AMD’s Kaveri: Pre-Launch Information
by Ian Cutress on January 6, 2014 8:00 PM EST
On the back of AMD’s Tech Day at CES 2014, all of which was under NDA until the launch of Kaveri, AMD have supplied us with some information that we can talk about today. For those not following the AMD roadmap, Kaveri is the natural progression of the AMD A-Series APU line, from Llano, Trinity to Richland and now Kaveri. At the heart of the AMD APU design is the combination of CPU cores (‘Bulldozer’, ‘Steamroller’) and a large dollop of GPU cores for on-chip graphics prowess.
Kaveri is that next iteration in line which uses an updated FM2+ socket from Richland and the architecture is updated for Q1 2014. AMD are attacking with Kaveri on four fronts:

Redesigned Compute Cores* (Compute = CPU + GPU)
Kaveri uses an enhanced version of the Richland CPU core, codename Steamroller. As with every new CPU generation or architecture update, the main goal is better performance and lower power – preferably both. AMD is quoting a 20% better x86 IPC with Kaveri compared to Richland when put clock to clock. For the purposes of this information release, we were provided with several AMD benchmarking results to share:
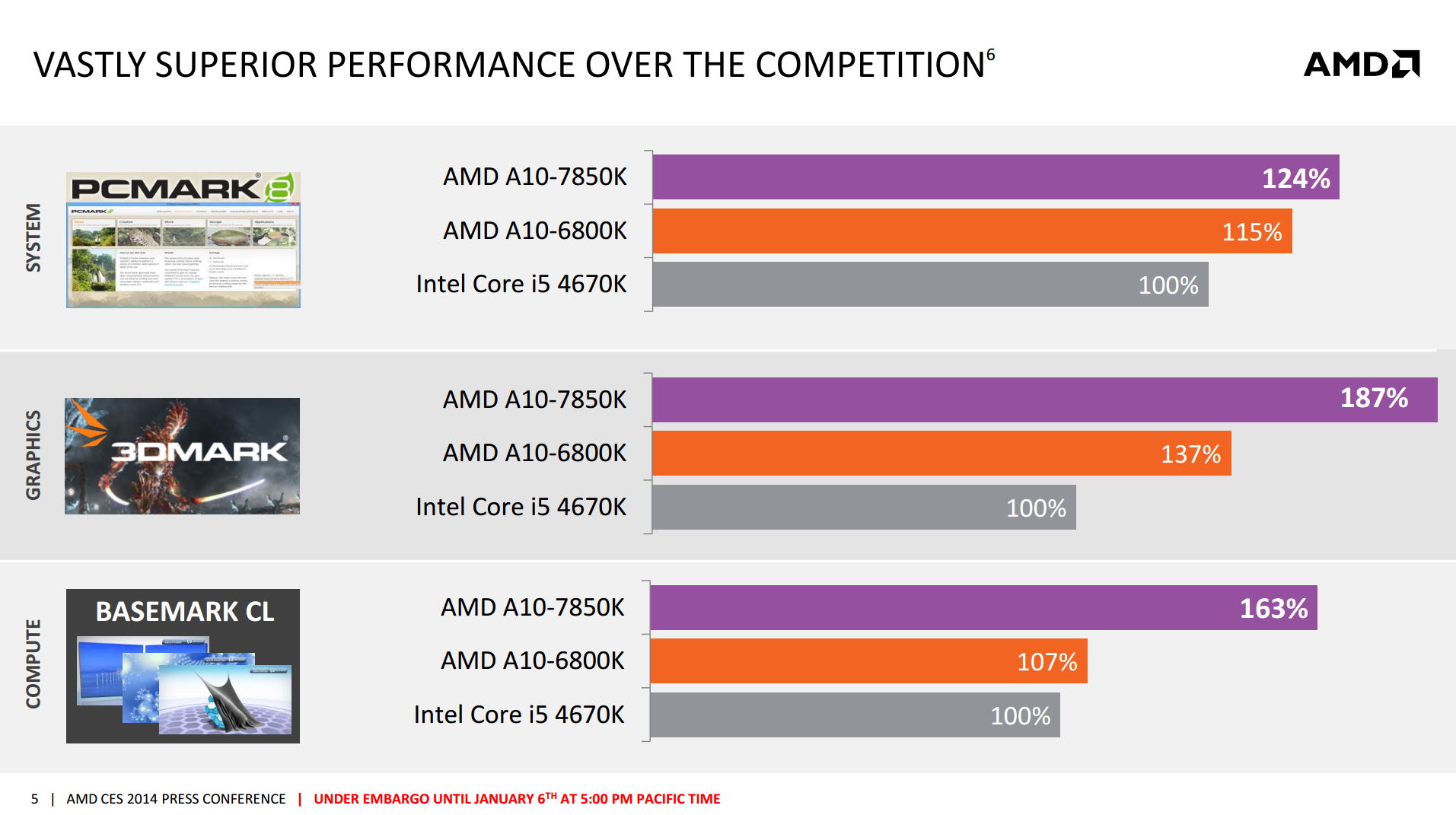
These results border pretty much on the synthetic – AMD did not give any real world examples today but numbers will come through in time. AMD is set to release two CPUs on January 14th (date provided in our pre-release slide deck), namely the A10-7700K and the A10-7850K. Some of the specifications were also provided:
| AMD APUs | ||||
|
Richland A8-6600K |
Richland A10-6800K |
Kaveri A10-7700K |
Kaveri A10-7850K |
|
| Release | June 4 '13 | June 4 '13 | Jan 14th '14 | Jan 14th '14 |
| Frequency | 3900 MHz | 4100 MHz | ? | 3700 MHz |
| Turbo | 4200 MHz | 4400 MHz | ? | ? |
| DRAM | DDR3-1866 | DDR3-2133 | DDR3-2133 | DDR3-2133 |
| Microarhitecture | Piledriver | Piledriver | Steamroller | Steamroller |
| Manufacturing Process | 32nm | 32nm | ? | ? |
| Modules | 2 | 2 | ? | 2 |
| Threads | 4 | 4 | ? | 4 |
| Socket | FM2 | FM2 | FM2+ | FM2+ |
| L1 Cache |
2 x 64 KB I$ 4 x 16 KB D$ |
2 x 64 KB I$ 4 x 16 KB D$ |
? | ? |
| L2 Cache | 2 x 2 MB | 2 x 2 MB | ? | ? |
| Integrated GPU | HD 8570D | HD 8670D | R7 | R7 |
| IGP Cores | 256 | 384 | ? | 512 |
| IGP Architecture | Cayman | Cayman | GCN | GCN |
| IGP Frequency | 844 | 844 | ? | 720 |
| Power | 100W | 100W | ? | 95W |
All the values marked ‘?’ have not been confirmed at this point, although it is interesting to see that the CPU MHz has decreased from Richland. A lot of the APU die goes to that integrated GPU, which as we can see above becomes fully GCN, rather than the Cayman derived Richland APUs. This comes with a core bump as well, seeing 512 GPU cores on the high end module – this equates to 8 CUs on die and what AMD calls ’12 Compute Cores’ overall. These GCN cores are primed and AMD Mantle ready, suggesting that performance gains could be had directly from Mantle enabled titles.
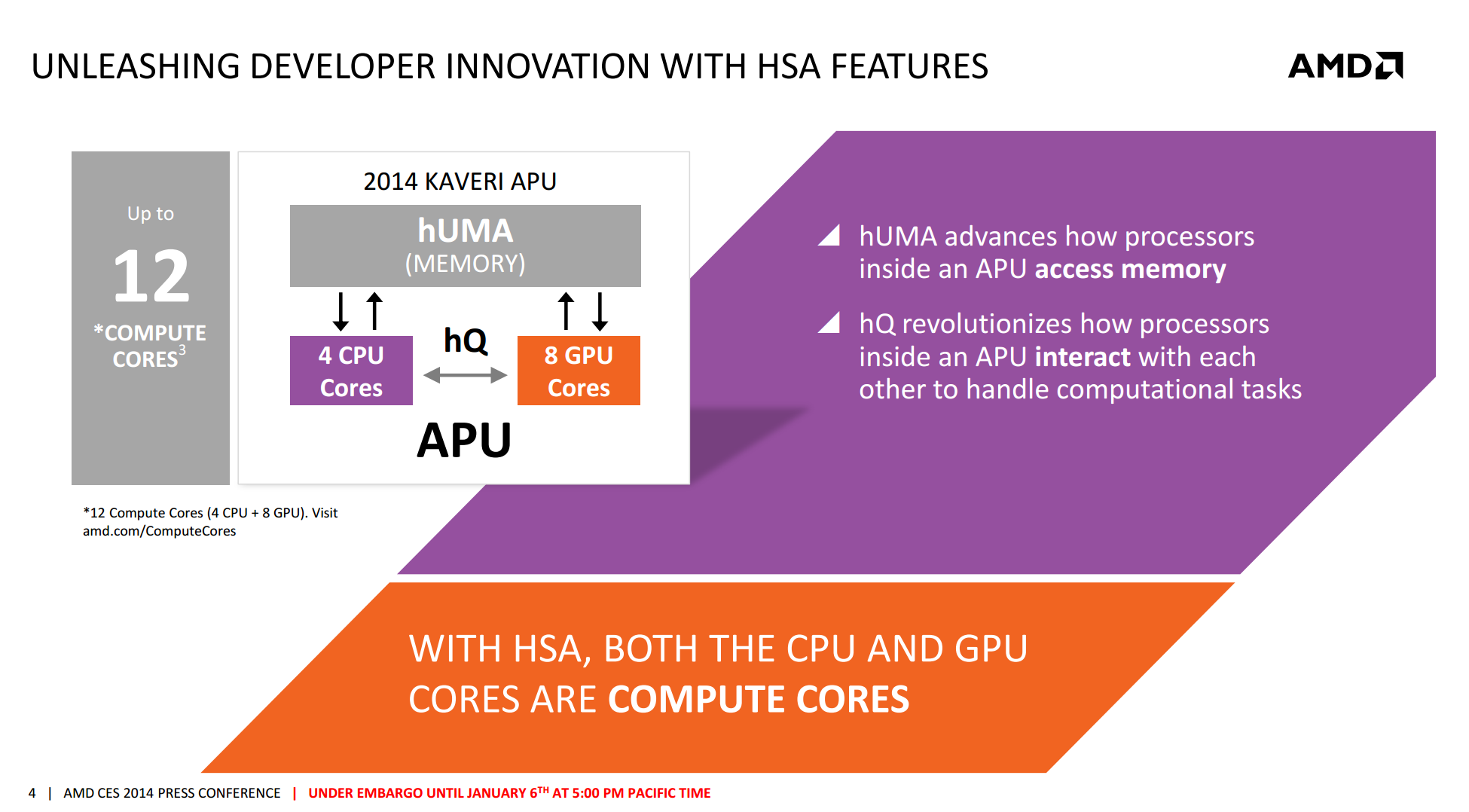
Described in AMD’s own words: ‘A compute core is an HSA-enabled hardware block that is programmable (CPU, GPU or other processing element), capable of running at least one process in its own context and virtual memory space, independently from other cores. A GPU Core is a GCN-based hardware block containing a dedicated scheduler that feeds four 16-wide SIMD vector processors, a scalar processor, local data registers and data share memory, a branch & message processor, 16 texture fetch or load/store units, four texture filter units, and a texture cache. A GPU Core can independently execute work-groups consisting of 64 work items in parallel.’ This suggests that if we were to run asynchronous kernels on the AMD APU, we could technically run twelve on the high end APU, given that each Compute Core is capable of running at least one process in its own context and virtual memory space independent of the others.
The reason why AMD calls them Compute Cores is based on their second of their four pronged attack: hUMA.
HSA, hUMA, and all that jazz
AMD went for the heterogeneous system architecture early on to exploit the fact that many compute intensive tasks can be offloaded to parts of the CPU that are designed to run them faster or at low power. By combining CPU and GPU on a single die, the system should be able to shift work around to complete the process quicker. When this was first envisaged, AMD had two issues: lack of software out in the public domain to take advantage (as is any new computing paradigm) and restrictive OS support. Now that Windows 8 is built to allow HSA to take advantage of this, all that leaves is the programming. However AMD have gone one step further with hUMA, and giving the system access to all the memory, all of the time, from any location:
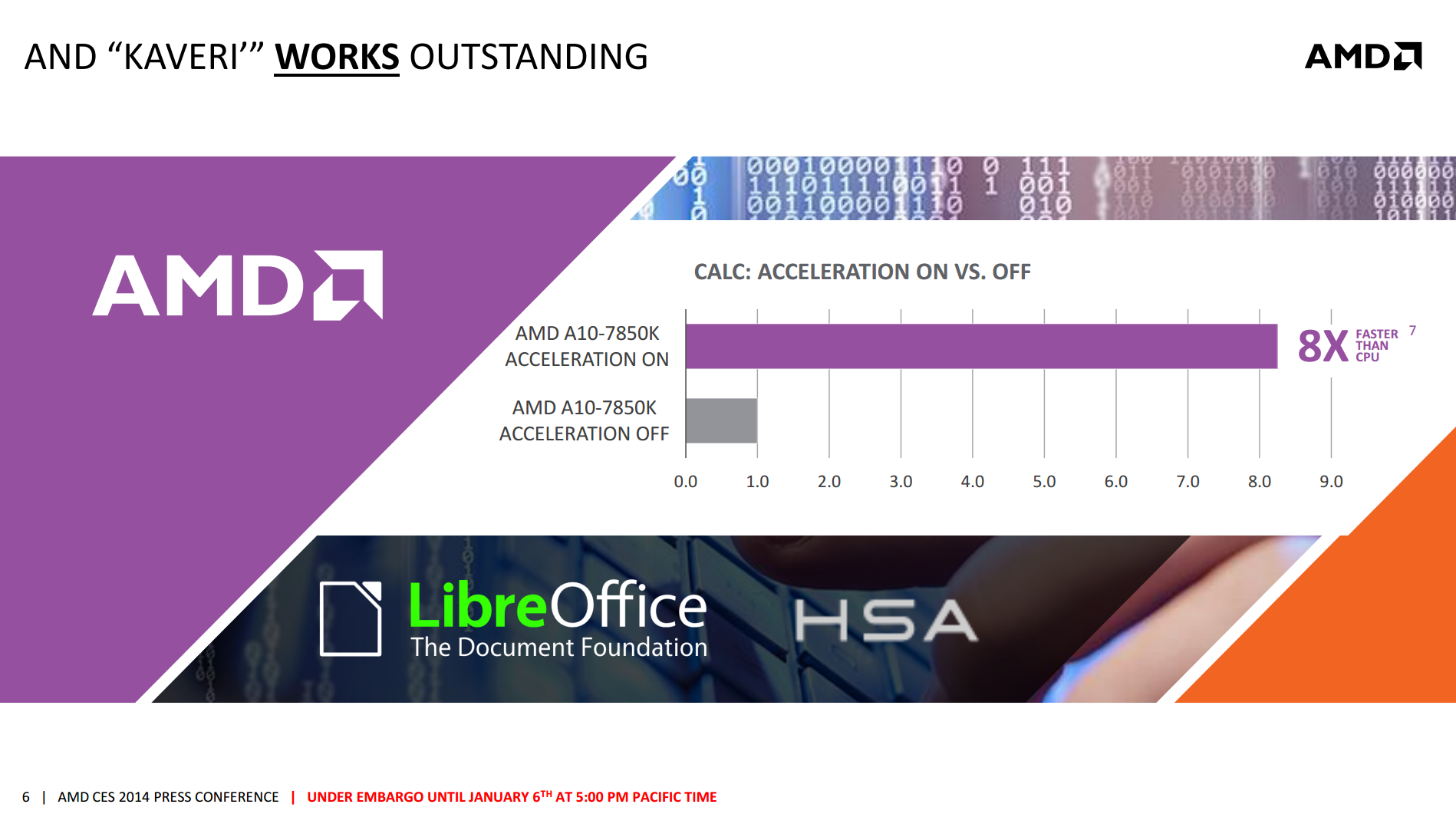
Now that Kaveri offers a proper HSA stack, and can call upon 12 compute cores to do work, applications that are designed (or have code paths) to take advantage of this should emerge. One such example that AMD are willing to share today is stock calculation using LibreOffice's Calc application – calculating the BETA (return) of 21 fake stocks and plotting 100 points on a graph of each stock. With HSA acceleration on, the system performed the task in 0.12 seconds, compared to 0.99 seconds when turned off.
Prong 3: Gaming Technologies
In a year where new gaming technologies are at the forefront of design, along with gaming power, AMD are tackling the issue on one front with Kaveri. By giving it a GCN graphics backbone, features from the main GPU line can fully integrate (with HSA) into the APU. As we have seen in previous AMD releases and talks, this means several things:
- Mantle
- AMD TrueAudio
- PCIe Gen 3
AMD is wanting to revolutionize the way that games are played and shown with Mantle – it is a small shame that the Mantle release was delayed and that AMD did not provide any numbers to share with us today. The results should find their way online after release however.
Prong 4: Power Optimisations
With Richland we had CPUs in the range of 65W to 100W, and using the architecture in the FX range produced CPUs up to 220W. Techincally we had 45W Richland APUs launch, but to date I have not seen one for sale. However this time around, AMD are focusing a slightly lower power segment – 45W to 95W. Chances are the top end APUs (A10-7850K) will be 95W, suggesting that we have a combination of a 20% IPC improvement, 400 MHz decrease but a 5% TDP decrease for the high end chip. Bundle in some HSA and let’s get this thing on the road.
Release Date
AMD have given us the release date for the APUs: January 14th will see the launch of the A10-7850K and the A10-7700K. Certain system builders should be offering pre-built systems based on these APUs from today as well.










133 Comments
View All Comments
editorsorgtfo - Monday, January 6, 2014 - link
Do not forget that intel's 22 nm node is a marketing name and actually lies around 26 nm node by generally accepted worldwide fabs standards. GloFo is going to present true 20 nm node in the middle of this year. Next-gen Carrizo should be expected to be true 20 nm, but it depends on foundry readiness however. I'm little confused, why Carrizo is not going to have implemented DDR4 memory controller yet.dylan522p - Tuesday, January 7, 2014 - link
Actually no. The process node number hasn't been the actual process node for a while. 16nm FinFet is actually just 20nm with FinFet as Gflo and TSMC and Samsung are trying to pretend they are tied with Intel. Currentl, Intel is 1.5 gens ahead but Broadwell will make it 2.5 by 20nm without FinFet is coming soon as well so it will be back to being 1.5 gen behind.editorsorgtfo - Tuesday, January 7, 2014 - link
Do you have a source for that information?My source is http://www.electronicsweekly.com/mannerisms/manufa...
arnavvdesai - Monday, January 6, 2014 - link
I actually code on JVM based languages (think Java, Scala, Javascript) . There is a project which AMD is working on with Oracle which will offload certain instruction set to the GPU without the need for the coder to do anything special. If that project pans out and gives the gains it is supposed to deliver, it would be pretty awesome and would change my life for the better at least.duploxxx - Tuesday, January 7, 2014 - link
http://www.javaworld.com/article/2078856/mobile-ja...chizow - Monday, January 6, 2014 - link
20% IPC improvement from Steamroller is short of some lofty expectations from AMD fans, but still impressive. I also like how AMD committed to a hard release date that isn't months in the future, hopefully it performs well and we see what it is capable of in about a week.jospoortvliet - Thursday, January 9, 2014 - link
Too bad the frequencies are down about 15%... Making for a mere ~5% performance increase, while 20% would already have been marginal :(GummiRaccoon - Monday, January 6, 2014 - link
The grammar of this article drives me crazy, can you stop using the British style of referring to companies as groups of people? AMD is a singular entity. It is A corporation, not some random group of people. Beyond that you don't even keep it consistent. Just remember, "The United States is" not "The United States are." I cringe every time I see "AMD have" or "AMD are" and you don't even do it for "AMD does" or "AMD calls." Also I notice you store passwords as clear text, this is a disaster waiting to happen.editorsorgtfo - Monday, January 6, 2014 - link
How did you get evidence that passwords are stored as text?GummiRaccoon - Monday, January 6, 2014 - link
Reset your password. They e-mail you your current password. If they are able to send you your password, that means it is stored as plain text. That means they have a database that has everyone's password stored with their e-mail address and username. This is how everyone gets their data/accounts compromised.