Original Link: https://www.anandtech.com/show/1618
AMD K8 E4 Stepping: SSE3 Performance
by Derek Wilson on February 17, 2005 12:05 AM EST- Posted in
- CPUs
Introduction
With this week's introduction of the x52 line of Opteron processors, AMD is giving us a little look into the future of their Athlon 64 line. As mentioned in our article on Monday, the new 2.6GHz speed grade is also introducing the new E4 stepping, which adds SSE3 support. The new Opteron also received a face lift in that it is fabbed on a 90nm process, runs coherent HT links at 1GHz, and comes in a shiny new organic package rather than the older ceramic.The goal of this article is to bring out a quick look at what SSE3 brings to the table for Opteron and the future revision E Athlon 64 cores. As desktop parts do not enable coherent HT links at all, the 1GHz support won't matter. Also, the newer A64 parts are already 90nm on organic packages. Other than the usual small tweaks we see between steppings, the only thing that will be new across the board for K8 processors is SSE3.
What exactly is SSE3? Intel introduced SSE3 as Prescott New Instructions last year. These instructions are generally additions to the SIMD (single instruction multiple data) capabilities of the processor. SIMD processing is based on the idea that sometimes processors must take large amounts of data and perform similar operations across the entire set. This lends itself well to things like audio and video processing. In these areas of computing, large amounts of data flow through the processor, undergoing roughly the same operations, in preparation for display. The philosophy behind SIMD lends itself well to graphics as well. Modern graphics cores incorporate many SIMD processing units in order to churn through vector and pixel data as fast as possible. SIMD processing has also largely overshadowed the use of the x87 floating point unit on x86 processors. Because of this, it is advantageous for AMD to support the extensions to SIMD Intel makes as quickly as possible.
With SSE3, Intel added 10 new instructions targeted at SIMD as well as 3 other instructions that don't touch the SSE registers (fisttp, monitor, mwait). Here's a brief list of SSE3 instructions and what they are for:
x87 floating point to integer conversion (fisttp)The float to integer conversion is rather obvious in function, but some of the other instructions are a little mysterious. The complex math instructions extend functionality for imaginary numbers. The hadd and hsub instructions are horizontal additions and horizontal subtractions. These allow faster processing of data stored "horizontally" in (for example) vertex arrays. Here is a 4-element array of vertex structures.
Complex arithmetic (addsubps, addsubpd, movsldup, movshdup, movddup)
Video encoding (lddqu)
Graphics (haddps, hsubps, haddpd, hsubpd)
Thread synchronization (monitor, mwait)
x1 y1 z1 w1 | x2 y2 z2 w2 | x3 y3 z3 w3 | x4 y4 z4 w4
SSE and SSE2 are organized such that performance is better when processing vertical data, or structures that contain arrays; for example, a vertex structure with 4-element arrays for each component:
x1 x2 x3 x4
y1 y2 y3 y4
z1 z2 z3 z4
w1 w2 w3 w4
Generally, the preferred organizational method for vertecies is the former. Under SSE2, the compiler (or very unfortunate programmer) would have to reorganize the data during processing. The lddqu instruction is designed to reduce the impact of 128bit unaligned memory accesses. As unaligned loads happen quite often in video processing, the lddqu instruction is designed to load 256bits of data aligned on a 16byte boundary. The instruction also takes care of extracting the correct 16bytes (as requested) from the 32byte block. Under SSE2, 64bit loads are executed and then the data is recombined.
In order to test these features as implemented by AMD, we tested an Opteron 250 against an Opteron 252. We were able to use crystalcpuid to set the multiplier of the Opteron 252 (though powernow!) to 12 in order to match the 2.4GHz of the Opteron 250. This way, we'll have a direct comparison of the two architectures.
We ran both processors in HP's wx9300 workstation. We used a single CPU configuration and 4x 512MB of RAM at 3:3:3:8. Windows XP SP2 was used in our tests. In an MP environment (with more memory bandwidth), the Opteron has a greater potential for improvement with SSE3. Unfortunately, we were unable to perform a direct comparison of the older and newer cores under a DP configuration. Attempting to use powernow! to adjust the multiplier with more than 1 processor installed resulted in a BSOD (machine check exception).
SSE3 Performance Analysis
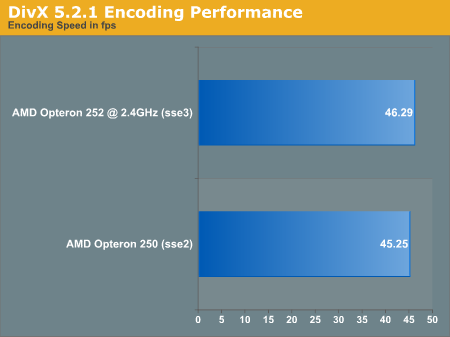
Before running these tests, we confirmed that SSE3 was enabled with the Opteron 252 through CPU-Z.The first test that we will look at is DivX encoding. We used DivX 5.2.1 with AutoGK 1.91 as a front end. Chapters 19, 20 and 21 of The Chronicles of Riddick were used as the test material for this analysis. We turned off audio and used the 75% quality setting.
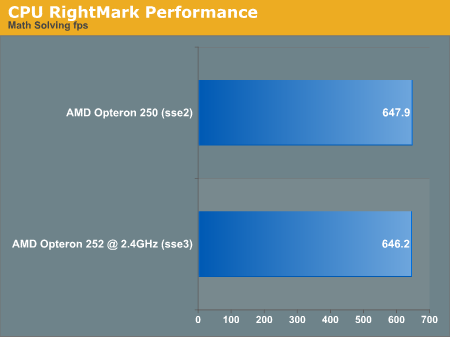
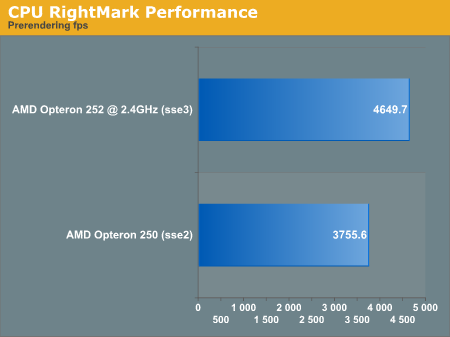
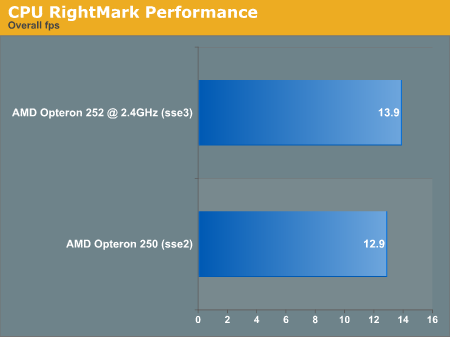
The second test that we looked at was purely synthetic. CPU RightMark uses the processor to manage the physics and rendering of a 3D scene. There are lots of configuration options, but we went with the default for each CPU that we tested (just start up the program and hit run). The highest level of floating point support is chosen automatically in each case (SSE2 for Opteron 250, and SSE3 for Opteron 252 @ 2.4GHz).
Final Words
Finding good SSE3 benchmarks wasn't as easy as we would have liked. Other encoding suites react the same way that DivX and AutoGK do. This seems to indicate that the K8 architecture is simply resilient when it comes to unaligned 128bit loads. In the case of Intel's NetBurst, the lddqu instruction may have more impact.As far as physics and graphics go, the added instructions show potential in our synthetic test. For DCC, CAD, scientific, and other workstation software, the E4 stepping could offer a bit of a performance boost.
In the consumer space, Athlon 64 may not see as much benefit from SSE3, especially since our encoding tests turned up so little performance impact. SSE3 can be used in games, but the impact of this will likely be minimal. As most games will likely remain graphics limited, improvements will have a hard time shining through. Of course, for those who like to use lower cost Athlon 64 processors in cheaper workstations, there could be some advantage.
When we take a look at the Opteron 252 in a workstation environment, we will be able to get a better view of what the total package has to offer. As our workstation tests will be in a DP environment, we'll be able to see how the higher bandwidth helps the Opteron shine.
We would like to have tested more applications in this report on SSE3 performance under the new AMD core. Of interest to us are LINPACK, FLOPS, STREAM, and various other tests that would require us to recompile them with proper SSE3 support. As the Intel compiler is designed to optimize for Intel processors, we haven't had a viable source for high quality SSE3 compilation. Hand optimizing these benchmarks for SSE3 on Opteron would take a little more time than this short investigation will allow. We may look into using GCC for this purpose in future tests. As for real world tests using SSE3, we haven't been able to find many suitable candidates beyond video encoders.
It will likely be the case that current SSE3 optimized code paths will also not show their strengths on Opteron/Athlon until the processors are in developers' hands for a while. The Intel compiler is also hands and feet above any resource AMD have up their sleeve. But since SSE3 offers more choices for optimization and code simplification, compilers may have an easier time generating efficient code. Hand optimized code is still important for tight loops in critical sections of performance oriented code. In this case, more powerful and simple options implemented in hardware will help programmers better optimize their own code.






