Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
Two Dimensional Implicit Finite Difference
The ‘Finite Difference’ part of this computational grid solver means that the derivation of this method is similar to that shown in the Explicit Finite Difference method on the previous page. We are presented with the following equation which explains Fick’s first law of diffusion for mass transport in three dimensions:
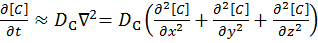 [8]
[8]
The implicit method takes the view that the concentrations at time t+1 are a series of unknowns, and the equations are thus coupled into a series of simultaneous equations with an equal set of unknowns, which must be solved together:
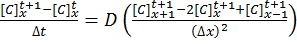 [9]
[9]
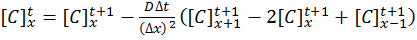 [10]
[10]
The implicit method is algorithmically more complex than the explicit method, but does offer the advantage of unconditional stability with respect to time.
The Alternating Direction Implicit (ADI) Method
For a system in two dimensions (labelled r and z), such as a microdisk simulation, the linear system has to be solved in both directions using Fick’s Laws:
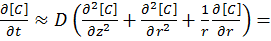
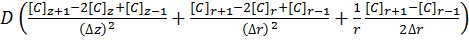 [11]
[11]
The alternating direction implicit (ADI) method is a straightforward solution to solving what are essentially two dimensional simultaneous equations whilst retaining a high degree of algorithm stability.
ADI splits equation [11] into two half time steps – by treating one dimension explicitly and the other dimension implicitly in the same half time step. Thus the explicit values known in one direction are fed into the series of simultaneous equations to solve the other direction. For example, using the r direction explicitly to solve the z direction implicitly:
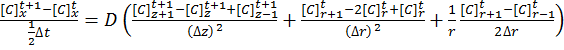 [12]
[12]
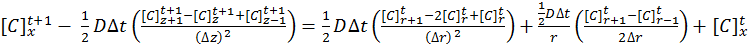 [13]
[13]
By solving equation [13] for the concentrations in the z direction, the next half time step concentrations can be calculated for the r direction, and so on until the desired time in simulation is achieved. These time step equations are solved using the Thomas Algorithm for tri-diagonal matrices.
Application to this Review
For the purposes of this review, we generate an x-by-x grid of points with a relative concentration of 1, where the boundaries are fixed at a relative concentration of 0. The grid is a regular grid, simplifying calculations. The nature of the simulation allows that for each half-time step to focus on calculating in one dimension, for a simulation of x-by-x nodes we can spawn x threads as adjacent rows/columns (depending on direction) are independent. These threads, in comparison to the explicit finite difference, are substantially bulkier in terms of memory usage.
The code was written in Visual Studio C++ 2012 with OpenMP as the multithreaded source. The main function to do the calculations is as follows.

For our scores, we increase the size of the grid from a 2x2 until we hit 2GB memory usage. At each stage, the time taken to repeatedly process the grid over many time steps is calculated in terms of ‘million nodes per second’, and the peak value is used for our results.
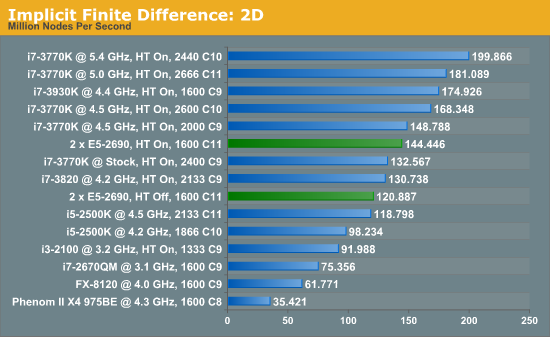
Previously where the explicit 2D method was indifferent to HyperThreading and the explicit 3D method was very sensitive; the implicit 2D is a mix of both. There are still benefits to be had from enabling HyperThreading. Nevertheless, the line between single processor systems and dual processors is being blurred a little due to the different speeds of the SP results, but in terms of price/performance, the DP system is at the wrong end.








64 Comments
View All Comments
dj christian - Monday, January 14, 2013 - link
No please!This article should be a one time only or once every 2 years at most.
nadana23 - Sunday, January 6, 2013 - link
From the looks of results some of the benchmarks are HIGHLY sensitive to effective bandwidth per thread (ie, GDDR5 feeding a GPU stream processor >> DDR3 feeding a Xeon HT core).However - it must be noted that 8x DIMMS is insufficient to achieve full memory bandwidth on Xeon E5 2S!
I'd suggest throwing a pure memory bandwidth test into the mix to make sure you're actually getting the rated number (51.2GB/s)...
http://ark.intel.com/products/64596/Intel-Xeon-Pro...
... as I strongly suspect your memory config is crippling results.
Dell's 12G config guidelines are as good a place as any to start on this :-
http://en.community.dell.com/cfs-file.ashx/__key/c...
Simply removing one E5-2590 and moving to 1-Package, 8 DIMM config may (counter-intuitively) bench(market) faster... for you.
dapple - Sunday, January 6, 2013 - link
Great article, thanks! This is the sort of benchmark I've been wanting to see for quite some time now - simple, brute-force numerics where the code is visible and straightforward. Too many benchmarks are black boxes with processor- and compiler-specific tunes to make manufacturer "X" appear superior to "Y". That said, it would be most illustrative to perform a similar 'mark using vanilla gcc on both MS and *nix OS.daosis - Sunday, January 6, 2013 - link
It is long known issue, when windows does not start after changing hardware, especially GPU (not always so). There is as long known trick so. Just before last "power off" one should replace GPU's own driver with basic microsoft's one. In case of GPU it is "standart Vga adapter" (device manager - update driver - browse my computer - let me pick up). In fact one can replace all specific drivers on OS with similiar basic from MS and then to put this hard drive virtually to any system without any need for fresh install. Mind you, that after first boot it takes some time for OS to find and install specific drivers.jamesf991 - Sunday, January 6, 2013 - link
In the early '70s I was doing very similar simulations using a PDP 11/40 minicomputer. (I can send citations to my publications if anyone is interested.) At Texas Tech and later at Caltech, I simulated systems involving heterogeneous electron transfer kinetics, various chemical reactions in solution, coulostatics, galvanostatics, voltammetry, chronocoulometry, AC voltammetry, migration, double layer effects, solution hydrodynamics (laminar only), etc. Much of this was done on a PDP 11/40, originally with 8K words (= 16K bytes) of core memory. Later the machine was upgraded to 24 K words (!), we got a floating point board, and a hard disk drive (5 M words, IIRC). My research director probably paid in excess of $50K for the hardware. One cute project was to put a simulation "inside" a nonlinear regression routine to solve for electrode kinetic parameters such as k and alpha. Each iteration of the nonlinear solver required a new simulation -- hand-coding the innermost loops using floating point assembly instructions was a big speedup!I wonder how the old PDP would stack up against the 3770?
flynace - Monday, January 7, 2013 - link
Do you guys think that once Haswell moves the VRM on package that someone might do a 2 socket mATX board?Even if it means giving up 2 of the 4 PCIe slots and/or 2 DIMMs per socket it would be nice to have a high core count standard SFF board for those that need just that.
samsp99 - Monday, January 7, 2013 - link
I found this review interesting, but I don't think this board is really targeted at the HPC market. It seems like it would be good as part of a 2U / 12 + 2 drive system, similar to the Dell C2100. It would make a good virtual host, SQL, active web server etc. Having the 3 mSAS connectors would enable 4 drive each without the need for a SAS expander.Servers are designed for 99.999% uptime, remote management, and hands-off operation. To achieve that you need redundent power, UPS, Networking, storage etc. They also require high airflow, which is noisy and not something you want sitting under your desk. Based on that, it makes sense that the MB is intended for sale to system builders not your general build your own enthusiast.
HW manufactuerers are faced with a similar problem to airlines - consumers gravitate to the cheapest price, and so the only real money to be made is selling higher profit margin products to businesses. Servers are where intel etc makes their profits.
For the computational problems the author is trying to solve, to me it would seem to be better to consider:
a) At one point, I think google was using commodity hardware, with custom shelving etc. Assuming the algorithms can be paralleled on different hosts, you shouldn't need the reliability of traditional servers, so why not use a number of commodity systems together, choosing the components that have the best perf/$.
b) There are machines designed for HPC scenarios, such as HPC Systems E5816 that supports 8x Xeon E7-8000 (10 core) processors, or the E4002G8 - that will take 8 nVidia Tesla cards.
c) What about developing and testing the software on cheap worstations, and then when you are sure its ready, buying compute time from Amazon cloud services etc.
babysam - Monday, January 7, 2013 - link
It is quite delighting to look at your review on Anandtech (especially when I am using software and computer configurations of similar nature for my studies), as it is quite difficult for me to evaluate the performance gain of "real-life" software (i.e. science oriented in my case) on new hardware before buying.From what I have seen in your code segments provided (especially for the n-body simulation part) , there are large amount of floating-point divisions. Is there any possibility that the code is not only limited by the cache size(and thrashing), but by the limited throughput of the floating-point divider? (i.e. The performance degradations when HT is enabled may also be caused by the competition of the two running threads on the only floating-point divider in the core)
SanX - Tuesday, January 8, 2013 - link
if you post zipped sources and exes for anyone to follow, learn, play, argue and eventually improve.I'd also preferred to see Fortran sources and benchmarks when possible.
Intel/AMD should start promote 2/4/8 socket monster mobos for enthusiasts and then general public since this is the beginning of the infinite in time era for multiprocessing.
Also where are games benchmarks like for example GTA4 which benefits a lot from multicores as well as from GPUs?
IanCutress - Wednesday, January 9, 2013 - link
The n-body simulations are part of the C++ AMP example page, free for everyone to use. The rest of the code is part of a benchmark package I'm creating, hence I only give the loops in the code. Unfortunately I know no Fortran for benchmarks.Most mainstream users (i.e. gamers) still debate whether 4 or 6 cores are even necessary, so moving to 2P/4P/8P is a big leap in that regard. Enthusiasts can still get the large machines (a few folders use quad AMD setups) if they're willing to buy from ebay which may not always be wholly legal. You may see 2P/4P/8P becoming more mainstream when we start to hit process node limits.
Ian