Choosing a Gaming CPU: Single + Multi-GPU at 1440p, April 2013
by Ian Cutress on May 8, 2013 10:00 AM ESTCPU Benchmarks
Point Calculations - 3D Movement Algorithm Test
The algorithms in 3DPM employ both uniform random number generation or normal distribution random number generation, and vary in amounts of trigonometric operations, conditional statements, generation and rejection, fused operations, etc. The benchmark runs through six algorithms for a specified number of particles and steps, and calculates the speed of each algorithm, then sums them all for a final score. This is an example of a real world situation that a computational scientist may find themselves in, rather than a pure synthetic benchmark. The benchmark is also parallel between particles simulated, and we test the single threaded performance as well as the multi-threaded performance.
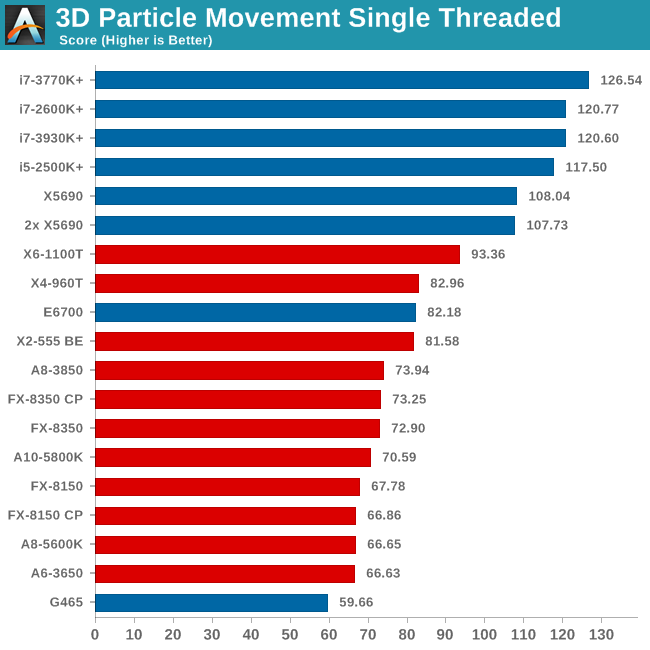
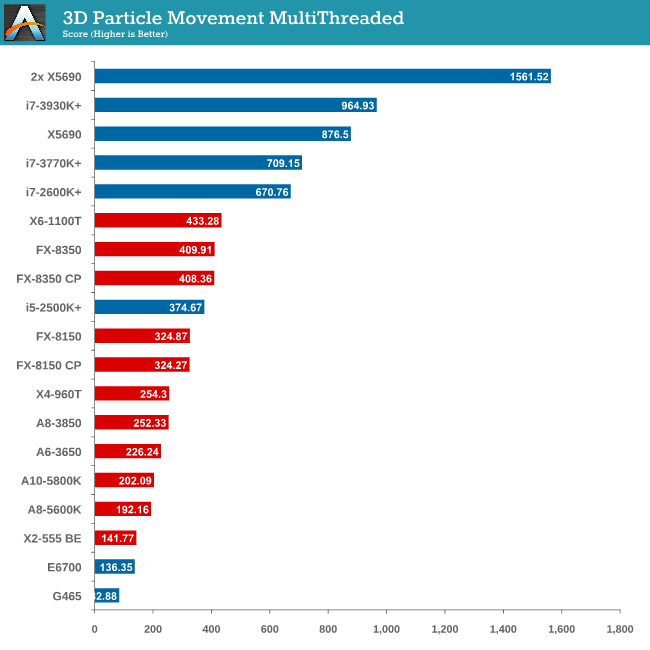
As mentioned in previous reviews, this benchmark is written how most people would tackle the situation – using floating point numbers. This is also where Intel excels, compared to AMD’s decision to move more towards INT ops (such as hashing), which is typically linked to optimized code or normal OS behavior.
Compression - WinRAR x64 3.93 + WinRAR 4.2
With 64-bit WinRAR, we compress the set of files used in our motherboard USB speed tests. WinRAR x64 3.93 attempts to use multithreading when possible and provides a good test for when a system has variable threaded load. WinRAR 4.2 does this a lot better! If a system has multiple speeds to invoke at different loading, the switching between those speeds will determine how well the system will do.
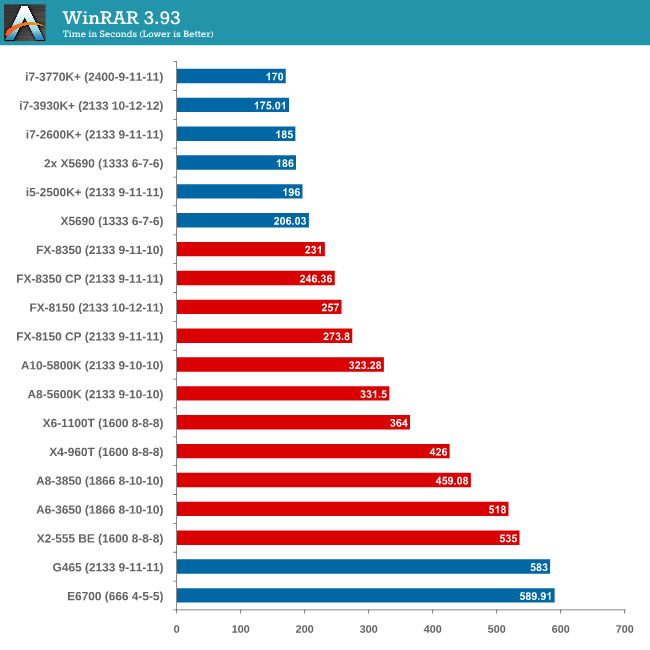
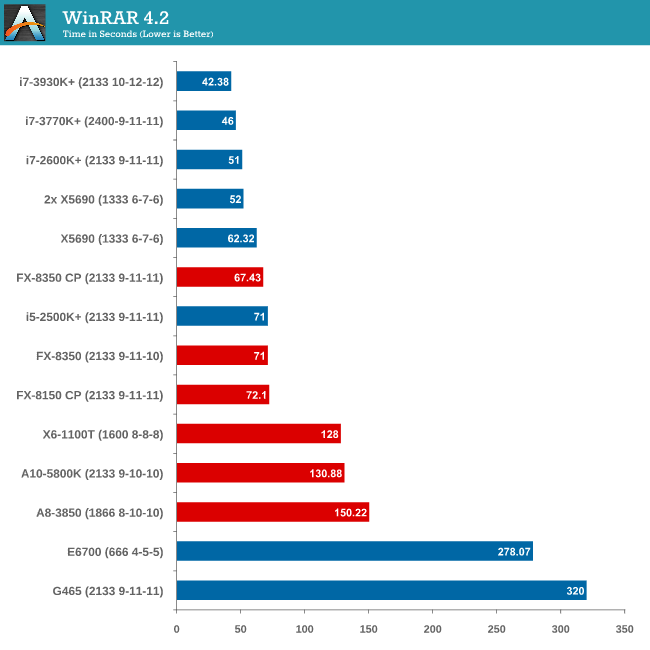
Due to the late inclusion of 4.2, our results list for it is a little smaller than I would have hoped. But it is interesting to note that with the Core Parking updates, an FX-8350 overtakes an i5-2500K with MCT.
Image Manipulation - FastStone Image Viewer 4.2
FastStone Image Viewer is a free piece of software I have been using for quite a few years now. It allows quick viewing of flat images, as well as resizing, changing color depth, adding simple text or simple filters. It also has a bulk image conversion tool, which we use here. The software currently operates only in single-thread mode, which should change in later versions of the software. For this test, we convert a series of 170 files, of various resolutions, dimensions and types (of a total size of 163MB), all to the .gif format of 640x480 dimensions.
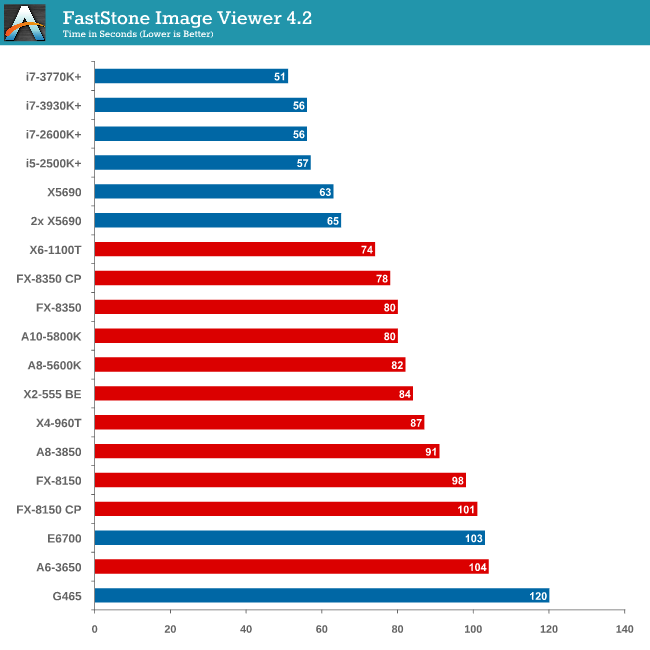
In terms of pure single thread speed, it is worth noting the X6-1100T is leading the AMD pack.
Video Conversion - Xilisoft Video Converter 7
With XVC, users can convert any type of normal video to any compatible format for smartphones, tablets and other devices. By default, it uses all available threads on the system, and in the presence of appropriate graphics cards, can utilize CUDA for NVIDIA GPUs as well as AMD WinAPP for AMD GPUs. For this test, we use a set of 33 HD videos, each lasting 30 seconds, and convert them from 1080p to an iPod H.264 video format using just the CPU. The time taken to convert these videos gives us our result.
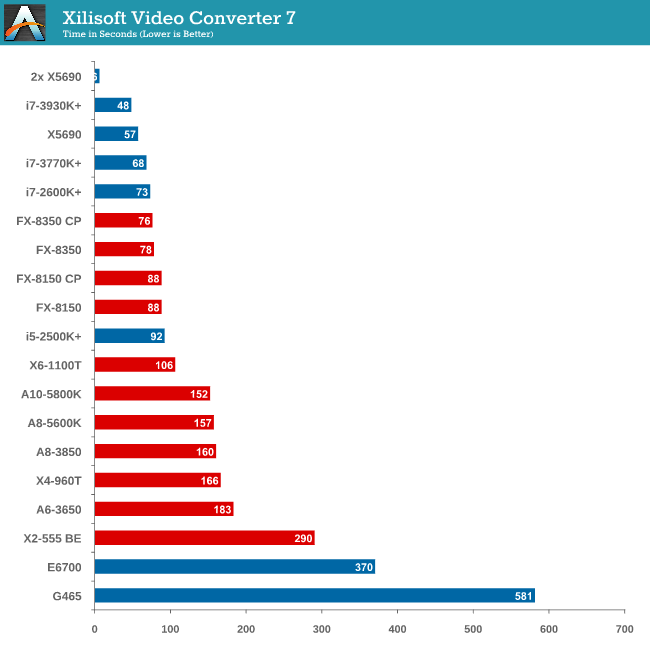
XVC is a little odd in how it arranges its multicore processing. For our set of 33 videos, it will arrange them in batches of threads – so if we take the 8 thread FX-8350, it will arrange the videos into 4 batches of 8, and then a fifth batch of one. That final batch will only have one thread assigned to it (!), and will not get a full 8 threads worth of power. This is also why the 2x X5690 finishes in 6 seconds but the normal X5690 takes longer – you would expect a halving of time moving to two CPUs but XVC arranges the batches such that there is always one at the end that only gets a single thread.
Rendering – PovRay 3.7
The Persistence of Vision RayTracer, or PovRay, is a freeware package for as the name suggests, ray tracing. It is a pure renderer, rather than modeling software, but the latest beta version contains a handy benchmark for stressing all processing threads on a platform. We have been using this test in motherboard reviews to test memory stability at various CPU speeds to good effect – if it passes the test, the IMC in the CPU is stable for a given CPU speed. As a CPU test, it runs for approximately 2-3 minutes on high end platforms.
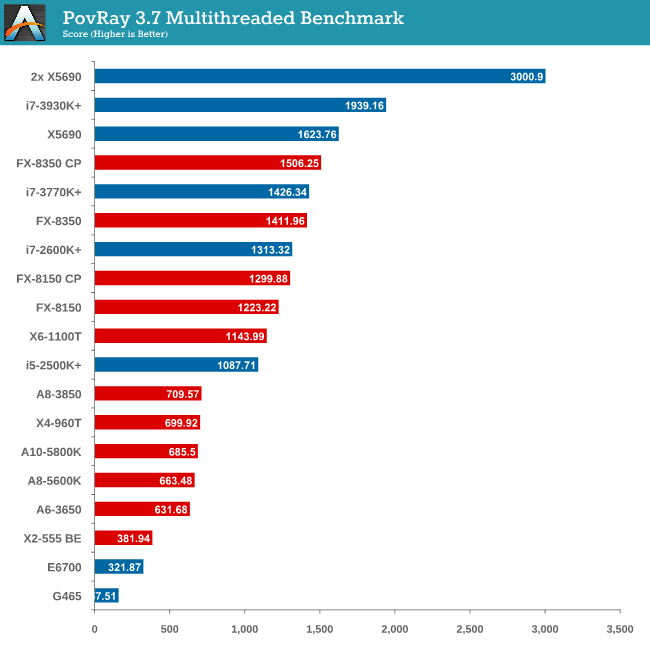
The SMP engine in PovRay is not perfect, though scaling up in CPUs gives almost a 2x effect. The results from this test are great – here we see an FX-8350 CPU below an i7-3770K (with MCT), until the Core Parking updates are applied, meaning the FX-8350 performs better!
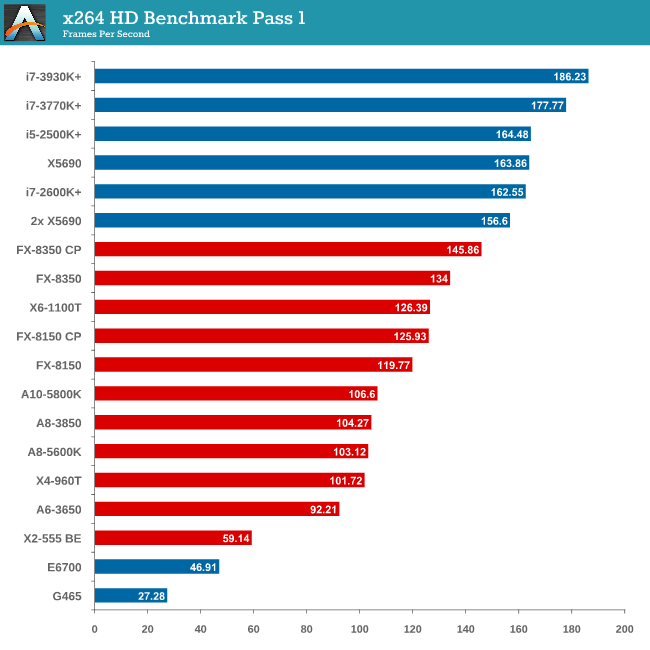
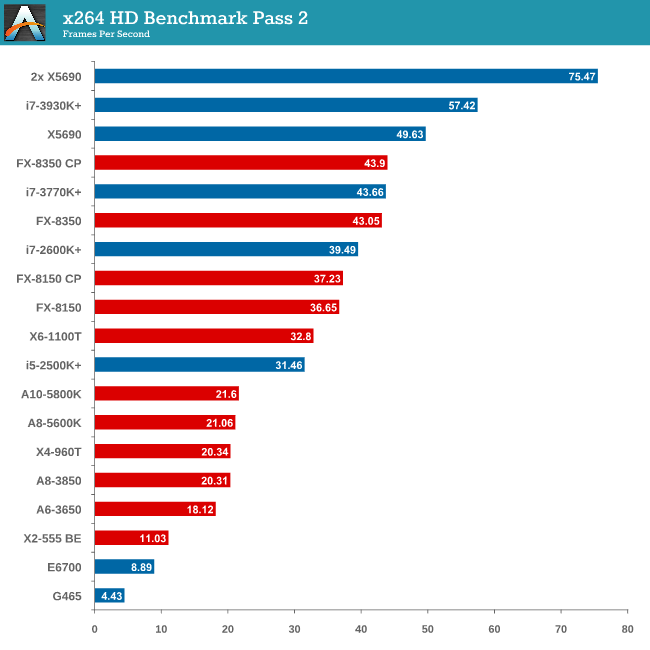
Video Conversion - x264 HD Benchmark
The x264 HD Benchmark uses a common HD encoding tool to process an HD MPEG2 source at 1280x720 at 3963 Kbps. This test represents a standardized result which can be compared across other reviews, and is dependent on both CPU power and memory speed. The benchmark performs a 2-pass encode, and the results shown are the average of each pass performed four times.
Grid Solvers - Explicit Finite Difference
For any grid of regular nodes, the simplest way to calculate the next time step is to use the values of those around it. This makes for easy mathematics and parallel simulation, as each node calculated is only dependent on the previous time step, not the nodes around it on the current calculated time step. By choosing a regular grid, we reduce the levels of memory access required for irregular grids. We test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
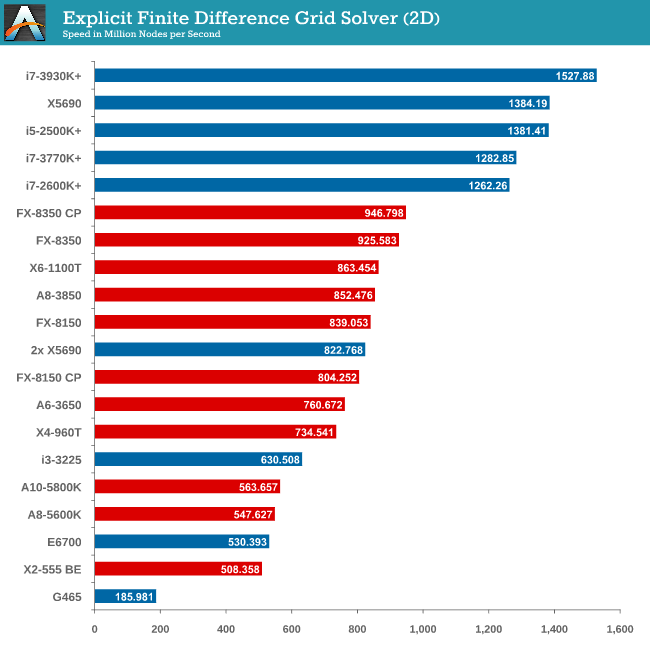
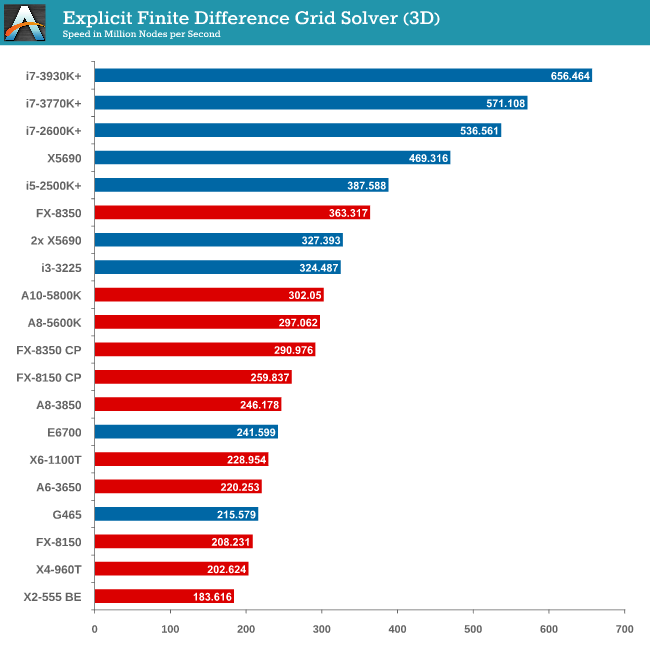
Grid solvers do love a fast processor and plenty of cache in order to store data. When moving up to 3D, it is harder to keep that data within the CPU and spending extra time coding in batches can help throughput. Our simulation takes a very naïve approach in code, using simple operations.
Grid Solvers - Implicit Finite Difference + Alternating Direction Implicit Method
The implicit method takes a different approach to the explicit method – instead of considering one unknown in the new time step to be calculated from known elements in the previous time step, we consider that an old point can influence several new points by way of simultaneous equations. This adds to the complexity of the simulation – the grid of nodes is solved as a series of rows and columns rather than points, reducing the parallel nature of the simulation by a dimension and drastically increasing the memory requirements of each thread. The upside, as noted above, is the less stringent stability rules related to time steps and grid spacing. For this we simulate a 2D grid of 2n nodes in each dimension, using OpenMP in single precision. Again our grid is isotropic with the boundaries acting as sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
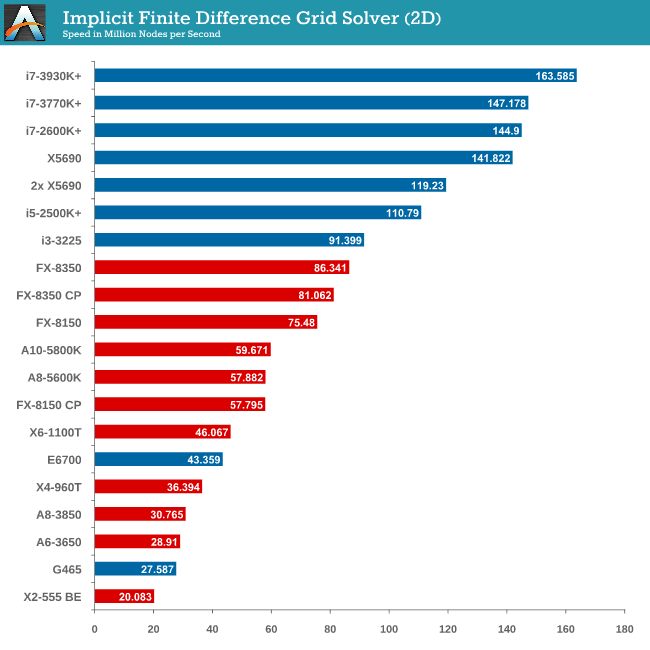
2D Implicit is harsher than an Explicit calculation – each thread needs more a lot memory, which only ever grows as the size of the simulation increases.
Point Calculations - n-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions. The benchmark detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. We run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.
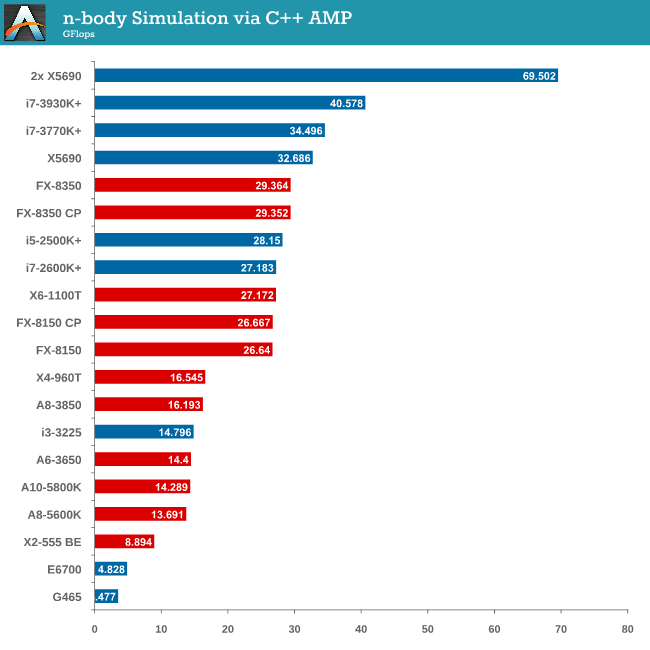
As we only look at base/SSE2/SSE4 depending on the processor (auto-detection), we don’t see full AVX numbers in terms of FLOPs.








242 Comments
View All Comments
aburhinox - Wednesday, May 8, 2013 - link
This is a great article to compare cpus across multiple gpus. I'd also be curious to see how different GPUs scale. I'd like to see if a single $400 card is better than 2 $200 cards. I'm going to say that given the choice between one or two $400 cards, two is better than one. Going to the extreme would get you to ask if you want to go crazy, if four $100 cards is better than 1 $400 card. That would probably be going too far since you have to end up with expensive motherboards to support four gpus. But I think that would make a useful article about gpus.dwatterworth - Wednesday, May 8, 2013 - link
Thank you for putting the DP Xeon platform in. I imagine it is a niche market but a platform parallel to that in an older generation would be a huge help. I have an aging LGA 771 Asus Z7S-WS board with (2) e5472 procs with (1) 7950 w/boost. The system was built for 3D rendering and architectural work and as 2 systems are not affordable, this became my gaming machine as well. Other than putting my own benchmarks up against what I can find here or other sites it is very hard for me to decide when and to what to upgrade. I greatly appreciate the Xeon inclusion on this as there are some (few?) who fall into the work + play on a single machine scenario.xinthius - Wednesday, May 8, 2013 - link
You, my friend, just made me laugh well and truly, thank you."his intelligence will diminish gradually." Speaking from experience I see?
kyuu - Wednesday, May 8, 2013 - link
Maybe this is a dumb question, but shouldn't the Core Parking updates also be beneficial to the APUs? They're still using the same module architecture as the FX chips.IanCutress - Wednesday, May 8, 2013 - link
That's planned for the next update, after Haswell launch. At the time I completely forgot and went on to the next platform. Need to pull out the FM2 test bed, install an OS and retest them - another day of testing at least (!). But it's on the 'to do' list.Ian
kyuu - Wednesday, May 8, 2013 - link
Cool, thanks for the reply Ian.antonyt - Wednesday, May 8, 2013 - link
This analysis is great! And extremely useful for anyone contemplating a gaming build in the near future (as I am). I look forward to seeing your updates and more articles like this.Btw, minor typo ("future") at the very end--"but we hope on expanding this in the fuiture."
IanCutress - Wednesday, May 8, 2013 - link
Fixed the typo, cheers :)felang - Wednesday, May 8, 2013 - link
Only if you plan to play single player games onlyxinthius - Wednesday, May 8, 2013 - link
You agree with the fact your intelligence has diminished? Okay.I would LOVE to see you design a microprocessor as complex as one of AMDs. Their processors actually perform admirably in highly threaded workloads, while their current architecture is weak in the IPC department. Their CPUs are by no means weak and should still be recommend in some circumstances, such as their APU range. Please try and post intelligently, I know it's hard for you.