Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTThe Haswell Front End
Conroe was a very wide machine. It brought us the first 4-wide front end of any x86 micro-architecture, meaning it could fetch and decode up to 4 instructions in parallel. We've seen improvements to the front end since Conroe, but the overall machine width hasn't changed - even with Haswell.
Haswell leaves the overall pipeline untouched. It's still the same 14 - 19 stage pipeline that we saw with Sandy Bridge depending on whether or not the instruction is found in the uop cache (which happens around 80% of the time). L1/L2 cache latencies are unchanged as well. Since Nehalem, Intel's Core micro-architectures have supported execution of two instruction threads per core to improve execution hardware utilization. Haswell also supports 2-way SMT/Hyper Threading.
The front end remains 4-wide, although Haswell features a better branch predictor and hardware prefetcher so we'll see better efficiency. Since the pipeline depth hasn't increased but overall branch prediction accuracy is up we'll see a positive impact on overall IPC (instructions executed per clock). Haswell is also more aggressive on the speculative memory access side.
The image below is a crude representation I put together of the Haswell front end compared to the two previous tocks. If you click the buttons below you'll toggle between Haswell, Sandy Bridge and Nehalem diagrams, with major changes highlighted.
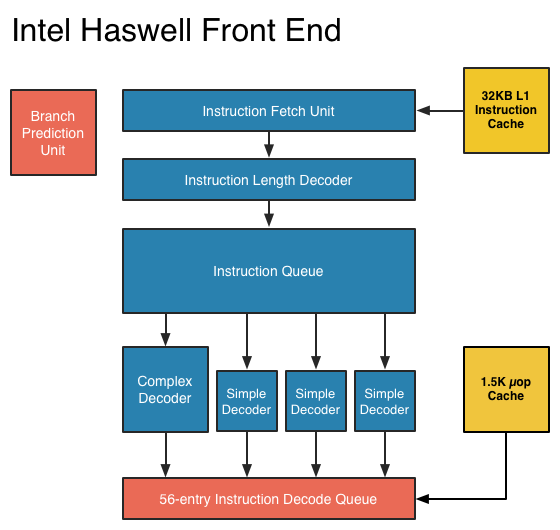
In short, there aren't many major, high-level changes to see here. Instructions are fetched at the top, sent through a bunch of steps before getting to the decoders where they're converted from macro-ops (x86 instructions) to an internally understood format known to Intel as micro-ops (or µops). The instruction fetcher can grab 4 - 5 x86 instructions at a time, and the decoders can output up to 4 micro-ops per clock.
Sandy Bridge introduced the 1.5K µop cache that caches decoded micro-ops. When future instruction fetch requests are made, if the instructions are contained within the µop cache everything north of the cache is powered down and the instructions are serviced from the µop cache. The decode stages are very power hungry so being able to skip them is a boon to power efficiency. There are also performance benefits as well. A hit in the µop cache reduces the effective integer pipeline to 14 stages, the same length as it was in Conroe in 2006. Haswell retains all of these benefits. Even the µop cache size remains unchanged at 1.5K micro-ops (approximately 6KB in size).
Although it's noted above as a new/changed block, the updated instruction decode queue (aka allocation queue) was actually one of the changes made to improve single threaded performance in Ivy Bridge.
The instruction decode queue (where instructions go after they've been decoded) is no longer statically partitioned between the two threads that each core can service.
The big changes in Haswell are at the back end of the pipeline, in the execution engine.








245 Comments
View All Comments
Spunjji - Thursday, October 18, 2012 - link
Fuckwit.nirmalv - Sunday, October 7, 2012 - link
Anandtech being a hardware site,its more inclined to keenly flow hardware devices with new architecture and innovations. iphone brings in1, A new A7 chip design and a novel 3 core graphics core
2, A new 3 microphone parabolic sound receiving design(which likely will become the new standard)
3, A new sim tray design(which will also likely become the new standard)
4, New sony BSI stacked sensor (the 13 mpx version will likely be the rage next year).
5, The first time that we have a 32 nm LTE chip which will give all day usage.
6, New thinner screen with incorporated touch panel and 100 % RGB
I am not sure about samsung but can anyone enlighten me about S3's technical achievements?
nirmalv - Sunday, October 7, 2012 - link
Sorry make that a 28 nm LTE basebandcenthar - Sunday, October 7, 2012 - link
99.998% of iPhone users just don't care about that. Really they don't.Geeks like me who do, are too damn smart to sell our souls to the such a god damned, locked down and closed system to even bother to care.
Magik_Breezy - Sunday, October 14, 2012 - link
2nd thatSpunjji - Thursday, October 18, 2012 - link
3rdCaptainDoug - Tuesday, October 23, 2012 - link
4th,solipsism - Tuesday, October 9, 2012 - link
Of course a company that releases one device per product category per year as well as one with the greatest mindshare is going to have more articles.But what happens when you add up all Samsung phones against all Apple phones in a given year?
What happens when you don't count the small blogs that only detail a small aspect of a secretive product but count the total words to get a better feel for the effort spent per company's market segment?
I bet you'll find that AT spends a lot more time covering Samsung's phones than Apple's.
Spunjji - Thursday, October 18, 2012 - link
This. I generally trust their editorial, but the focus on Apple prevails. One just has to read accordingly.Kepe - Friday, October 5, 2012 - link
Also look at any other Apple product review. They are all ridiculously in-depth with analysis about almost every single component in the product. Macbook Pro with Retina Display got 18 pages, the 3rd gen iPad got 21 pages. Don't get me wrong, I like a proper review with everything analyzed, but it's only the Apple products that get these huge reviews. But compared to those massive Apple reviews, it's like all other products are just glanced over in a hurry. The new Razer Blade got 9 pages. Asus Transformer Pad Infinity got 8 pages.