Plextor Updates The Firmware on M5 Pro: Promises Increased Performance, We Test It
by Kristian Vättö on December 10, 2012 2:30 PM ESTPerformance Consistency
In our Intel SSD DC S3700 review we introduced a new method of characterizing performance: looking at the latency of individual operations over time. The S3700 promised a level of performance consistency that was unmatched in the industry, and as a result needed some additional testing to show that. The reason we don't have consistent IO latency with SSDs is because inevitably all controllers have to do some amount of defragmentation or garbage collection in order to continue operating at high speeds. When and how an SSD decides to run its defrag and cleanup routines directly impacts the user experience. Frequent (borderline aggressive) cleanup generally results in more stable performance, while delaying that can result in higher peak performance at the expense of much lower worst case performance. The graphs below tell us a lot about the architecture of these SSDs and how they handle internal defragmentation.
To generate the data below I took a freshly secure erased SSD and filled it with sequential data. This ensures that all user accessible LBAs have data associated with them. Next I kicked off a 4KB random write workload at a queue depth of 32 using incompressible data. I ran the test for just over half an hour, no where near what we run our steady state tests for but enough to give me a good look at drive behavior once all spare area filled up.
I recorded instantaneous IOPS every second for the duration of the test. I then plotted IOPS vs. time and generated the scatter plots below. Each set of graphs features the same scale. The first two sets use a log scale for easy comparison, while the last set of graphs uses a linear scale that tops out at 40K IOPS for better visualization of differences between drives.
The first set of graphs shows the performance data over the entire 2000 second test period. In these charts you'll notice an early period of very high performance followed by a sharp dropoff. What you're seeing in that case is the drive allocating new blocks from its spare area, then eventually using up all free blocks and having to perform a read-modify-write for all subsequent writes (write amplification goes up, performance goes down).
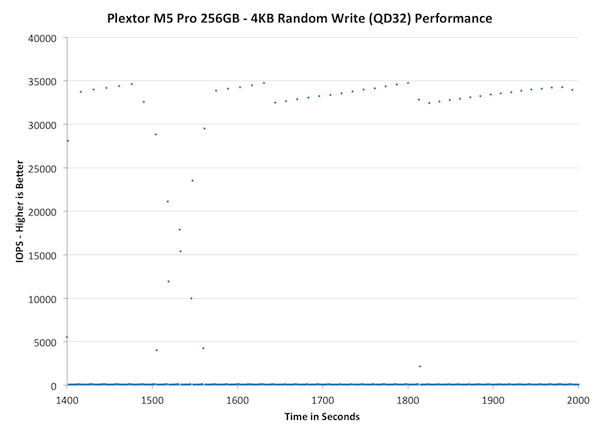
The second set of graphs zooms in to the beginning of steady state operation for the drive (t=1400s). The third set also looks at the beginning of steady state operation but on a linear performance scale. Click the buttons below each graph to switch source data.
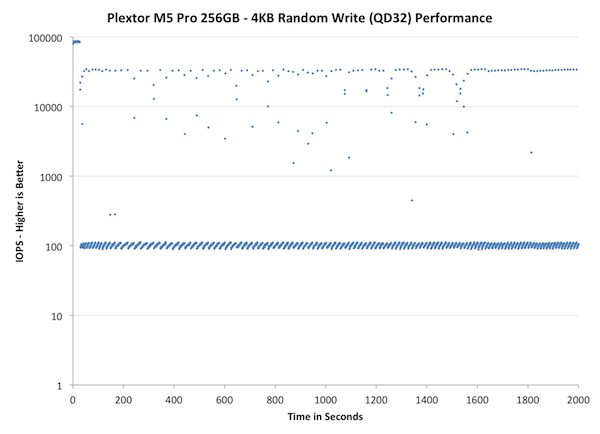
Wow, that's bad. While we haven't run the IO consistency test on all the SSDs we have in our labs, the M5 Pro is definitely the worst one we have tested so far. In less than a minute the M5 Pro's performance drops below 100, which at 4KB transfer size is equal to 0.4MB/s. What makes it worse is that the drops are not sporadic but in fact most of the IOs are in the magnitude of 100 IOPS. There are singular peak transfers that happen at 30-40K IOPS but the drive consistently performs much worse.
Even bigger issue is that over-provisioning the drive more doesn't bring any relief. As we discovered in our performance consistency article, giving the controller more space for OP usually made the performance much more consistent, but unfortunately this doesn't apply to the M5 Pro. It does help a bit as it takes longer for the drive to enter steady-state and there are more IOs happening in the ~40K IOPS range, but the fact is that most IO are still handicapped to 100 IOPS.
The next set of charts look at the steady state (for most drives) portion of the curve. Here we'll get some better visibility into how everyone will perform over the long run.
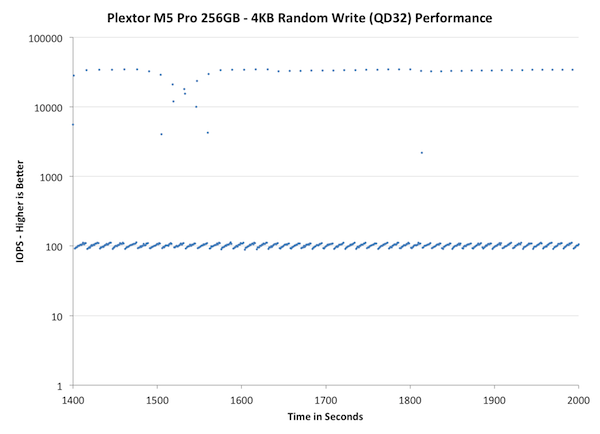
Concentrating on the final part of the test doesn't really bring anything new because as we saw in the first graph already, the M5 Pro reaches steady-state very quickly and the performance stays about the same throughout the test. The peaks are actually high compared to other SSDs but having one IO transfer at 3-5x the speed every now and then won't help if over 90% of the transfers are significantly slower.








46 Comments
View All Comments
lunadesign - Tuesday, December 11, 2012 - link
Understood, if my server's workload were to be relatively heavy. But do you really think that my server's workload (based on an admittedly rough description above) is going to get into these sorts of problematic situations?'nar - Tuesday, December 11, 2012 - link
I disagree. RAID 5 stripes, as does RAID 0, so they need to be synchronized(hard drives had to spin in-sync.) But RAID 1 uses the drive that answers first, as they have the same data. RAID 10 is a bit of both I suppose, but I also don't agree that you think that the lack of TRIM forces the drive into a low speed state in the first place.Doesn't TRIM just tell the drive what is safe to delete? Unless the drive is near full, why would that affect its' speed? TRIM was essential 2-3 years ago, but after SF drives GC got much better. I don't even think TRIM matters on consumer drives now.
For the most part I don't think these "steady state" tests even matter on consumer drives(or servers as lunadesign has). Sure, they are nice tests and have useful data, but it lacks real world data. The name "steady state" is misleading, to me anyway. It will not be a steady state in my computer as that is not my usage pattern. Why not test the IOPS during standard benchmark runs? Even with 8-10 VM's his server will be idle most of the time. Of course, if all of those VM's are compiling software all day, then that is different, but that's not what VM's are setup for anyway.
JellyRoll - Tuesday, December 11, 2012 - link
GC still does not handle deleted data as efficiently as TRIM. There is still a huge need for TRIM.We can see the affects of using this SSD for something other than its intended purpose outside of a TRIM environment. There is a large distribution of writes that are returning sub-par performance in this environment. The array (striped across RAID 1) will suffer low performance, constrained to the speed of the lowest I/O.
There are SSDs designed for this type of use specifically, hence why they have the distinction between enterprise and consumer storage.
cdillon - Tuesday, December 11, 2012 - link
Re: 'nar "RAID 5 stripes, as does RAID 0, so they need to be synchronized(hard drives had to spin in-sync.)"Only RAID 3 required spindle-synced drives for performance reasons. No other RAID level requires that. Not only is spindle-sync completely irrelevant for SSDs, hard drives haven't been made with spindle-sync support for a very long time. Any "synchronization" in a modern RAID array has to do with the data being committed to stable storage. A full RAID 4/5/6 stripe should be written and acknowledged by the drives before the next stripe is written to prevent the data and parity blocks from getting out of sync. This is NOT a consideration for RAID 0 because there is no "stripe consistency" to be had due to the lack of a parity block.
Re: JellyRoll "The RAID is only as fast as the slowest member"
It is not quite so simple in most cases. It is only that simple for a single mirror set (RAID 1) performing writes. When you start talking about other RAID types, the effect of a single slow drive depends greatly on both the RAID setup and the workload. For example, high-QD small-block random read workloads would be the least affected by a slow drive in an array, regardless of the RAID type. In that case you should achieve random I/O performance that approaches the sum of all non-dedicated-parity drives in the array.
JellyRoll - Tuesday, December 11, 2012 - link
i agree, but i was speaking specifically to writes.bogdan_kr - Monday, March 4, 2013 - link
1.03 firmware has been released for Plextor M5 Pro series. Is there a chance for performance consistency check for this new firmware?