The Intel Xeon D Review: Performance Per Watt Server SoC Champion?
by Johan De Gelas on June 23, 2015 8:35 AM EST- Posted in
- CPUs
- Intel
- Xeon-D
- Broadwell-DE
Memory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readable we limited ourselves to the CPUs that were different.
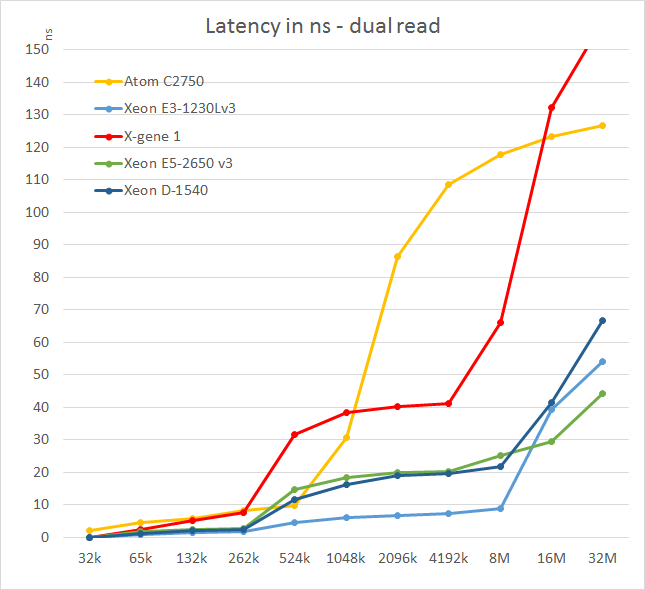
L3 caches have increased significantly the past years, but it is not all good news. The L3 cache of the Xeon E3 responds very quickly (about 10 ns or less than 30 cycles at 2.8 GHz) while the L3-cache of the new generation needs almost twice as much time to respond (about 20 ns or 50 cycles at 2.6 GHz). Larger L3 caches are not always a blessing and can result in a hit to latency - there are applications that have a relatively small part of cacheable data/instructions such as search engines and HPC application that work on huge amounts of data.
It gets worse for the "large L3 cache" models when we look at latency of accessing memory (measured at 64 MB):
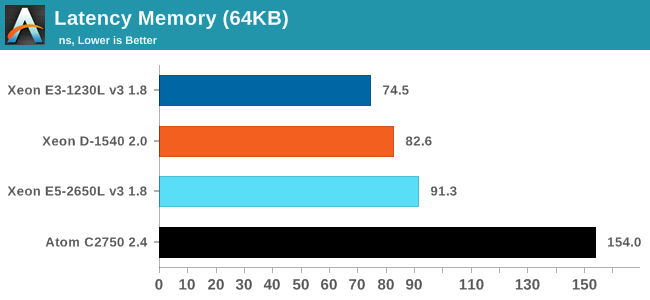
The higher L3-cache latency makes memory accesses more costly in terms of latency for the Xeon E5. Despite having access to DDR4-2133 DIMMs, the Xeon E5-2650L accesses memory slower than the Xeon E3-1230L. It is also a major weakness of the Atom C2750 which has much less sophisticated memory controller/prefetching.








90 Comments
View All Comments
extide - Tuesday, June 23, 2015 - link
That's ECC Registered, -- not sure if it will take that, but probably, although you dont need registered, or ECC.nils_ - Wednesday, June 24, 2015 - link
If you want transcoding, you might want to look at the Xeon E3 v4 series instead, which come with Iris Pro graphics. Should be a lot more efficient.bernstein - Thursday, June 25, 2015 - link
for using ECC UDIMMs, a cheaper option would be an i3 in a xeon e3 board.psurge - Tuesday, June 23, 2015 - link
Has Intel discussed their Xeon-D roadmap at all? I'm wondering in particular if 2x25GbE is coming, whether we can expect a SOC with higher clock-speed or more cores (at a higher TDP), and what the timeframe is for Skylake based cores.nils_ - Tuesday, June 23, 2015 - link
Is 25GbE even a standard? I've heard about 40GbE and even 56GbE (matching infiniband), but not 25.psurge - Tuesday, June 23, 2015 - link
It's supposed be a more cost effective speed upgrade to 10GbE than 40GbE (it uses a single 25Gb/s serdes lane, as used in 100GbE, vs 4 10Gb/s lanes), and IIRC is being pushed by large datacenter shops like Google and Microsoft. There's more info at http://25gethernet.org/. I'm not sure where things are in the standardization process.nils_ - Wednesday, June 24, 2015 - link
It also has an interesting property when it comes to using a breakout cable of sorts, you could connect 4 servers to 1 100GbE port (this is already possible with 40GbE which can be split into 4x10GbE).JohanAnandtech - Wednesday, June 24, 2015 - link
Considering that the Xeon D must find a home in low power high density servers, I think dual 10 Gbit will be standard for a while. Any idea what 25/40 Gbit PHY would consume? Those 10 Gbit PHYs already need 3 Watt in idle, probably around 6-8W at full speed. That is a large chunk of the power budget in a micro/scale out server.psurge - Wednesday, June 24, 2015 - link
No I don't, sorry. But, I thought SFP+ with SR optics (10GBASE-SR) was < 1W per port, and that SFP+ direct attach (10GBASE-CR) was not far behind? 10GBASE-T is a power hog...pjkenned - Tuesday, June 23, 2015 - link
Hey Johan - just re-read. A few quick thoughts:First off - great piece. You do awesome work. (This is Patrick @ ServeTheHome.com btw)
Second - one thing should probably be a bit clearer - you were not using a Xeon D-1540. It was a ES Broadwell-DE version at 2.0GHz. The shipping product has 100MHz higher clocks on both base and max turbo. I did see a 5% or so performance bump from the first ES version we tested to the shipping parts. The 2.0GHz parts are really close to shipping spec though. One both of my pre-release Xeon D and all of the post-release Xeon D systems was nearly identical.
Those will not change your conclusions but does make the actual Intel Xeon D-1540 a bit better than the one you tested. LMK if you want me to set aside some time on a full speed version on a Xeon D-1540 system for you.