ASUS Maximus VI Impact Review: ROG and Mini-ITX
by Ian Cutress on November 22, 2013 10:00 AM ESTComputational Benchmarks
Readers of our motherboard review section will have noted the trend in modern motherboards to implement a form of MultiCore Enhancement / Acceleration / Turbo (read our report here) on their motherboards. This does several things – better benchmark results at stock settings (not entirely needed if overclocking is an end-user goal), at the expense of heat and temperature, but also gives in essence an automatic overclock which may be against what the user wants. Our testing methodology is ‘out-of-the-box’, with the latest public BIOS installed and XMP enabled, and thus subject to the whims of this feature. It is ultimately up to the motherboard manufacturer to take this risk – and manufacturers taking risks in the setup is something they do on every product (think C-state settings, USB priority, DPC Latency / monitoring priority, memory subtimings at JEDEC). Processor speed change is part of that risk which is clearly visible, and ultimately if no overclocking is planned, some motherboards will affect how fast that shiny new processor goes and can be an important factor in the purchase.
For reference, the Maximus VI Impact in this review did enable MCT during the benchmarks.
Point Calculations - 3D Movement Algorithm Test
The algorithms in 3DPM employ both uniform random number generation or normal distribution random number generation, and vary in various amounts of trigonometric operations, conditional statements, generation and rejection, fused operations, etc. The benchmark runs through six algorithms for a specified number of particles and steps, and calculates the speed of each algorithm, then sums them all for a final score. This is an example of a real world situation that a computational scientist may find themselves in, rather than a pure synthetic benchmark. The benchmark is also parallel between particles simulated, and we test the single thread performance as well as the multi-threaded performance.
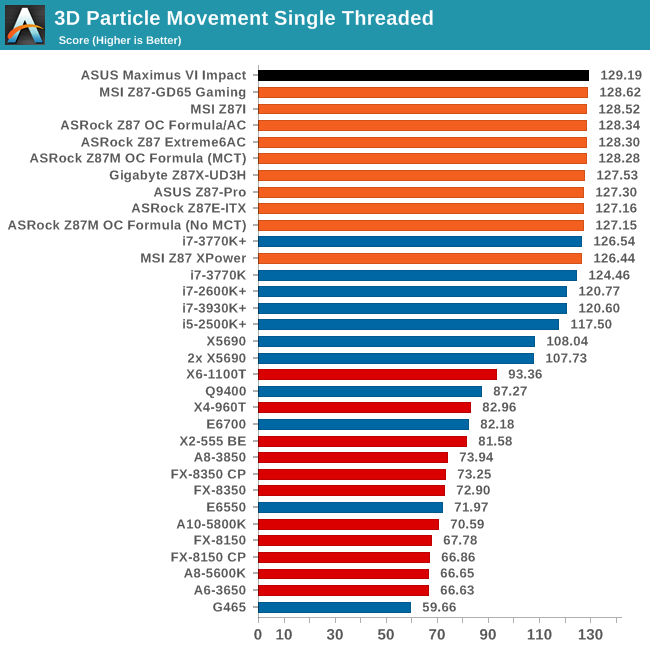
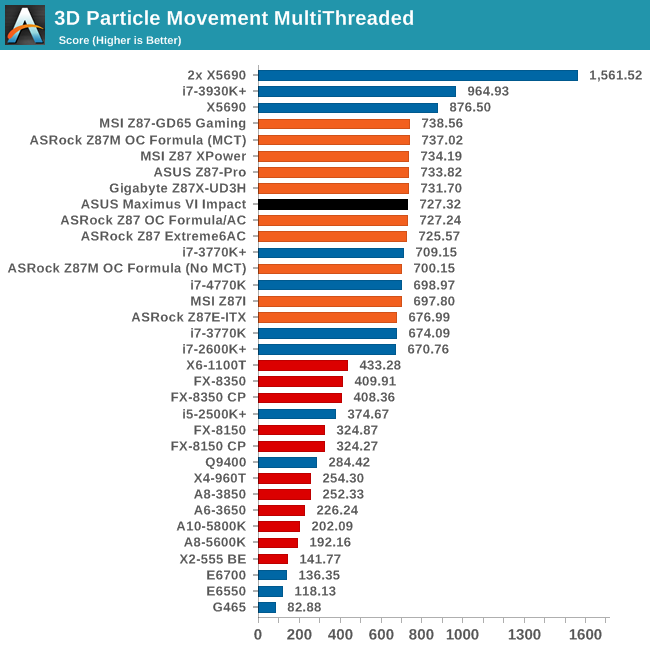
For single threaded optimization of FP calculations, the M6I seems to be right on the money. Multithreaded seems to be middle of the field in 3DPM.
Compression - WinRAR 4.2
With 64-bit WinRAR, we compress the set of files used in the USB speed tests. WinRAR x64 3.93 attempts to use multithreading when possible, and provides as a good test for when a system has variable threaded load. WinRAR 4.2 does this a lot better! If a system has multiple speeds to invoke at different loading, the switching between those speeds will determine how well the system will do.
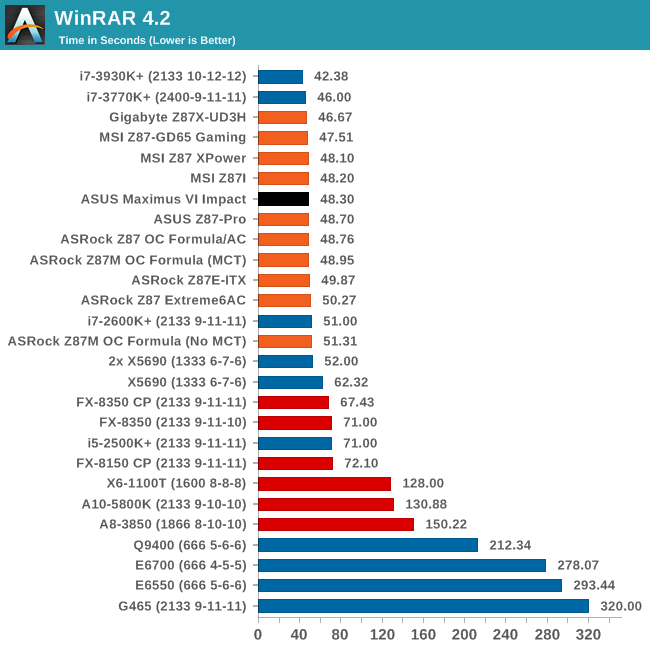
WinRAR also comes across midfield, with similar times to the Z87 Pro.
Image Manipulation - FastStone Image Viewer 4.2
FastStone Image Viewer is a free piece of software I have been using for quite a few years now. It allows quick viewing of flat images, as well as resizing, changing color depth, adding simple text or simple filters. It also has a bulk image conversion tool, which we use here. The software currently operates only in single-thread mode, which should change in later versions of the software. For this test, we convert a series of 170 files, of various resolutions, dimensions and types (of a total size of 163MB), all to the .gif format of 640x480 dimensions.
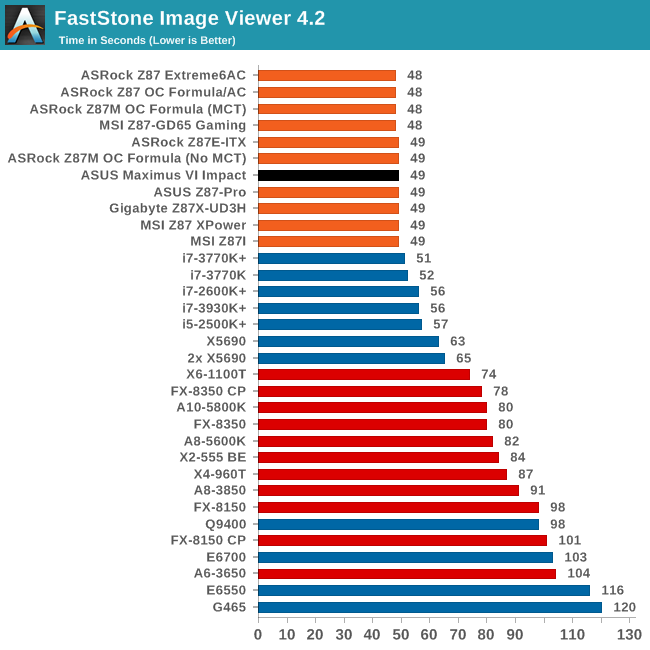
Every Z87 motherboard seems to score either 48 or 49 seconds in FastStone, and the M6I is no different.
Video Conversion - Xilisoft Video Converter 7
With XVC, users can convert any type of normal video to any compatible format for smartphones, tablets and other devices. By default, it uses all available threads on the system, and in the presence of appropriate graphics cards, can utilize CUDA for NVIDIA GPUs as well as AMD WinAPP for AMD GPUs. For this test, we use a set of 33 HD videos, each lasting 30 seconds, and convert them from 1080p to an iPod H.264 video format using just the CPU. The time taken to convert these videos gives us our result.
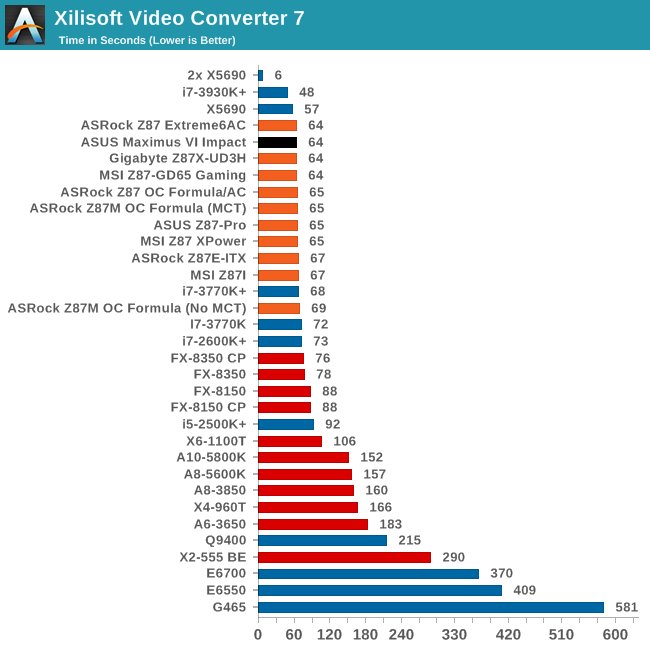
ASUS is in the leading pack around 64 seconds for XVC.
Video Conversion - x264 HD Benchmark
The x264 HD Benchmark uses a common HD encoding tool to process an HD MPEG2 source at 1280x720 at 3963 Kbps. This test represents a standardized result which can be compared across other reviews, and is dependent on both CPU power and memory speed. The benchmark performs a 2-pass encode, and the results shown are the average of each pass performed four times.
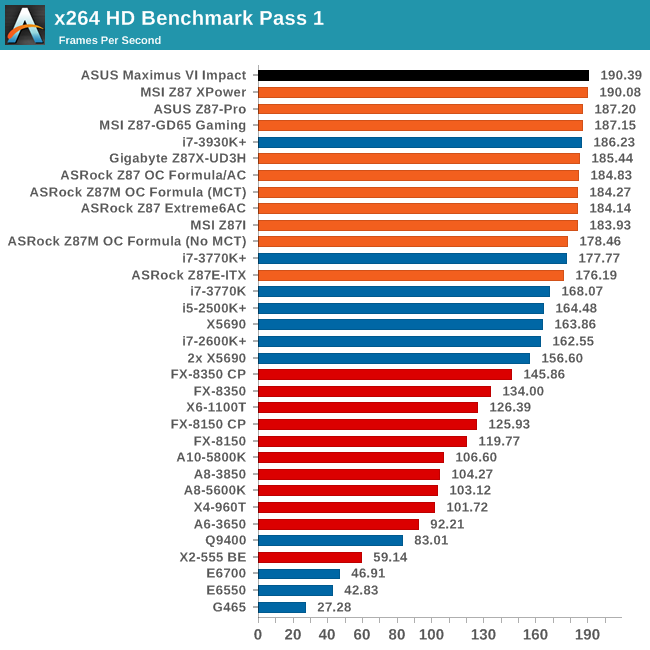
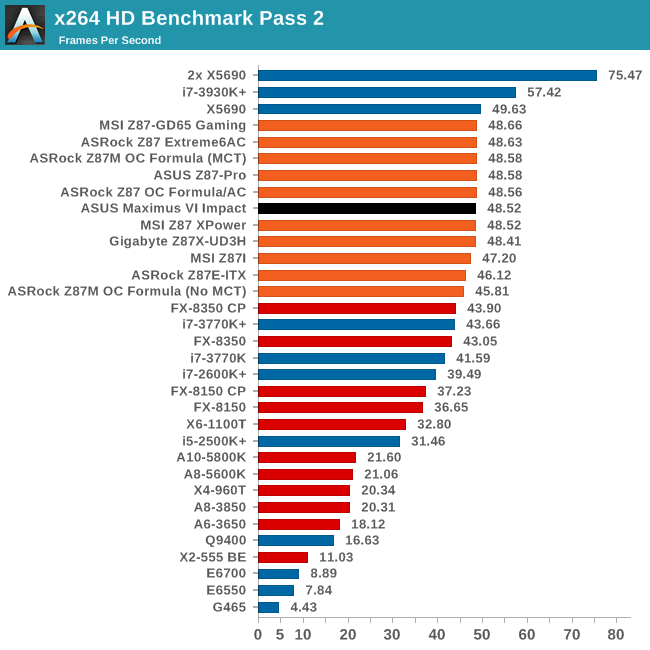
There still seems to be some room at the top in the first pass, with the M6I taking the crown. The second pass seems to have hit an asymptotic limit around 48.6 FPS for the 4770K.
Grid Solvers - Explicit Finite Difference
For any grid of regular nodes, the simplest way to calculate the next time step is to use the values of those around it. This makes for easy mathematics and parallel simulation, as each node calculated is only dependent on the previous time step, not the nodes around it on the current calculated time step. By choosing a regular grid, we reduce the levels of memory access required for irregular grids. We test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
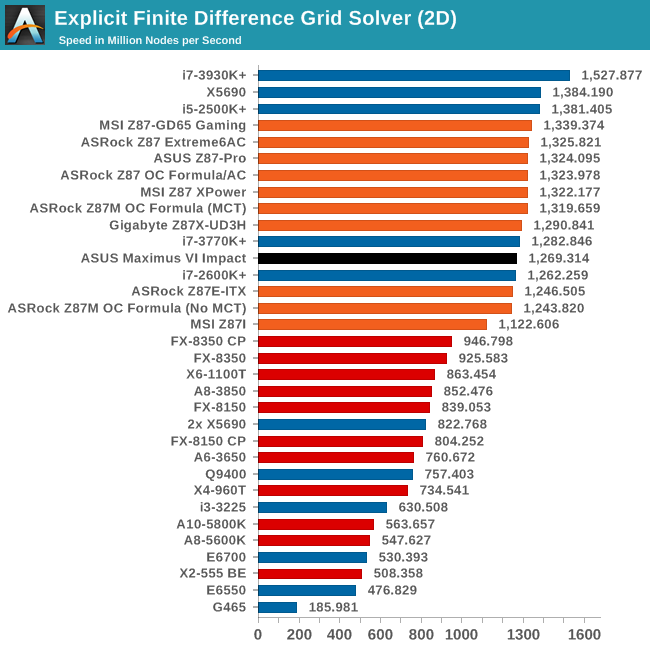
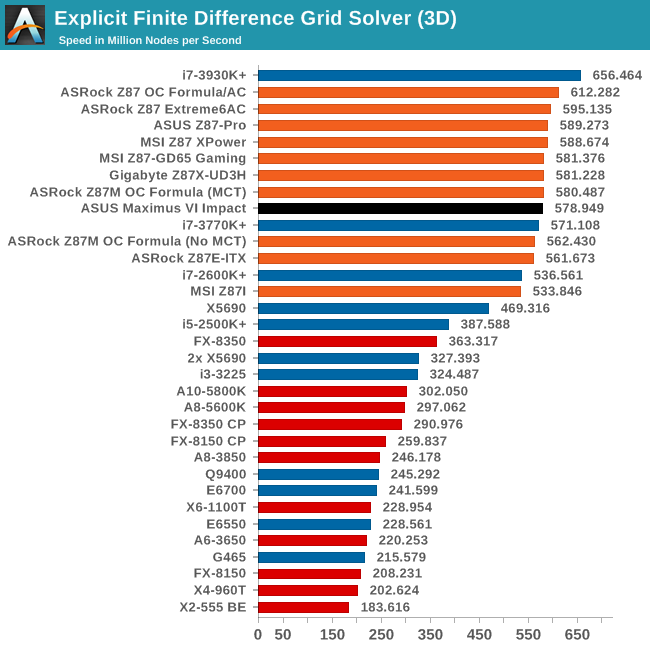
The M6I seems to hit a rough patch with our Ex-FD simulations, 2D being particularly affected.
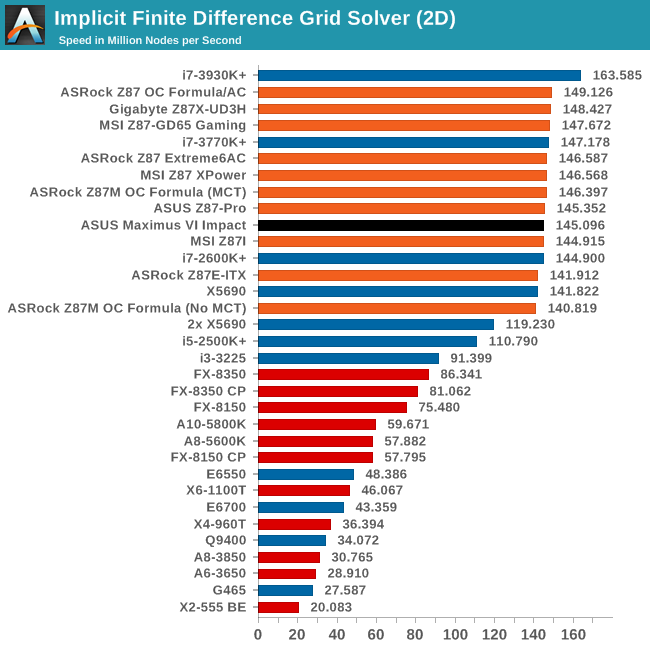
Grid Solvers - Implicit Finite Difference + Alternating Direction Implicit Method
The implicit method takes a different approach to the explicit method – instead of considering one unknown in the new time step to be calculated from known elements in the previous time step, we consider that an old point can influence several new points by way of simultaneous equations. This adds to the complexity of the simulation – the grid of nodes is solved as a series of rows and columns rather than points, reducing the parallel nature of the simulation by a dimension and drastically increasing the memory requirements of each thread. The upside, as noted above, is the less stringent stability rules related to time steps and grid spacing. For this we simulate a 2D grid of 2n nodes in each dimension, using OpenMP in single precision. Again our grid is isotropic with the boundaries acting as sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
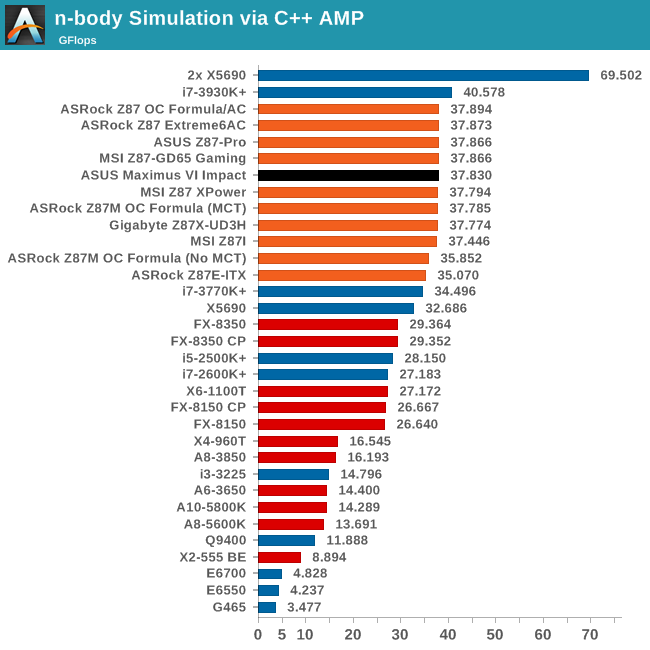
Point Calculations - n-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions. The benchmark detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. We run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.








69 Comments
View All Comments
jihe - Thursday, November 28, 2013 - link
You can pick up an old cpu for a dime. Think about the among if of engineering and fabrication in that.HighOnMikey - Friday, November 22, 2013 - link
I have this and a BitFenix Prodigy. Beautiful combo, if you ask me. Anyway I use this as my main/gaming desktop with Windows 8.1. While an improvement, boot times are still between 12-17 seconds. Windows 8.1 also introduces several issues with stability, something I didn't experience quite as much with Windows 8. I also experienced the same issues with SonicRadar, but the FPS drop was more severe using a very similar setup with the exception of a GeForce GTX 680. Great board.stennan - Friday, November 22, 2013 - link
How many Pcie lanes are linked to the m2 connection? will we be able to get speeds above sata3?Morawka - Saturday, November 23, 2013 - link
nope.avi. ASUS is retarded and put the m.2 on a PCI 1X Busu.of.ipod - Friday, November 22, 2013 - link
Really disappointed to see no use of the M.2 slot in this review. One of the biggest reasons I want to use this board.Morawka - Saturday, November 23, 2013 - link
Asus botched it this time around. They put the M.2 Connector on a PCI 1X Bus, which severely limits what these SSD's are capable of.JoanSpark - Friday, November 22, 2013 - link
I thought there was a mITX review coming in?lorribot - Friday, November 22, 2013 - link
Oh look woopie woo aren'y we clever we can stick a whole bunch of stuff on a tiny board and chrge you the same as a big board.Er actually no your not.
What I want is a quality ITX board with aout all the rubbish. If I buy a Z board I am going to be overclocking, do I need any video out put on the back panel? No. DO i want SPDIF? No. DO I need 4 SATA? No, just the two. DO i need Wifi, no just a standard 1 Gb Nic.
When will a Mobo comapany actually stop trying to be clever and produce a resonably priced Z board with basics and nothing more for about a 1/3 of the price of this beastie?
Make that I may just think you are a bit clever ASUS et al.
extide - Friday, November 22, 2013 - link
Check out the ASRock Z87 ITXlorribot - Saturday, November 23, 2013 - link
Would that be the 127GBP/$160 Z87E-ITX? The one with Wi-fi built in?Not exact 1/3 of the price that one.
I would rather spend an extra £50-60 on upgrading processor or graphics card than MOBO features I never use.