Intel Xeon E5-2697 v2 and Xeon E5-2687W v2 Review: 12 and 8 Cores
by Ian Cutress on March 17, 2014 11:59 AM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
Scientific and Synthetic Benchmarks
2D to 3D Rendering –Agisoft PhotoScan v1.0: link
Agisoft Photoscan creates 3D models from 2D images, a process which is very computationally expensive. The algorithm is split into four distinct phases, and different phases of the model reconstruction require either fast memory, fast IPC, more cores, or even OpenCL compute devices to hand. Agisoft supplied us with a special version of the software to script the process, where we take 50 images of a stately home and convert it into a medium quality model. This benchmark typically takes around 15-20 minutes on a high end PC on the CPU alone, with GPUs reducing the time.
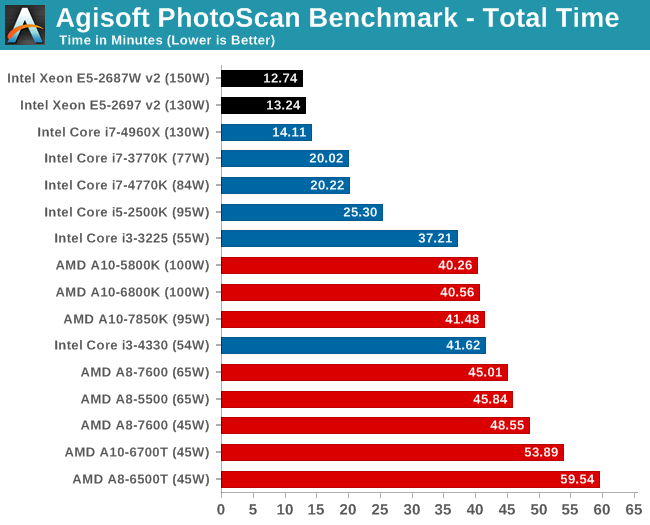
For PhotoScan, the extra cores and MHz from the Xeons means most in the first stage of the computation. The second stage shows an increas in CPU Mapping Speed, however this is the stage where the GPU can accelerate when in use. Stage 3 benefits more from the MHz of the 8-core model, and the final stage is about even.
Console Emulation –Dolphin Benchmark: link
At the start of 2014 I was emailed with a link to a new emulation benchmark based on the Dolphin Emulator. The issue with emulators tends to be two-fold: game licensing and raw CPU power required for the emulation. As a result, many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that raytraces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in minutes, where the Wii itself scores 17.53; meaning that anything above this is faster than an actual Wii for processing Wii code, albeit emulated.
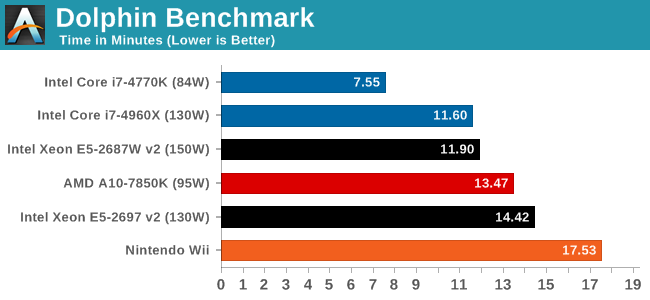
Emulation is a pure single threaded affair, and the IPC improvements of Haswell stand out a lot against the Ivy Bridge-E based Xeons.
Point Calculations – 3D Movement Algorithm Test: link
3DPM is a self-penned benchmark, taking basic 3D movement algorithms used in Brownian Motion simulations and testing them for speed. High floating point performance, MHz and IPC wins in the single thread version, whereas the multithread version has to handle the threads and loves more cores.
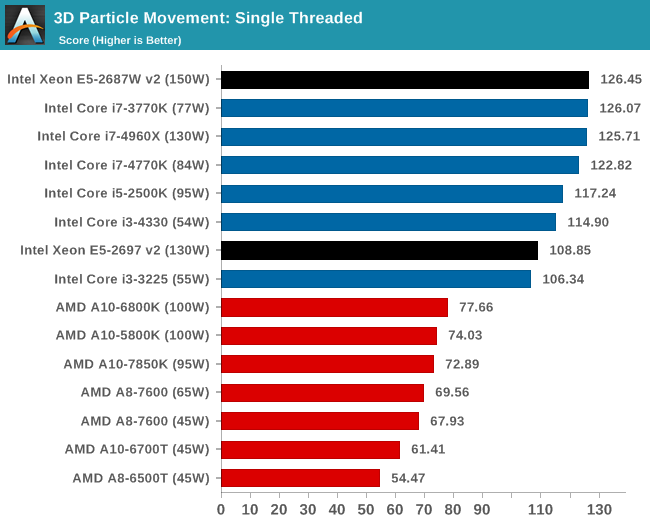
The low core frequency of the 12-core Xeon puts it behind in our FP single threaded benchmark.
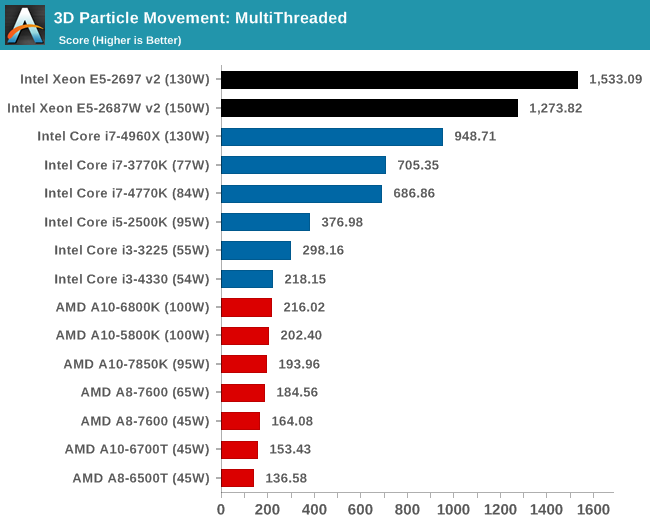
In out multithreaded scenario, we see the situation similar to PovRay, where cores and frequency take top spots.
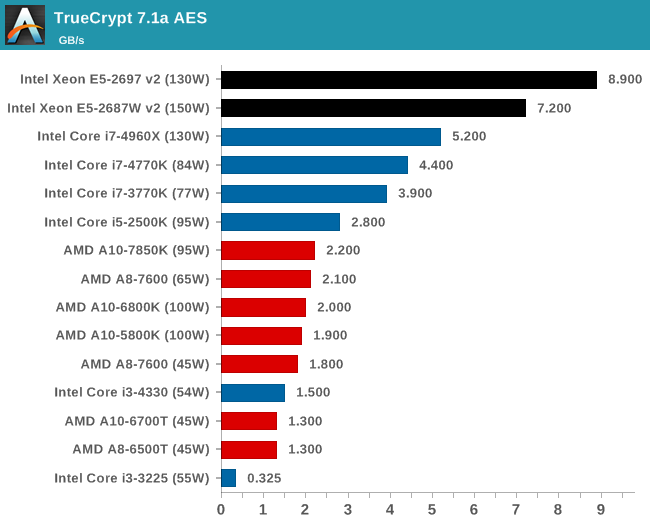
Encryption –TrueCrypt v0.7.1a: link
TrueCrypt is an off the shelf open source encryption tool for files and folders. For our test we run the benchmark mode using a 1GB buffer and take the mean result from AES encryption.
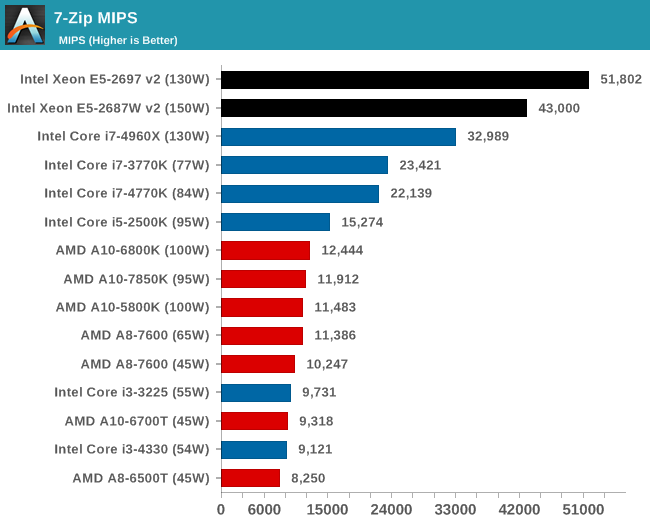
Synthetic – 7-Zip 9.2: link
As an open source compression tool, 7-Zip is a popular tool for making sets of files easier to handle and transfer. The software offers up its own benchmark, to which we report the result.








71 Comments
View All Comments
XZerg - Monday, March 17, 2014 - link
this bench also shows that the haswell had almost no CPU related performance benefits over IVB (if not slowed down performance) looking at 3770k vs 4770k and that haswell ups the gpu performance only.i really question intel's skuing of haswell...
Nintendo Maniac 64 - Monday, March 17, 2014 - link
Emulation?BMNify - Monday, March 17, 2014 - link
its a shame they didn't do a UHD x264 encode here as that would have shown a haswell AVX2 improvement (something like 90% over AVX), and why people will have to wait for the xeons to catch up to at least AVX2 if not AVX3.1psyq321 - Wednesday, March 19, 2014 - link
There is no "90% speedup over AVX" between HSW and IVB architectures.AVX (v1) is floating point only and thus was useless for x264. For floating point workloads you would be very lucky to get 10% improvement by jumping to AVX2. The only difference between AVX and AVX2 for floating point is the FMA instruction and gather, but gather is done in microcode for Haswell, so it is not actually much faster than manually gathering data.
Now, x264 AVX2 is a big improvement because it is an integer workload, and with AVX (v1) you could not do that. So x264 is jumping from SSE4.x to AVX2, which is a huge jump and it allows much more efficient processing.
For integer workloads that can be optimized so that you load and process eight 32-bit values at once, AVX2 Xeon EPs/EXs will be a big thing. Unfortunately, this is not so easy to do for a general-purpose algorithms. x264 team did the great job, but I doubt you will be using 14 core single Haswell EP (or 28 core dual CPU) for H.264 transcoding. This job can be done probably much more efficient with dedicated accelerators.
As for the scientific applications, they already benefit from AVX v1 for floating point workloads. AVX2 in Haswell is just a stop-gap as the gather is microcoded, but getting code ready for hardware gather in the future uArch is definitely a good way to go.
Finally, when Skylake arrives with AVX 3.1, this will be the next big jump after AVX (v1) for scientific / floating point use cases.
Kevin G - Monday, March 17, 2014 - link
Shouldn't both the Xeon E5-2687W v2 support 384 GB of memory? 4 channels * 3 slots per channel * 32 GB DIMM per slot? (Presumably it could be twice that using eight rank 64 GB DIMMs but I'm not sure if Intel has validated them on the 6 and 10 core dies.) Registered memory has to be used for the E6-2687w v2 to get to 256 GB, just is the chip not capable of running a third slots per channel? Seems like a weird handicap. I can only imagine this being more of a design guideline rule than anything explicit. The 150W CPU's are workstation focused which tend to only have 8 slots maximum.Also a bit weird is the inclusion of the E5-2400 series on the first page's table. While they use the same die, they use a different socket (LGA 1356) with triple memory support and only 24 PCI-e lanes. With the smaller physical area and generally lower TDP's, they're aimed squarely the blade server market. Socket LGA 2011 is far more popular in the workstation and 1U and up servers.
jchernia - Monday, March 17, 2014 - link
A 12 core chip is a server chip - the workstation/PC benchmarks are interesting, but the really interesting benchmarks would be on the server side.Ian Cutress - Monday, March 17, 2014 - link
Johan covered the server side in his article - I link to it many times in the review:http://www.anandtech.com/show/7285/intel-xeon-e5-2...
BMNify - Monday, March 17, 2014 - link
a mass of other's might argue a 12 core/24 thread chip or better is a potential "real-time" UHD x264 encoding machine , its just out of most encoders budgets, so NO SALE....Nintendo Maniac 64 - Monday, March 17, 2014 - link
Uh, where's the test set up for the 7850K?Nintendo Maniac 64 - Monday, March 17, 2014 - link
Also I believe I found a typo:"Haswell provided a significant post to emulator performance"
Shouldn't this say 'boost' rather than 'post'?