The iPhone 5s Review
by Anand Lal Shimpi on September 17, 2013 9:01 PM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone
- iPhone 5S
The Move to 64-bit
Prior to the iPhone 5s launch, I heard a rumor that Apple would move to a 64-bit architecture with its A7 SoC. I initially discounted the rumor given the pain of moving to 64-bit from a validation standpoint and the upside not being worth it. Obviously, I was wrong.
In the PC world, most users are familiar with the 64-bit transition as something AMD started in the mid-2000s. The primary motivation back then was to enable greater memory addressability by moving from 32-bit addresses (2^32 or 4GB) to 64-bit addresses (2^64 or 16EB). Supporting up to 16 exabytes of memory from the get go seemed a little unnecessary, so AMD’s x86-64 ISA only uses 48-bits for unique memory addresses (256TB of memory). Along with the move from x86 to x86-64 came some small performance enhancements thanks to more available general purpose registers in 64-bit mode.
In the ARM world, the move to 64-bit is motivated primarily by the same factor: a desire for more memory. Remember that ARM and its partners have high hopes of eating into Intel’s high margin server business, and you really can’t play there without 64-bit support. ARM has already announced its first two 64-bit architectures: the Cortex A57 and Cortex A53. The ISA itself is referred to as ARMv8, a logical successor to the present day 32-bit ARMv7.
Unlike the 64-bit x86 transition, ARM’s move to 64-bit comes with a new ISA rather than an extension of the old one. The new instruction set is referred to as A64, while a largely backwards compatible 32-bit format is called A32. Both ISAs can be supported by a single microprocessor design, as ARMv8 features two architectural states: AArch32 and AArch64. Designs that implement both states can switch/interleave between the two states on exception boundaries. In other words, despite A64 being a new ISA you’ll still be able to run old code alongside it. As always, in order to support both you need an OS with support for A64. You can’t run A64 code on an A32 OS. It is also possible to do an A64/AArch64-only design, which is something some server players are considering where backwards compatibility isn’t such a big deal.
Cyclone is a full implementation of ARMv8 with both AArch32 and AArch64 states. Given Apple’s desire to maintain backwards compatibility with existing iOS apps and not unnecessarily fragment the ARM ecosystem, simply embracing ARMv8 makes a lot of sense.
The motivation for Apple to go 64-bit isn’t necessarily one of needing more address space immediately. A look at Apple’s historical scaling of memory capacity tells us everything we need to know:
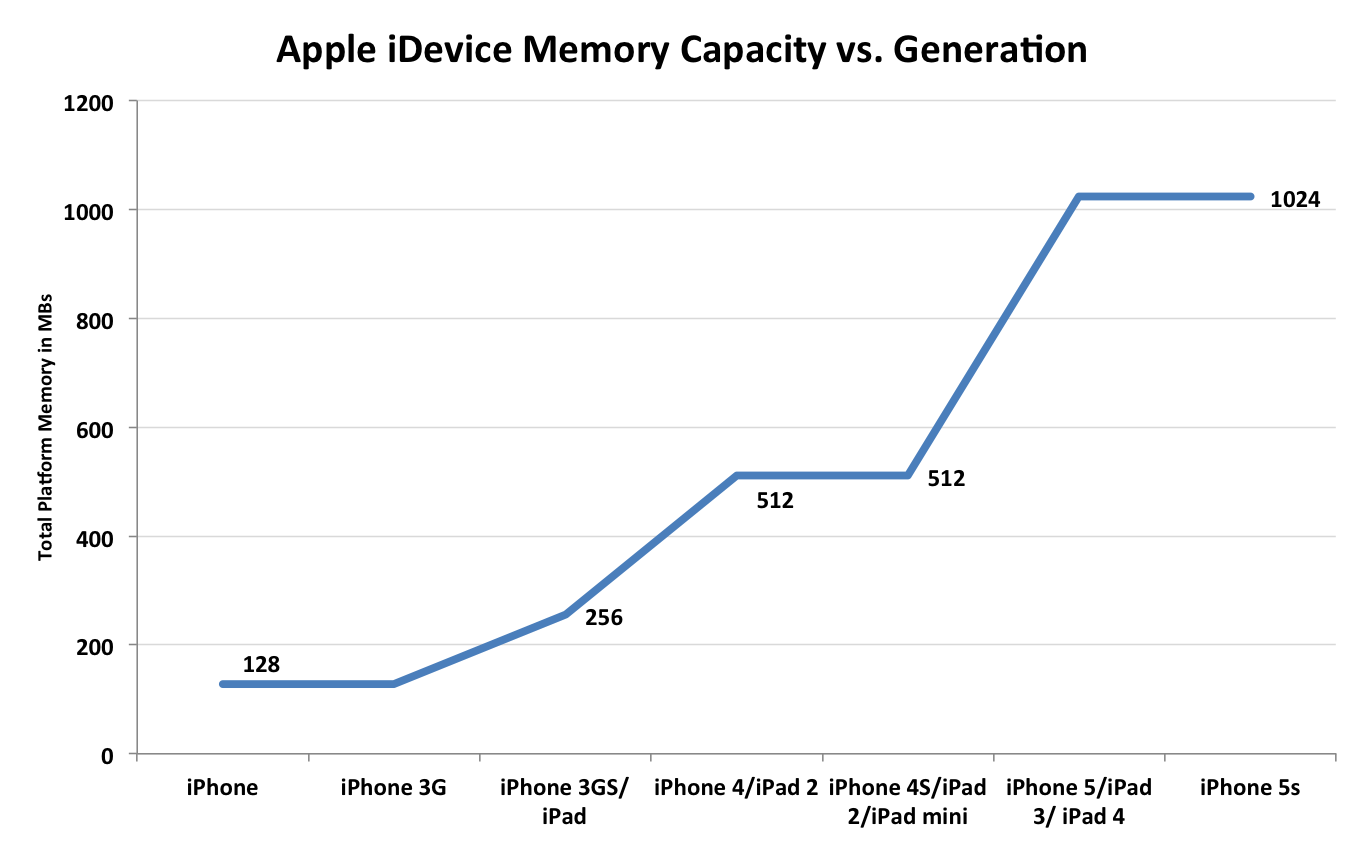
At best Apple doubled memory capacity between generations, and at worst it took two generations before doubling. The iPhone 5s ships with 1GB of LPDDR3, keeping memory capacity the same as the iPhone 5, iPad 3 and iPad 4. It’s pretty safe to assume that Apple will go to 2GB with the iPhone 6 (and perhaps iPad 5), and then either stay there for the 6s or double again to 4GB. The soonest Apple would need 64-bit from a memory addressability standpoint in an iOS device would be 2015, and the latest would be 2016. Moving to 64-bit now preempts Apple’s hardware needs by 2 full years.
The more I think about it, the more the timing actually makes a lot of sense. The latest Xcode beta and LLVM compiler are both ARMv8 aware. Presumably all apps built starting with the official iOS 7 release and going forward could be built 64-bit aware. By the time 2015/2016 rolls around and Apple starts bumping into 32-bit addressability concerns, not only will it have navigated the OS transition but a huge number of apps will already be built for 64-bit. Apple tends to do well with these sorts of transitions, so starting early like this isn’t unusual. The rest of the ARM ecosystem is expected to begin moving to ARMv8 next year.
Apple isn’t very focused on delivering a larger memory address space today however. As A64 is a brand new ISA, there are other benefits that come along with the move. Similar to the x86-64 transition, the move to A64 comes with an increase in the number of general purpose registers. ARMv7 had 15 general purpose registers (and 1 register for the program counter), while ARMv8/A64 now has 31 that are each 64-bits wide. All 31 registers are accessible at all times. Increasing the number of architectural registers decreases register pressure and can directly impact performance. The doubling of the register space with x86-64 was responsible for up to a 10% increase in performance.
The original ARM architecture made all instructions conditional, which had a huge impact on the instruction space. The number of conditional instructions is far more limited in ARMv8/A64.
The move to ARMv8 also doubles the number of FP/NEON registers (from 16 to 32) as well as widens all of them registers to 128-bits (up from 64-bits). Support for 128-bit registers can go a long way in improving SIMD performance. Whereas simply doubling register count can provide moderate increases in performance, doubling the size of each register can be far more significant given the right workload. There are also new advanced SIMD instructions that are a part of ARMv8. Double precision SIMD FP math is now supported among other things.
ARMv8 also adds some new cryptographic instructions for hardware acceleration of AES and SHA1/SHA256 algorithms. These hardware AES/SHA instructions have the potential for huge increases in performance, just like we saw with the introduction of AES-NI on Intel CPUs a few years back. Both the new advanced SIMD instructions and AES/SHA instructions are really designed to enable a new wave of iOS apps.
Many A64 instructions mode can also work with 32-bit operands, with properly implemented designs simply power gating unused bits. The A32 implementation in ARMv8 also adds some new instructions, so it’s possible to compile AArch32 apps in ARMv8 that aren’t backwards compatible. All existing ARMv7 and 32-bit Thumb code should work just fine however.
On the software side, iOS 7 as well as all first party apps ship already compiled for AArch64 operation. In fact, at boot, there isn’t a single AArch32 process running on the iPhone 5s:
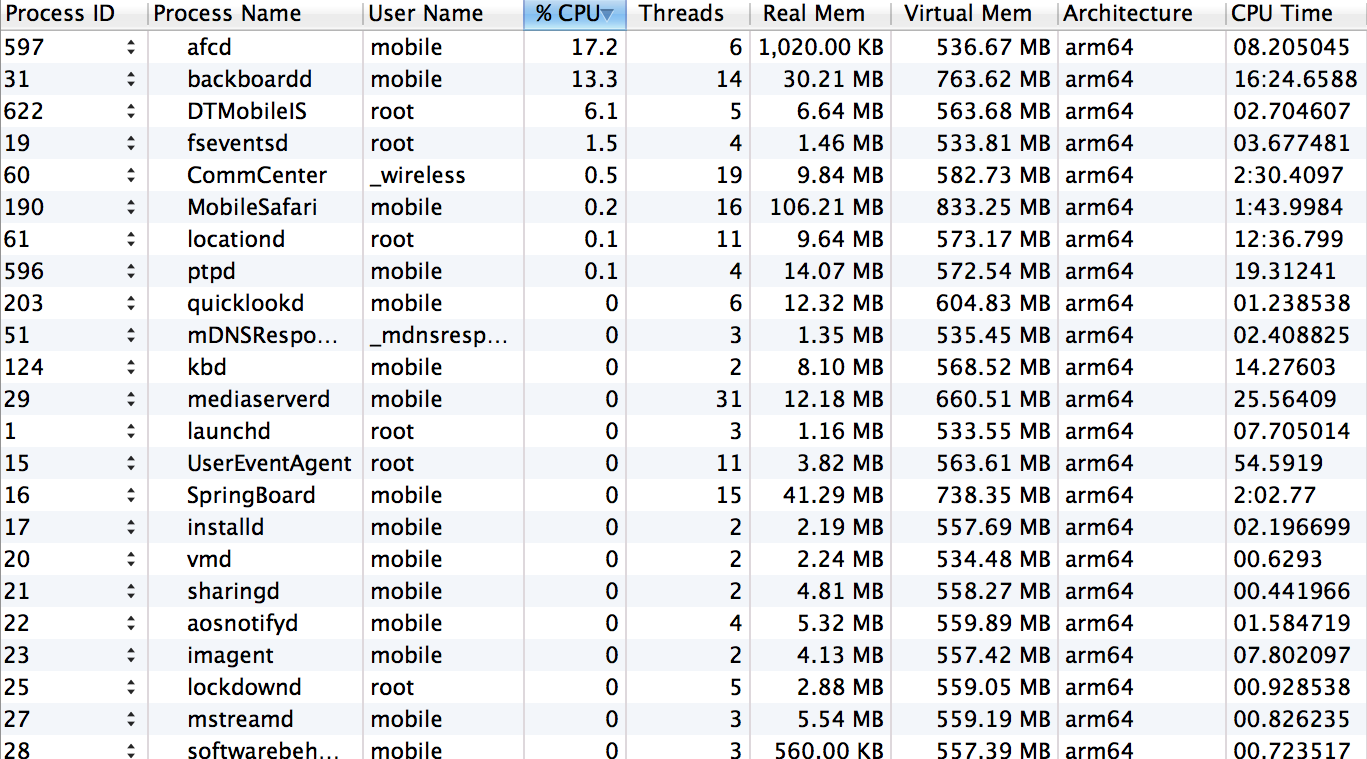
Safari, Mail, everything all made the move to 64-bit right away. Given the popularity of these first party apps, it’s not just the hardware that’s 64-bit ready but much of the software is as well. The industry often speaks about Apple’s vertically integrated advantage, this is quite possibly the best example of that advantage. In many ways it reminds me of the Retina Display transition on OS X.
Running A32 and A64 applications in parallel is seamless. On the phone itself, it’s impossible to tell when you’re running in a mixed environment or when everything you’re running is 64-bit. It all just works.
I didn’t run into any backwards compatibility issues with existing 32-bit ARMv7 apps either. From an end user perspective, navigating the 64-bit transition is as simple as buying an iPhone 5s.
64-bit Performance Gains
Geekbench 3 was among the first apps to be updated with ARMv8 support. There are some minor changes between the new version of Geekbench 3 and its predecessor (3.1/3.0), however the tests themselves (except for the memory benchmarks) haven't changed. What this allows us to do is look at the impact of the new ARMv8 A64 instructions and larger register space. We'll start with a look at integer performance:
| Apple A7 - AArch64 vs. AArch32 Performance Comparison | ||||||
| 32-bit A32 | 64-bit A64 | % Advantage | ||||
| AES | 91.5 MB/s | 846.2 MB/s | 825% | |||
| AES MT | 180.2 MB/s | 1640.0 MB/s | 810% | |||
| Twofish | 59.9 MB/s | 55.6 MB/s | -8% | |||
| Twofish MT | 119.1 MB/s | 110.2 MB/s | -8% | |||
| SHA1 | 138.0 MB/s | 477.3 MB/s | 245% | |||
| SHA1 MT | 275.7 MB/s | 948.9 MB/s | 244% | |||
| SHA2 | 86.1 MB/s | 102.2 MB/s | 18% | |||
| SHA2 MT | 171.3 MB/s | 203.7 MB/s | 18% | |||
| BZip2 Compress | 4.36 MB/s | 4.52 MB/s | 3% | |||
| BZip2 Compress MT | 8.57 MB/s | 8.86 MB/s | 3% | |||
| BZip2 Decompress | 5.94 MB/s | 7.56 MB/s | 27% | |||
| BZip2 Decompress MT | 11.7 MB/s | 15.0 MB/s | 28% | |||
| JPEG Compress | 15.5 MPixels/s | 16.8 MPixels/s | 8% | |||
| JPEG Compress MT | 30.8 MPixels/s | 33.3 MPixels/s | 8% | |||
| JPEG Decompress | 36.0 MPixels/s | 40.3 MPixels/s | 11% | |||
| JPEG Decompress MT | 71.3 MPixels/s | 78.1 MPixels/s | 9% | |||
| PNG Compress | 0.84 MPixels/s | 1.14 MPixels/s | 35% | |||
| PNG Compress MT | 1.67 MPixels/s | 2.26 MPixels/s | 35% | |||
| PNG Decompress | 13.9 MPixels/s | 15.2 MPixels/s | 9% | |||
| PNG Decompress MT | 27.4 MPixels/s | 29.8 MPixels/s | 8% | |||
| Sobel | 59.3 MPixels/s | 58.0 MPixels/s | -3% | |||
| Sobel MT | 116.6 MPixels/s | 114.6 MPixels/s | -2% | |||
| Lua | 1.25 MB/s | 1.33 MB/s | 6% | |||
| Lua MT | 2.47 MB/s | 2.49 MB/s | 0% | |||
| Dijkstra | 5.35 MPairs/s | 4.05 MPairs/s | -25% | |||
| Dijkstra MT | 9.67 MPairs/s | 7.26 MPairs/s | -25% | |||
The AES and SHA1 gains are a direct result of the new cryptographic instructions that are a part of ARMv8. The AES test in particular shows nearly an order of magnitude performance improvement. This is similar to what we saw in the PC space with the introduction of Intel's AES-NI support in Westmere. The Dijkstra workload is the only real regression. That test in particular appears to be very pointer heavy, and the increase in pointer size from 32 to 64-bit increases cache pressure and causes the reduction in performance. The rest of the gains are much smaller, but still fairly significant if you take into account the fact that we're just looking at what you get from a recompile. Add these gains to the ones you're about to see over Apple's A6 SoC and A7 is looking really good from a performance standpoint.
If the integer results looked good, the FP results are even better:
| Apple A7 - AArch64 vs. AArch32 Performance Comparison | ||||||
| 32-bit A32 | 64-bit A64 | % Advantage | ||||
| BlackScholes | 4.73 MNodes/s | 5.92 MNodes/s | 25% | |||
| BlackScholes MT | 9.57 MNodes/s | 12.0 MNodes/s | 25% | |||
| Mandelbrot | 930.2 MFLOPS | 929.9 MFLOPS | 0% | |||
| Mandelbrot | 1840 MFLOPS | 1850 MFLOPS | 0% | |||
| Sharpen Filter | 805.1 MFLOPS | 857 MFLOPS | 6% | |||
| Sharpen Filter MT | 1610 MFLOPS | 1710 MFLOPS | 6% | |||
| Blur Filter | 1.08 GFLOPS | 1.26 GFLOPS | 16% | |||
| Blur Filter MT | 2.15 GFLOPS | 2.47 GFLOPS | 14% | |||
| SGEMM | 3.09 GFLOPS | 3.34 GFLOPS | 8% | |||
| SGEMM MT | 6.08 GFLOPS | 6.56 GFLOPS | 7% | |||
| DGEMM | 0.56 GFLOPS | 1.66 GFLOPS | 195% | |||
| DGEMM MT | 1.11 GFLOPS | 3.24 GFLOPS | 191% | |||
| SFFT | 0.72 GFLOPS | 1.59 GFLOPS | 119% | |||
| SFFT MT | 1.44 GFLOPS | 3.17 GFLOPS | 120% | |||
| DFFT | 1.41 GFLOPS | 1.47 GFLOPS | 4% | |||
| DFFT MT | 2.78 GFLOPS | 2.91 GFLOPS | 4% | |||
| N-Body | 460.8 KPairs/s | 582.6 KPairs/s | 26% | |||
| N-Body MT | 917.6 KPairs/s | 1160.0 KPairs/s | 26% | |||
| Ray Trace | 1.52 MPixels/s | 2.31 MPixels/s | 51% | |||
| Ray Trace MT | 3.04 MPixels/s | 4.64 MPixels/s | 52% | |||
The DGEMM operations aren't vectorized under ARMv7, but they are under ARMv8 thanks to DP SIMD support so you get huge speedups there from the recompile. The SFFT workload benefits handsomely from the increased register space, significantly reducing the number of loads and stores (there's something like a 30% reduction in instructions for the A64 codepath compared to the A32 codepath here). The conclusion? There are definitely reasons outside of needing more memory to go 64-bit.
A7 and OS X
Before I spent time with the A7 I assumed the only reason Apple would go 64-bit in mobile is to prepare for eventually deploying these chips into larger machines. A couple of years ago, when the Apple/Intel relationship was at its rockiest I would've definitely said that's what was going on. Today, I'm far less convinced.
Apple continues to build its own SoCs and invest in them because honestly, no one else seems up to the job. Only recently do we have GPUs competitive with what Apple has been shipping, and with the A7 Apple nearly equals Intel's performance with Bay Trail on the CPU side. As far as Macs go though, there's still a big gap between the A7 and where Intel is at with Haswell. The deficiency that Intel had in the ultra mobile space simply doesn't translate to its position with the big Core chips. I don't see Apple bridging that gap anytime soon. On top of that, the Apple/Intel relationship is very good at this point.
Although Apple could conceivably keep innovating to the point where an A-series chip ends up powering a Mac, I don't think that's in the cards today.








464 Comments
View All Comments
AngryCorgi - Thursday, November 14, 2013 - link
The math used in this article is incorrect. It is 76.8 GFLOPS per CORE not for the entire GPU. The GPU should be capable of 307.2 GFLOPS. The rest of that chart is wrong as well in most places.@650MHZ, per core, G6430 = 166.4 GFLOPS, (*300/650) = 76.8 GFLOPS, (*4) = 307.2 GFLOPS
ronnieryan - Saturday, January 11, 2014 - link
@Anand : Sir could you make a review on the history of the iphone's home button? i would really want to know how tough the iPhone 5s home button. I was an android user and wanted to try something new. New in a sense of a 64 bit processor. But i want to know how strong is the 5s home button. Please do make a review of the home button, i would really want to know. email me for the link if its ok...Thanks :Dcasualphoenix - Wednesday, January 22, 2014 - link
Hi Anand,Hope you're doing well today. My name is Nate Humphries and I'm the Tech/Science editor at CultureMass.com.
I've been reading through your iPhone 5S and iPad Air articles in preparation for an article about the A7 chip, and it's been an extremely informative read. I wanted to ask if I could use your benchmark charts in my article if I provide proper citation back to your article. I think they would be very helpful for our readers.
Let me know how that sounds, and I look forward to hearing back from you.
Thanks,
Nate Humphries
Tech/Science Editor | CultureMass
nate.humphries@culturemass.com
besweeet - Sunday, March 30, 2014 - link
I'm curious as to how this website did their 4G LTE tests... On AT&T, I could probably achieve those numbers. Swap that SIM out for one from T-Mobile, and regardless of signal strength, numbers would dramatically decrease instantly.