AMD Launches Carrizo: The Laptop Leap of Efficiency and Architecture Updates
by Ian Cutress on June 2, 2015 9:00 PM ESTIPC Increases: Double L1 Data Cache, Better Branch Prediction
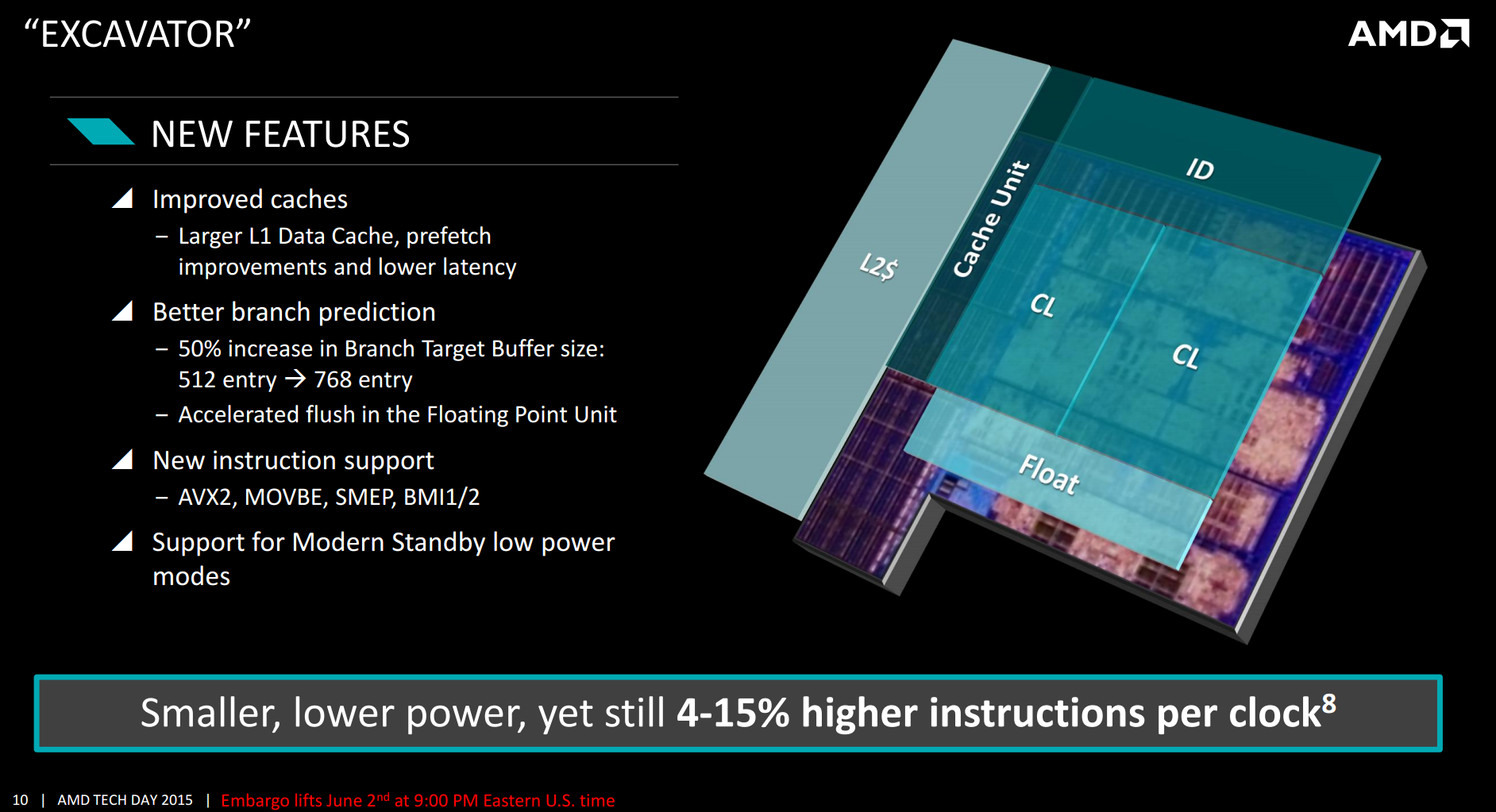
One of the biggest changes in the design is the increase in the L1 data cache, doubling its size from 64 KB to 128 KB while keeping the same efficiency. This is combined with a better prefetch pipeline and branch prediction to reduce the level of cache misses in the design. The L1 data cache is also now an 8-way associative design, but with the better branch prediction when needed it will only activate the one segment required and when possible power down the rest. This includes removing extra data from 64-bit word constructions. This reduces power consumption by up to 2x, along with better clock gating and minor adjustments. It is worth pointing out that doubling the L1 cache is not always easy – it needs to be close to the branch predictors and prefetch buffers in order to be effective, but it also requires space. By using the high density libraries this was achieved, as well as prioritizing lower level cache. Another element is the latency, which normally has to be increased when a cache increases in size, although AMD did not elaborate into how this was performed.
As listed above, the branch prediction benefits come about through a 50% increase in the BTB size. This allows the buffer to store more historic records of previous interactions, increasing the likelihood of a prefetch if similar work is in motion. If this requires floating point data, the FP port can initiate a quicker flush required to loop data back into the next command. Support for new instructions is not new, though AVX2 is something a number of high end software packages will be interested in using in the future.
These changes, according to AMD, relate to a 4-15% higher IPC for Excavator in Carrizo compared to Steamroller in Kaveri. This is perhaps a little more what we normally would expect from a generational increase (4-8% is more normal), but AMD likes to stress that this comes in addition to lower power consumption and with a reduced die area. As a result, at the same power Carrizo can have both an IPC advantage and a frequency advantage.
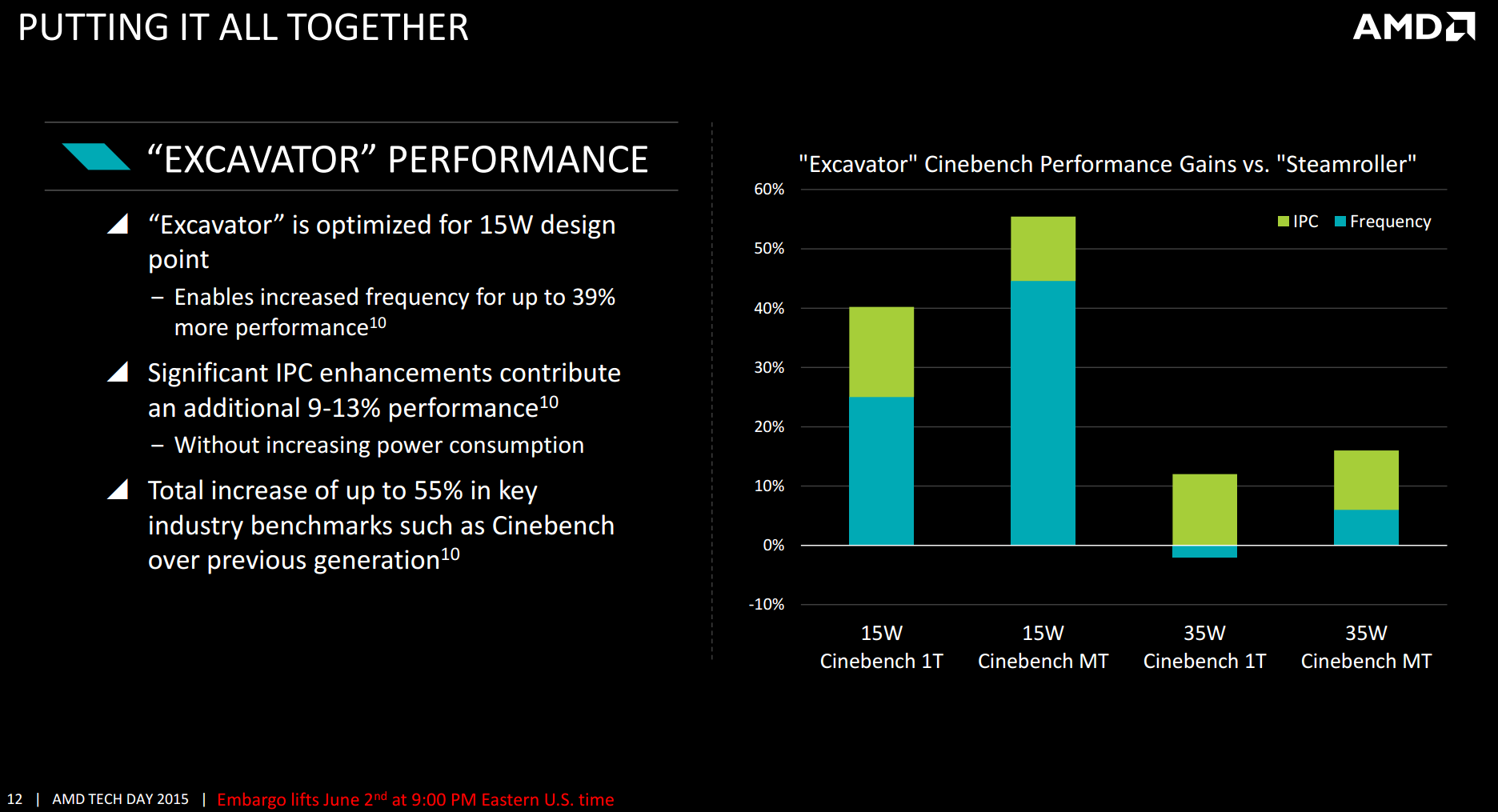
As a result, AMD states that for the same power, Cinebench single threaded results will go up 40% and multithreaded results up 55%. The benefits are fewer however the further up the power band you go despite the increase, as the higher density libraries perform slightly worse at higher power than Kaveri.








137 Comments
View All Comments
FlushedBubblyJock - Tuesday, June 9, 2015 - link
amazing how a critically correct comment turns into an angry ranting conspiracy from youBillyONeal - Wednesday, June 3, 2015 - link
This is a preview piece. They don't have empirical data because the hardware isn't in actual devices yet. Look at any of AT's IDF coverage and you'll see basically the exact same thing.Refuge - Wednesday, June 3, 2015 - link
nothing has been released yet. but it was announced. This is a news site, you think they are just going to ignore AMD's product announcement? That would be considered "Not doing their job"They go through the claims, explain them, try to see if they are plausible with what little information they have. I like these articles, it gives me something to digest while I wait for a in depth review, and when I go to read said review I know exactly what information I'm most interested in.
KaarlisK - Wednesday, June 3, 2015 - link
About adaptive clocking.Power is not saved by reducing frequency by 5% for 1% of the time.
Power is saved by reducing the voltage margin (increasing frequency at the same voltage) _all_ the time.
Also, when the voltage instability occurs, only frequency is reduced. The requested voltage, IMHO, does not change.
ingwe - Wednesday, June 3, 2015 - link
Interesting. That makes more sense for sure.name99 - Monday, June 8, 2015 - link
It seems like a variant of this should be widely applicable (especially if AMD have patents on exactly what they do). What I have in mind is that when you detect droop rather than dynamically change the frequency (which is hard and requires at least some cycles) you simply freeze the entire chip's clock at the central distribution point --- for one cycle you just hold everything at zero rather than transitioning to one and back. This will give the capacitors time to recover from the droop (and obviously the principle can be extended to freeze the clock for two cycles or even more if that's how long it takes for the capacitors to recover).This seems like it should allow you to run pretty damn close to the minimum necessary voltage --- basically all you now need is enough margin to ensure that you don't overdraw within a worst case single-cycle. But you don't need to provision for 3+ worst-case cycles, and you don't need the alternative of fancy check-point and recovery mechanisms.
KaarlisK - Wednesday, June 3, 2015 - link
About that power plane."In yet more effort to suction power out of the system, the GPU will have its own dedicated voltage plane as part of the system, rather than a separate voltage island requiring its own power delivery mechanism as before"
As I understand it, "before" = same power plane/island as other parts of the SoC.
Gadgety - Wednesday, June 3, 2015 - link
Great read and analysis given the fact that actual units are not available for testing.As a consumer looking for use of Carrizo beyond laptops, provided AMD releases it for consumers, it could be a nice living room HTPC/light gaming unit.
Laxaa - Wednesday, June 3, 2015 - link
I would buy a Dell XPS13-esque machine with this(i.e. high quality materials, good design and a high res screen)Will Robinson - Wednesday, June 3, 2015 - link
According to ShintelDK and Chizow...the above article results are from an Intel chip and AT have been paid to lie and say its Carrizo because their lives would have no meaning if it is a good product from AMD.