Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
Many thanks to...
We must thank the following companies for kindly donating hardware for our test bed:
OCZ for donating the Power Supply and USB testing SSD
Micron for donating our SATA testing SSD
Kingston for donating our ECC Memory
ASUS for donating AMD GPUs
ECS for donating NVIDIA GPUs
Test Setup
| Test Setup | |
| Processor |
2x Intel Xeon E5-2690 8 Cores, 16 Threads, 2.9 GHz (3.8 GHz Turbo) each |
| Motherboards | Gigabyte GA-7PESH1 |
| Cooling |
Intel AIO Liquid Cooler Corsair H100 |
| Power Supply | OCZ 1250W Gold ZX Series |
| Memory | Kingston 1600 C11 ECC 8x4GB Kit |
| Memory Settings | 1600 C11 |
| Video Cards |
ASUS HD7970 3GB ECS GTX 580 1536MB |
| Video Drivers |
Catalyst 12.3 NVIDIA Drivers 296.10 WHQL |
| Hard Drive | Corsair Force GT 60 GB (CSSD-F60GBGT-BK) |
| Optical Drive | LG GH22NS50 |
| Case | Open Test Bed - DimasTech V2.5 Easy |
| Operating System | Windows 7 64-bit |
| SATA Testing | Micron RealSSD C300 256GB |
| USB 2/3 Testing | OCZ Vertex 3 240GB with SATA->USB Adaptor |
Power Consumption
Power consumption was tested on the system as a whole with a wall meter connected to the OCZ 1250W power supply, with a single 7970 GPU installed. This power supply is Gold rated, and as I am in the UK on a 230-240 V supply, leads to ~75% efficiency > 50W, and 90%+ efficiency at 250W, which is suitable for both idle and multi-GPU loading. This method of power reading allows us to compare the power management of the UEFI and the board to supply components with power under load, and includes typical PSU losses due to efficiency. These are the real world values that consumers may expect from a typical system (minus the monitor) using this motherboard.
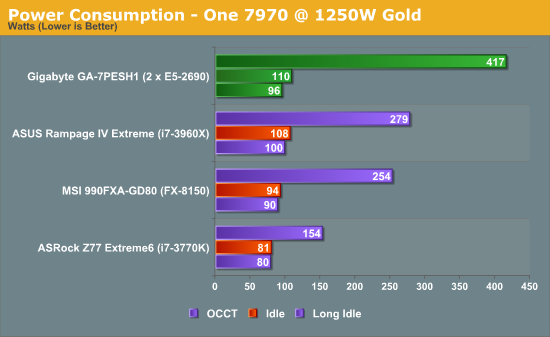
Using two E5-2690 processors would mean a combined TDP of 270W. If we make the broad assumption that the processors combined use 270W under loading, this places the rest of the motherboard at around 110-130W, which is indicated by our idle numbers (despite PSU efficiency).
POST Time
Different motherboards have different POST sequences before an operating system is initialized. A lot of this is dependent on the board itself, and POST boot time is determined by the controllers on board (and the sequence of how those extras are organized). As part of our testing, we are now going to look at the POST Boot Time - this is the time from pressing the ON button on the computer to when Windows starts loading. (We discount Windows loading as it is highly variable given Windows specific features.) These results are subject to human error, so please allow +/- 1 second in these results.

The boot time on this motherboard is a lot longer than anything I have ever experienced. Firstly, when the power supply is switched on, there is a 30 second wait (indicated by a solid green light that turns into a flashing green light) before the motherboard can be switched on. This delay is to enable the management software to be activated. Then, after pressing the power switch, there is around 60 seconds before anything visual comes up on the screen. Due to the use of the Intel NICs, the LSI SAS RAID chips and other functionality, there is another 53 seconds before the OS actually starts loading. This means there is about a 2.5 minute wait from power at the wall enabled to a finished POST screen. Stripping the BIOS by disabling the extra controllers gives a sizeable boost, reducing the POST time by 35 seconds.








64 Comments
View All Comments
Hakon - Saturday, January 5, 2013 - link
Thank you for the detailed answer. I very much appreciate your article and hope to see more stuff like this on Anandtech.What I meant regarding to NUMA is the following. When you have a dual socket Xeon you have two memory controllers. The first time you 'touch' a memory location it is assigned to the memory controller of the CPU that runs the current thread. This assignment is in general permanent and all further memory read/writes to that location will be served by that memory controller.
If you first-touch (e.g. initialize the array to zero) using one thread, then the whole array is assigned to one of the two memory controllers. When you then run the multi-threaded code on that array one memory controller is idle while the other is oversubscribed since it has to serve both CPUs.
In contrast, if you first-touch your array in an OpenMP loop and use the same access pattern as in the algorithm, you will benefit from both memory controllers later on. In this case your large array is correctly 'distributed' over both memory controllers.
This kind of memory layout optimization becomes extremely important when you deal with quad socket Opterons. You then have eight memory controllers. A NUMA aware code is therefore up to eight times as fast since it utilizes all memory controllers.
toyotabedzrock - Saturday, January 5, 2013 - link
You should go ask the people on the assembly boards for help with making your code faster.They are very friendly compared to a Linux kernel devs, I think they just enjoy the acknowledgement that they still exist and are useful.
snajpa - Saturday, January 5, 2013 - link
Blame the scheduler. Neither Windows nor linux can effectively handle larger NUMA systems. It randomly moves the process across the physical hardware.psyq321 - Sunday, January 6, 2013 - link
Hmm, this is definitely not true at least for Windows Server 2008 R2 / Windows 7, and I am sure it holds true for some versions of Linux (I am not a Linux expert).Windows Server 2008 R2 / Windows 7 scheduler will try to match the memory allocations (even if they are not tagged for a specific NUMA node) with the NUMA node the process/thread resides on, and they will not move a thread to a foreign NUMA node unless if that has been explicitly requested by the application (by setting the thread affinity)
Of course, without explicit NUMA node tagging when doing allocations, application code is the main culprit for not respecting the NUMA layout (e.g. creating bunch of threads, allocating memory from one of them - and then pinning the threads to different CPUs - you will have lots of LLC requests from remote DRAM because memory was a-priori allocated on one node).
For this - some sane coding helps a lot, here:
http://www.dimkovic.com/node/15
I describe how I extracted more than double performance by careful memory allocation (NUMA-aware) - please note that neither Windows nor Linux scheduler is able to cope with code which is not written to be NUMA aware and it is using large number of threads that are supposed to run on all CPUs.. Simply put, application writer will have to manage memory allocation and usage in the way so that there are as little remote DRAM requests as possible.
snajpa - Sunday, January 6, 2013 - link
About Windows scheduler - I only worked with Windows XP, now I don't have any reason to work with Win anymore, so what you say probably is really true. As for the linux versions - well, long story short, CFS sucks and everyone knows it - this is particularly noticeable if you have fully virtualized VMs which appear as one single process at the host system - the process is randomly swapped between CPU cores and even CPU dies.... sad story. That's why people have to pin their CPUs to their tasks manually.psyq321 - Sunday, January 6, 2013 - link
Ah, XP - that explains it. True, XP did not care about NUMA at all.Windows Server 2008 / Vista introduced NUMA-aware memory allocations, and changed their CPU scheduler so it does not move the thread across NUMA nodes. They will also try to allocate the memory from the thread's own NUMA node when legacy VirtualAlloc etc. APIs are used.
Windows Server 2008 R2 / Windows 7 introduced the concept of CPU groups - allowing more than 64 CPUs. This does require some adaptation of the application, as old threading APIs only work with 64-bit affinity bitmask which only allowed recognizing 64 CPUs. Now, there is a new set of APIs that work with GROUP_AFFINITY structure, allowing control of CPU groups, too. However, this needs explicit change of the legacy process/threading APIs to the new ones.
Furthermore, none of the above can replace some manual intervention*- while Windows scheduler will, indeed, respect NUMA node boundaries and not try to mess around with moving threads across them - it still does not know what the underlying algorithm wants to do.
* There is no need to set the thread affinity to one specific CPU anymore - this prevents running the thread on any other CPU completely. Instead, there is an API called SetThreadIdealProcessor(Ex) which signals Windows scheduler that thread >should< run on that particular CPU - but, under certain circumstances the scheduler can move the thread somewhere else - if the CPU is completely taken away by some other thread/process. Scheduler will try to move the thread as close as possible - to the next core in the socket, for example - or to the next core in the group (group is always contained within a NUMA node).
You can, however, absolutely forbid Windows scheduler from passing the thread to another NUMA node under any circumstances by simply getting the said NUMA node affinity mask (GetNumaNodeProcessorMask(Ex)) and setting this affinity as a thread affinity. This + setting the "ideal" processor still gives Windows scheduler some headroom to move the thread to another core if it is found to be better in a given moment, but it will not even attempt to cross the NUMA boundary in any case whatsoever.
lmcd - Monday, January 7, 2013 - link
While I haven't personally researched them, there are tons of other schedulers that have been written for Linux and I'm certain *at least* one of them is more fitting to this line of work. I've heard of alternatives like BFS and the Linux kernel is so widely used I'm sure there's a gem out there for this application.toyotabedzrock - Saturday, January 5, 2013 - link
Have you ever tried the Intel Math Kernel Library? It might speed up some of the equations. It also hands off work to the Intel MIC card if it thinks it will speed it up.http://software.intel.com/en-us/intel-mkl/
KAlmquist - Saturday, January 5, 2013 - link
The GA-7PESH1 motherboard is $855, and the CPU's are $2020 each, which adds up to $4895. On tasks which don't parallelize well, you can get similar performance from the i7-3770K, which costs an order of magnitude less. (Prices: i7-3770K $320, ASRock Z77 Extreme6 motherboard $152, total from motherboard and CPU $472.) On tasks which parallelize well enough that they can be run on a GPU, the system with the GA-7PESH1 will beat the i7-3770K, but will be crushed by a midrange GPU. So the price/performance of this system is pretty bad unless you throw just the right workload at it.The motherboard price from super-laptop-parts dot com, and the other prices are from a major online retailer that I won't name in order to get around the spam filter.
Death666Angel - Saturday, January 5, 2013 - link
So, your 3770K has ECC memory or VT-D, TXT etc.?