs have hardware for geometry setup, rasterization, texturing, filtering, compressing, decompressing, blending and much more, Larrabee maintains a minimum of fixed function features (related to texturing). Often, for a specific purpose, fixed function hardware can be more efficient and faster than general purpose hardware. But at the same time, the needs of individual games shift, and allocating greater or fewer resources to a specific component of the rendering pipeline does have advantages over fixed function hardware. Current GPUs can't shift resources to offer faster rasterization if needed. They can't devote more flops to speeding up stenciling or blending.
The flexibility of Larrabee allows it to best fit any game running on it. But keep in mind that just because software has a greater potential to better utilize the hardware, we won't necessarily see better performance than what is currently out there. The burden is still on Intel to build a part that offers real-world performance that matches or exceeds what is currently out there. Efficiency and adaptability are irrelevant if real performance isn't there to back it up.
Shading Tiles with Larrabee (With Extra Goodies)
We've looked at the way we get from triangles to tiles a bit. Intel shared a bit of a deeper look at how they are organizing their software render on the back end (from the tiles to the screen).
First, full tiles are fetched into cache. Reaching back to understanding how threads are organized, we can have four simulatneous threads running, and keeping all four of these threads working on parts of the same data set will help keep from thrashing the cache. Intel has indicated that the organization of software rendering threads durring back end processing will be as illustrated in the following diagram.
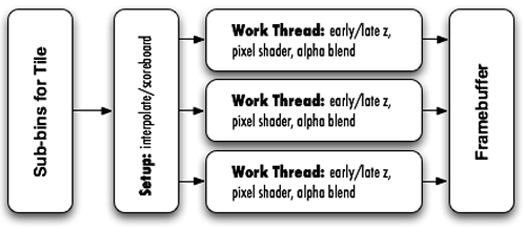
We see that there are 4 thread with one acting as a fragment setup thread which takes all the geometry in the tile and creating fragments from it for further processing. There are then three work threads that take ready fragments (or more like groups of 4 to 16 fragments each -- just a guess for now), check to see if they are visible, shade the fragment (load textures and run associated shader programs), perform any antialiasing and handle blend operations. Remember that this is all just software. It doesn't have to happen this way, but this is the direction Intel had indicated they have taken for their software renderer and for implementing DirectX and OpenGL.
By the time Larrabee arrives as a product, I certainly hope that we'll get a deeper look at what's really going on under the hood and how everything is organized. I suppose the holy grail would be if Intel decides to release it's software renderer source code to the general public, but even if we don't get that we'll try to get information on all the different types of threads, fibers and strands that are spawned to handle all the different steps in the rendering pipeline.
Beyond just taking traditionally fixed function features and running them in software, Intel can do a few cool things that are difficult with current hardware. In order to get layered transparency to work right, game developers need to sort objects and polygons as best then can from back to front (rendendering the furthest object to the screen first). If this isn't done, we can get some funky artifacts that don't look right. Since all this is software, Intel can do a few cool things to help developers out: where there is transparency, they can maintain an list of fragments at that screen position with z info attached rather than just blending or discarding data immediately. This way, when the blend is performed, it can be done properly no matter what order the geometry was rendered in.
Additionally, Irregular Z-buffers (which can allow for the creation of screen resolution shadow maps to avoid artifacts) and other complex data structures that can't easily or efficiently be implemented on traditional GPU hardware can be implemented on Larrabee without a second thought. Some of this stuff Intel can do on the back end to improve quality and performance in all applications, but some of it really won't make a difference until developers start to embrace the new architecture. And it's not just doing new things -- there are probably plenty of devs out there who would love to entirely skip the step of sorting their polygons when dealing with layered transparency.
The Future of Larrabee: The Many Core Era
I keep going back to this slide because it really tells us where Intel sees its architectures going:
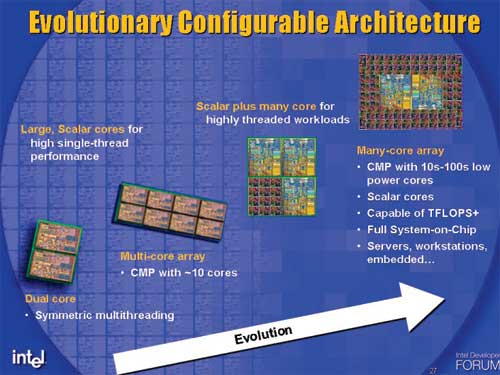
Today we're in the era of the multi-core array. Next year, Nehalem will bring us 8-cores on a single chip and it's conceivable that we'll see 10 and 12 core versions in the two years following it. Larrabee isn't actually on this chart, it remains separate until we hit the heterogeneous multi-threaded cores (the last two items on the evolutionary path).
It looks like future Intel desktop chips will be a mixture of these large Nehalem-like cores surrounded by tons of little Larrabee-like cores. Your future CPUs will be capable of handling whatever is thrown at them, whether that is traditional single-threaded desktop applications, 3D games, physics or other highly parallelizable workloads. It also paints an interesting picture of the future - with proper OS support, all you'd need for a gaming system would be a single Larrabee, you wouldn't need a traditional x86 CPU.
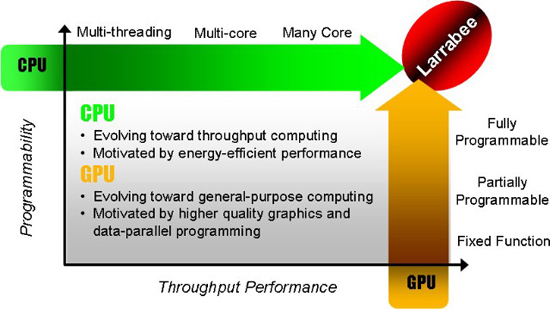
This future is a long time from now, but just as Pentium M eventually evolved into the future of desktop microprocessors from Intel today, keep an eye on Larrabee, because in 5 years it could be behind what you're running everything on.
Changing the Way GPUs Are Launched?
Here's an interesting thought. By the time Larrabee rolls out in 2009/2010, Intel's 45nm process will have been able to reach maturity. It's very possible that Intel could launch Larrabee much like it does its CPUs, with many SKUs covering a broad range of market segments. Intel could decide to launch $199 all the way up to $999 Larrabee parts, instead of the more traditional single GPU launch (perhaps with two SKUs) and waiting months before the technology trickles down to the mainstream.
Intel could take the GPU industry by storm and get Larrabee out into the wild quicker if it launched top to bottom, akin to how its CPU introductions work.
Things That Could Go Wrong
I had to write this section because as strong as Intel has been executing these past couple of years, we must keep in mind that in the GPU market, Intel isn't only the underdog, it's going up against the undefeated. NVIDIA, the company that walked into 3dfx's house and walked away with its IP, the company who could be out engineered and outperformed by ATI for an entire year and still emerge as dominant. This is Intel's competition, the most Intel-like of all of the manufacturers in the business, and a highly efficient one at that.
Intel may benefit from the use of its advanced manufacturing fabs in making Larrabee, but it is also burdened by them. NVIDIA has been building GPUs, some quite large, without ever investing a dime in building its own manufacturing facility. There's much that could go wrong with Larrabee, the short list follows:
Manufacturing, Design and Yield
Before we get to any of the GPU-specific concerns about Larrabee, there's always the basics when making any chip. There's always the chance that it could be flawed, it might not reach the right clock speeds, deliver the right performance and perhaps not yield well enough. Larrabee has a good chance of being Intel's largest die produced in desktop-like volumes, while Intel is good at manufacturing we can't rule these out as concerns.
Performance
As interesting as Larrabee sounds, it's not going to arrive for another year at least. NVIDIA should have even higher performing parts out by then, making GT200 look feebile by comparison. If Intel can't deliver a real advantage over the best from NVIDIA and AMD, Larrabee won't get very far as little more than a neat architecture.
Drivers and Developer Relations
Intel's driver team now is hardly its strongpoint. On the integrated graphics side we continue to have tons of issues, even as we're testing the new G45 platform we're still bumping into many driver related issues and are hearing, even from within Intel, that the IGP driver team leaves much to be desired. Remember that NVIDIA as a company is made up of mostly software engineers - drivers are paramount to making a GPU successful, and Intel hasn't proved itself.
I asked Intel who was working on the Larrabee drivers, thankfully the current driver team is hard at work on the current IGP platforms and not on Larrabee. Intel has a number of its own software engineers working on Larrabee's drivers, as well as a large team that came over from 3DLabs. It's too early to say whether or not this is a good thing, nor do we have any idea of what Intel's capabilities are from a regression testing standpoint, but architecture or not, drivers can easily decide the winner in the GPU race.
Developer relations are also very important. Remember the NVIDIA/Assassin's Creed/DirectX 10.1 fiasco? NVIDIA's co-marketing campaign with nearly all of the top developers is an incredibly strong force. While Intel has the clout to be able to talk to game developers, we're bound to see the clash of two impossibly strong forces here.
Final Words
Well, we've known it was coming for quite a while. We knew it would be a many-core CPU architecture well suited to graphics. And with as much information as we were given, when we sat down to look at what we had we felt like we still didn't know anything about Larrabee. Piles of data and information, insight into how a software render would fit on top of the underlying architecture... it has left us with the feeling that all this is a really cool idea with great potential, but we just don't have any idea what or how well it will do when it finally hits.
Of course, this is the first time any real detail has been given, and any hint of product is at least 12 to 18+ months off. We can't expect Intel to give everything away right off the bat. We are very happy to have the detail we do, and can't wait to get more.
While we are very interested in the architecture from the sort of technophile point of view that we can't help but have, technology for technology sake (no matter how cool the theory behind it might be) amounts to nothing without real-world application and benefit. For Larrabee it will all come down to peformance and price.
AMD has shown that you don't need to be on top to compete. As long as performance somewhere in the middle of the pack can be produced, appropriate and aggressive pricing can go quite a long way. For the consumer it is always a cost/benefit analysis, and there are quite a number of computers with $100 - $300 graphics cards under the hood. If compatibility is there, if performance is there, and if Intel is able to price it right, the first round of Larrabee hardware doesn't need to be ground breaking.
Getting a good foothold and sticking it out for the long haul should be Intel's goal. Compatibility (especially with the track record of Intel's integrated graphics) is likely more important than pure performance. Getting product out there into the market is necssary before developers will even start to take a chance on pushing the hardware itself. And this is where Larrabee could really shine.
Opening the door to fully programmable rendering and making it attractive enough for developers to start pushing the envelope will be a long process. The current game development arena is all about return on investment, and except for a few brave souls we will likely see game and engine developers stick to DirectX 10 for quite some time even after DX 11 comes along. Those who venture into the realm of pure software renderes written for a highly data-parallel CPU will be the exception rather than the norm.






