AMD Kaveri Review: A8-7600 and A10-7850K Tested
by Ian Cutress & Rahul Garg on January 14, 2014 8:00 AM ESTKaveri and Counting Cores
With the move towards highly integrated SoCs we've seen a variety of approaches to core counts. Apple, Intel and Qualcomm still count CPU cores when advertising an SoC. For Apple and Qualcomm that's partially because neither company is particularly fond of disclosing the configuration of their GPUs. More recently, NVIDIA took the somewhat insane stance of counting GPU CUDA cores on its Tegra K1 SoC. Motorola on the other hand opted for the bizarre choice of aggregating CPU, GPU and off-die companion processors with the X8 platform in its Moto X smartphone. Eventually we will have to find a way to characterize these highly integrated SoCs, particularly when the majority of applications actually depend on/leverage both CPU and GPU cores.
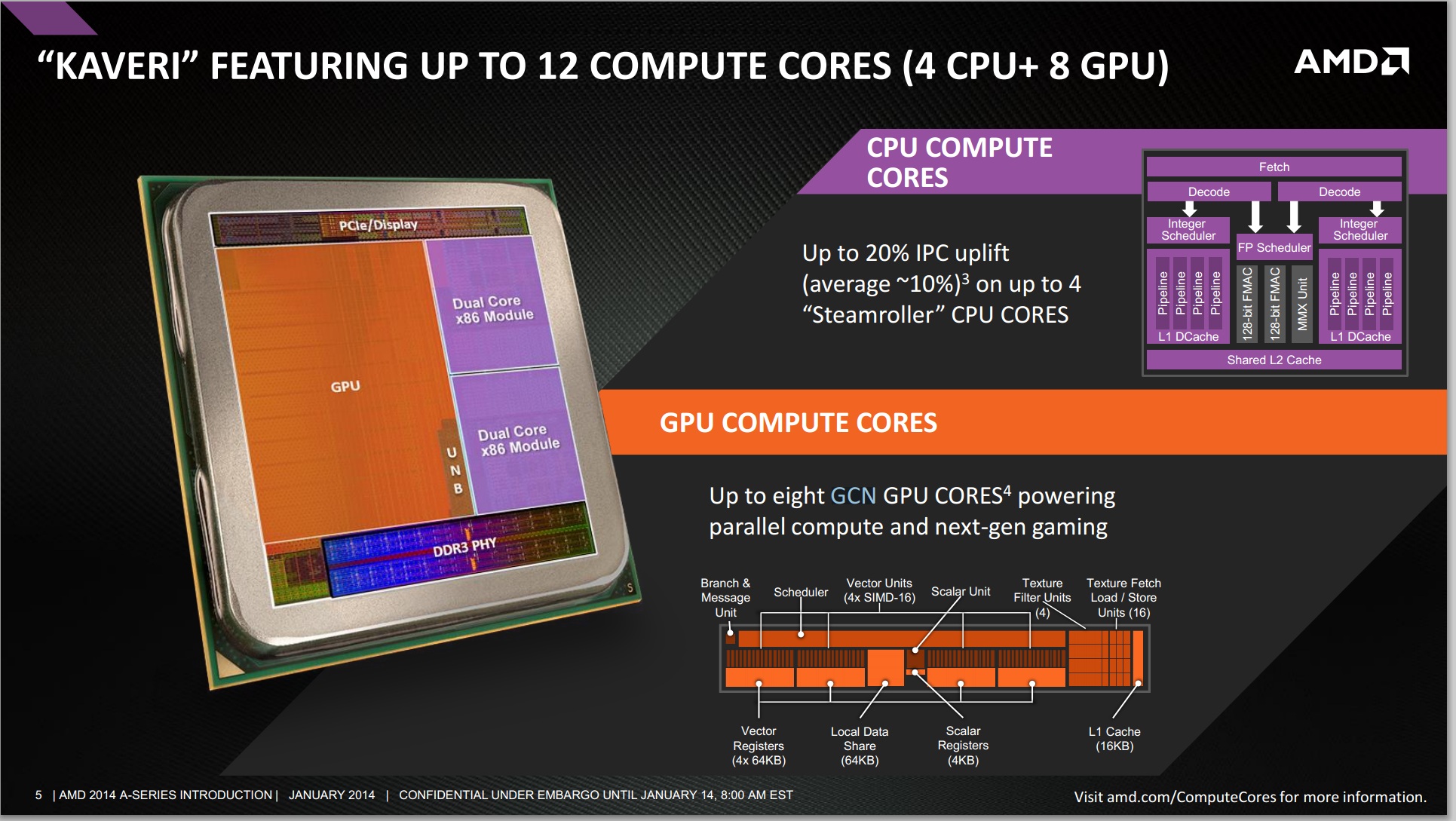
AMD finds itself in a unique position with Kaveri where it has a truly unified CPU/GPU architecture and needs to establish a new nomenclature for use in the future. With 47% of the Kaveri die dedicated for GPU use, and an architecture that treats both CPU and GPU as equals, I can understand AMD's desire to talk about the number of total cores on the APU.
AMD settled on the term "Compute Core", which can refer to either an x86 (or maybe eventually ARM) CPU core or a GCN compute unit. The breakdown is as follows:
- Each thread on a CPU is a Compute Core
- Each Compute Unit on the IGP is a Compute Core
- Total Compute Cores = CPU Compute Cores + IGP Compute Cores
This means that the high end SKU, the A10-7850K will have a total of 12 compute cores: four from the CPU (two Steamroller modules supporting four threads) and eight from the IGP (due to eight compute units from the R7 graphics).

There are some qualifications to be made on this front. Technically, AMD is correct – each compute unit in the IGP and each thread on the CPU can run separate code. The Hawaii GCN architecture can spawn as many kernels as compute units, whereas a couple of generations ago we were restricted to one compute kernel on the GPU at once (merely with blocks of work being split across the CUs). However, clearly these 12 compute units are not equivalent: a programmer will still have to write code for the CPU and GPU specifically in order to use all the processing power available.
Whenever AMD (or partners) are to promote the new APUs, AMD tells us clearly that two sets of numbers should be quoted in reference to the Compute Cores – the total, and the breakdown of CPU/GPU on the APU. Thus this would mean that the A10-7850K APU would be marketed at a “12 Compute Core” device, with “(4 CPU + 8 GPU)” following immediately after. I applaud AMD's decision to not obfuscate the internal configuration of its APUs. This approach seems to be the most sensible if it wants to tout the total processing power of the APU as well as tell those users who understand a bit more what the actual configuration of the SoC is. The biggest issue is how to address the users who automatically assume that more cores == better. The root of this problem is very similar to the old PR-rating debates of the Athlon XP. Explaining to end users the intracacies of CPU/GPU programming is really no different than explaining why IPC * frequency matters more than absolute frequency.
When a programmer obtains an APU, the OpenCL profiler should locate the eight compute units of the GPU and display that to the user for offloading compute purposes; at the same time it is up to the programmer to leverage the threads as appropriately as possible, even with AMD’s 3rd generation Bulldozer modules implementing a dual-INT + single-FP solution.
At launch, AMD will offer the following configurations:
- A10-7850K: 12 Compute Cores (4 CPU + 8 GPU)
- A10-7700K: 10 Compute Cores (4 CPU + 6 GPU)
- A8-7600: 10 Compute Cores (4 CPU + 6 GPU)
The problem with distilling the processing power of the APU into a number of compute cores is primarily on the CPU side. AMD will be keeping the GPU at approximately the same clock (720 MHz for these three) but the CPU frequency will differ greatly, especially with the A8-7600 which has configurable TDP and when in 45W mode will operate 300-400 MHz less.
Steamroller Architecture Redux
We've already documented much of what Steamroller brings to the table based on AMD's Hot Chips presentation last year, but I'll offer a quick recap here.
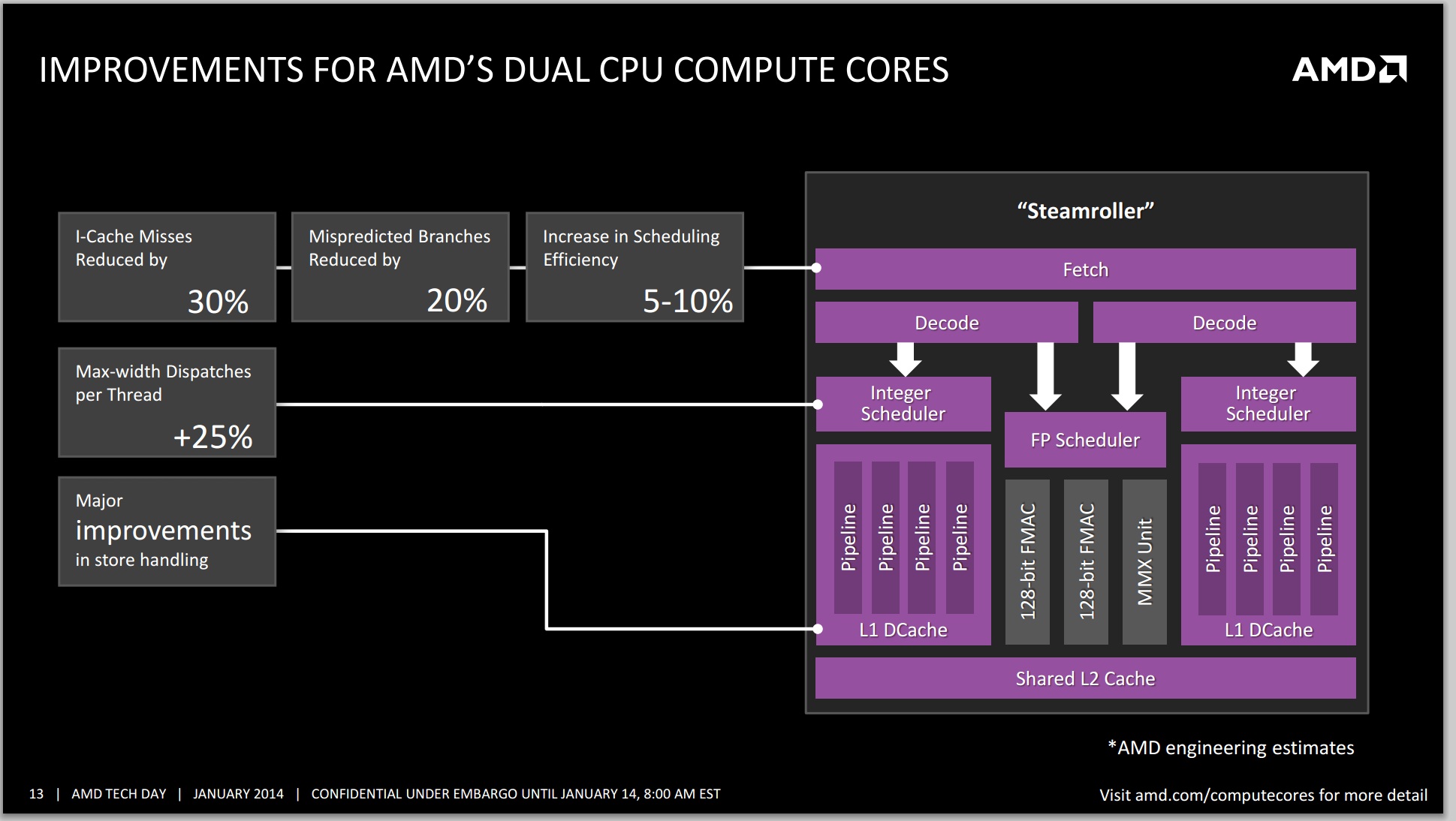
Steamroller brings forward AMD's Bulldozer architecture, largely unchanged. We're still talking about a dual-core module featuring two independent integer execution cores with a single shared floating point execution core capable of executing instructions from two threads in parallel. A single module still appears as two cores/threads to the OS.
In Bulldozer and Piledriver, each integer core had its own independent scheduler but the two cores shared a single fetch and decode unit. Instructions would come in and decodeded operations would be fed to each integer pipe on alternating clock cycles. In Steamroller the decode hardware is duplicated in each module, so now each integer core gets its own decode unit. The two decode units are shared by the one FP unit.
L1 instruction caches increase in size from 64KB to 96KB per module, which AMD claims reduces misses by up to 30%. There's an updated branch predictor which is responsible for reducing mispredicted branches by up to 20%. Both integer and FP register files grow in size as well as an increase in the size of the scheduling window, a combination of which increases the number of dispatches per thread by up to 25%.
There are huge improvements on the store side. Steamroller can now issue up to 2 stores at the same time compared to 1 in Bulldozer/Piledriver. The load/store queue sizes go up by around 20% as well. It's remarkable just how much low hanging fruit there was in the Bulldozer design.
GCN in an APU
The integrated graphics solution on Trinity/Richland launched with a Cayman-derived VLIW4 architecture, which unfortunately came just shortly after desktop side of the equation finished moving from VLIW5/VLIW4 to GCN. Having a product stack with largely different GPU architectures doesn't help anyone, particularly on the developer front. Looking forward, sticking with GCN was the appropriate thing to do, as now Kaveri is using GCN, the same architecture found in AMD’s high end R9-290X GPU, based on the Hawaii platform.
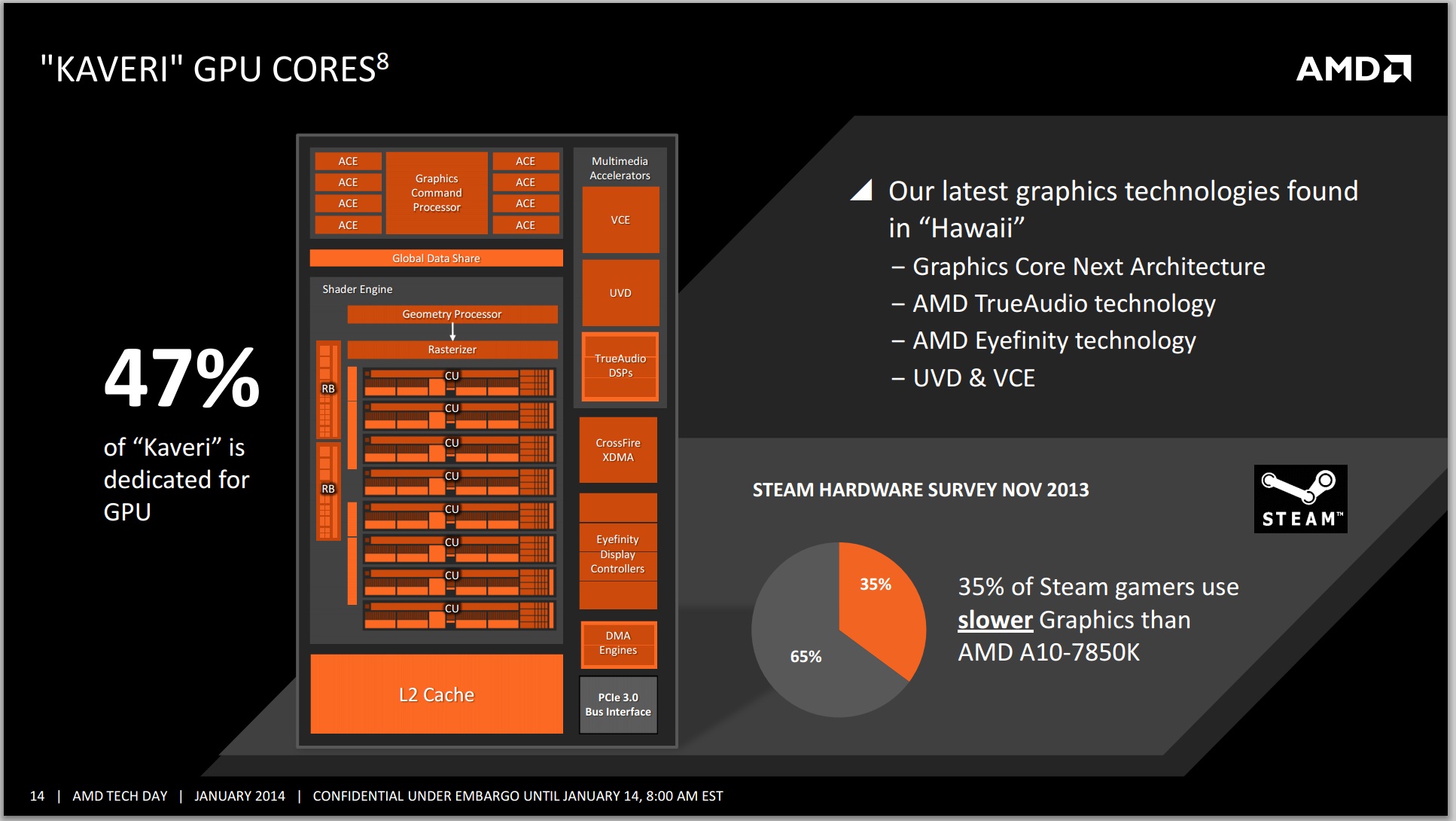
This enabled AMD to add in all the features they currently have on Hawaii with little to no effort – the TrueAudio DSP, the upgraded Video Coding Engine and Unified Video Decoder are such examples. Whether or not AMD decides to develop an APU with more than 8 GCN CUs is another matter. This is a point we've brought up with AMD internally and one that I'm curious about - do any AnandTech readers have an interest in an even higher end APU with substantially more graphics horsepower? Memory bandwidth obviously becomes an issue, but the real question is how valuable an Xbox One/PS4-like APU would be to the community.








380 Comments
View All Comments
Nagorak - Wednesday, January 15, 2014 - link
The fact is these "APUs" are really pretty worthless. If you're going to be seriously gaming then you want to get a discrete graphics card, even a low end one. The problem with AMD's strategy here is that the integrated GPU performance is still so anemic that it's only useful for people who want a budget PC and who don't actually play games. Therefore the "benefits" of having both CPU and GPU on one core are highly questionable.ImSpartacus - Thursday, January 16, 2014 - link
That could be solved if we had a much larger GPU on the APU, right?I want to see at least 12 CUs on the top-end APU, preferably more like 16-20 CUs.
lmcd - Monday, January 20, 2014 - link
Did you miss the whole conversation about memory bandwidth?nader_21007 - Saturday, January 18, 2014 - link
below the charts showing the games performanc, there are two tabs, one for showing avarage frame rate and the other, if you just click on it will show you the suddeframe rates for the apus compared. Minimum frame rate of the iris pro is the lowest and worst among all Apu's compared. It means sudden hangings all over the game. Kaveri and other amd apu's have no such weaknesses because of high performing IGP.Now tell me which is Outperformed?themeinme75 - Saturday, January 18, 2014 - link
the good news is APU-7850/SOC-5200pro just caught up to 4850..cryptik - Monday, March 30, 2015 - link
The R7 consistently beats the Iris Pro. You must have read a different article than everyone else.frozentundra123456 - Tuesday, January 14, 2014 - link
Good review, except he doesn't really address the elephant in the room that even for gaming, a low end cpu like the athlon X4 with a HD7750 will be considerably faster than any APU. So in this regard, I disagree with the conclusions that for low end gaming kaveri is the best solution. It is disappointing actually, that he did not use a HD7750 GDDR5 as the discrete gpu comparison, because that would have given a more direct comparison of how the bandwidth restrictions are affecting Kaveri.I will say though that the low TDP parts seem to get a nice improvement in performance. They actually seem more attractive that the high end, since there is little gaming improvement in the top end vs Richland.
thevoiceofreason - Tuesday, January 14, 2014 - link
Or something like Pentium G2120 (90$ newegg) and HD7770 (90$ ASUS or MSI on newegg after rebate). The difference between such a setup and a top of the line kaveri chip is not even funny. Kind of tragic, really.andrewaggb - Tuesday, January 14, 2014 - link
I agree. I am extremely dissappointed. Cpu performance and GPU performance barely changed from last year's model. HSA is definitely the future, and Mantle may deliver a healthy fps improvement, but I feel like this product has almost no value at launch. It's all depending on future software.I was actually considering a kaveri for a kids pc... but I'm definitely way better off getting an intel cpu and amd gpu.
andrewaggb - Tuesday, January 14, 2014 - link
I guess they did make big gains on TDP. So it's sorta their version of a haswell refresh. But haswell had a larger improvement in both cpu and gpu performance relative to their previous chip.