Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTCPU Architecture Improvements: Background
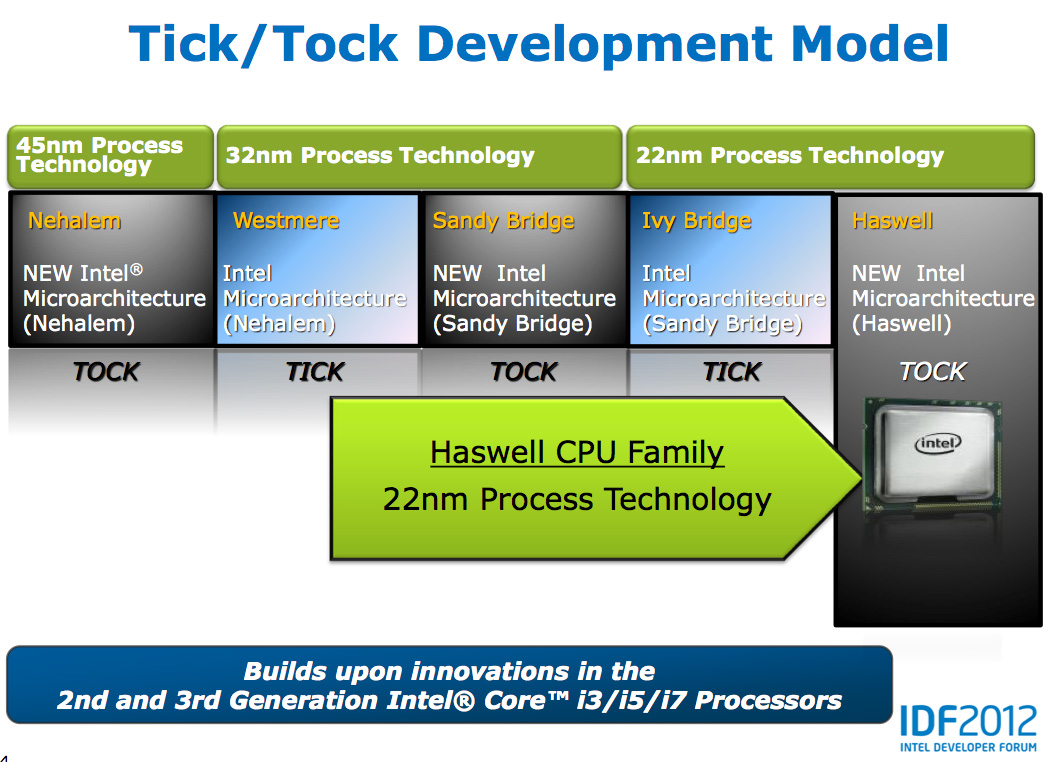
Despite all of this platform discussion, we must not forget that Haswell is the fourth tock since Intel instituted its tick-tock cadence. If you're not familiar with the terminology by now a tock is a "new" microprocessor architecture on an existing manufacturing process. In this case we're talking about Intel's 22nm 3D transistors, that first debuted with Ivy Bridge. Although Haswell is clearly SoC focused, the designs we're talking about today all use Intel's 22nm CPU process - not the 22nm SoC process that has yet to debut for Atom. It's important to not give Intel too much credit on the manufacturing front. While it has a full node advantage over the competition in the PC space, it's currently only shipping a 32nm low power SoC process. Intel may still have a more power efficient process at 32nm than its other competitors in the SoC space, but the full node advantage simply doesn't exist there yet.
Although Haswell is labeled as a new micro-architecture, it borrows heavily from those that came before it. Without going into the full details on how CPUs work I feel like we need a bit of a recap to really appreciate the changes Intel made to Haswell.
At a high level the goal of a CPU is to grab instructions from memory and execute those instructions. All of the tricks and improvements we see from one generation to the next just help to accomplish that goal faster.
The assembly line analogy for a pipelined microprocessor is over used but that's because it is quite accurate. Rather than seeing one instruction worked on at a time, modern processors feature an assembly line of steps that breaks up the grab/execute process to allow for higher throughput.
The basic pipeline is as follows: fetch, decode, execute, commit to memory. You first fetch the next instruction from memory (there's a counter and pointer that tells the CPU where to find the next instruction). You then decode that instruction into an internally understood format (this is key to enabling backwards compatibility). Next you execute the instruction (this stage, like most here, is split up into fetching data needed by the instruction among other things). Finally you commit the results of that instruction to memory and start the process over again.
Modern CPU pipelines feature many more stages than what I've outlined here. Conroe featured a 14 stage integer pipeline, Nehalem increased that to 16 stages, while Sandy Bridge saw a shift to a 14 - 19 stage pipeline (depending on hit/miss in the decoded uop cache).
The front end is responsible for fetching and decoding instructions, while the back end deals with executing them. The division between the two halves of the CPU pipeline also separates the part of the pipeline that must execute in order from the part that can execute out of order. Instructions have to be fetched and completed in program order (can't click Print until you click File first), but they can be executed in any order possible so long as the result is correct.
Why would you want to execute instructions out of order? It turns out that many instructions are either dependent on one another (e.g. C=A+B followed by E=C+D) or they need data that's not immediately available and has to be fetched from main memory (a process that can take hundreds of cycles, or an eternity in the eyes of the processor). Being able to reorder instructions before they're executed allows the processor to keep doing work rather than just sitting around waiting.
Sidebar on Performance Modeling
Microprocessor design is one giant balancing act. You model application performance and build the best architecture you can in a given die area for those applications. Tradeoffs are inevitably made as designers are bound by power, area and schedule constraints. You do the best you can this generation and try to get the low hanging fruit next time.
Performance modeling includes current applications of value, future algorithms that you expect to matter when the chip ships as well as insight from key software developers (if Apple and Microsoft tell you that they'll be doing a lot of realistic fur rendering in 4 years, you better make sure your chip is good at what they plan on doing). Obviously you can't predict everything that will happen, so you continue to model and test as new applications and workloads emerge. You feed that data back into the design loop and it continues to influence architectures down the road.
During all of this modeling, even once a design is done, you begin to notice bottlenecks in your design in various workloads. Perhaps you notice that your L1 cache is too small for some newer workloads, or that for a bunch of popular games you're seeing a memory access pattern that your prefetchers don't do a good job of predicting. More fundamentally, maybe you notice that you're decode bound more often than you'd like - or alternatively that you need more integer ALUs or FP hardware. You take this data and feed it back to the team(s) working on future architectures.
The folks working on future architectures then prioritize the wish list and work on including what they can.








245 Comments
View All Comments
Magik_Breezy - Sunday, October 14, 2012 - link
Anything delivers "solid performance" on Facebook & iWorkWhy pay $2,000 for that?
random2 - Friday, October 5, 2012 - link
I agree. admittedly I am not an apple fan and view them as people who have undergone a degree of brainwashing compounded by the need for some to keep up with the Jone's. A certain degree of mind control must be necessary to stick with a company that has had some questionable business practices as far as customer relations, dealing with product issues and denying said issues, not to mention the whole hypocritical stance by apple in regards to copyright infringement has also left a bad taste in my mouth.hasseb64 - Saturday, October 6, 2012 - link
Disagree, not that much new from already published IDF reports almost 1 month ago. What is intresting is the claimed 40 EU GT3, other sources say lower amounts.JKflipflop98 - Saturday, October 6, 2012 - link
I totally agree. It's articles like this that have kept me coming back for years. Keep up the good work Anand!tipoo - Sunday, October 7, 2012 - link
"You can expect CPU performance to increase by around 5 - 15% at the same clock speed as Ivy Bridge. "That seems terribly disappointing for a tock, even IVB as a Tick managed 10% in most cases.
medi01 - Tuesday, October 9, 2012 - link
One can't be biased !@# !@#@ and a good journalist at the same time.One needs to be blind not to see how glass is always half empty for AMD, and half full for nVidia/Intel. F**!@#'s were shameless enough, to test 45W APU with 1000W PSU and such crap is all over the place.
Paulman - Friday, October 5, 2012 - link
As I was reading this article, about part way into the low platform power sections I suddenly had this thought: "Oh man, AMD is gonna die...!"I don't know if that's true for the entire microprocessor side of AMD, since they look like they're already starting to transition out of the desktop space, but I don't know if they're going to stand much of a chance if they're planning on entering the same TDP range as Haswell.
Do you think there's a chance AMD will start focussing on designing ARM ISA cores? Or will expanding on their x86 Bobcat-type cores be enough for them?
sean.crees - Friday, October 5, 2012 - link
I also worry about AMD. AMD has been 1-2 steps behind Intel for a while now, and now it seems Intel is at least 1 or 2 steps behind ARM and the future. Is that going to mean AMD is just too far behind to stay relevant now? If nothing else, i suppose AMD can fall back on graphic cards with it's ATI acquisition.Da W - Friday, October 5, 2012 - link
If Haswell keeps x86 relevant in the tablet space and thus Windows 8 has the upper edge over Windows RT and Windows tablets can grab +-50% market share from the iPad, then it can be good for AMD, provided they survive that long.RedemptionAD - Friday, October 5, 2012 - link
If AMD can create a team to focus on increasing IPC with a goal to one up Intel and have the ATI graphics people keep doing what they do with a time goal of say 2 years, (Note: Portables/Notebooks/Desktops should all be x64 by then), then I think that AMD will be able to return to their Athlon 64 glory days or better.