Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTThe Haswell Front End
Conroe was a very wide machine. It brought us the first 4-wide front end of any x86 micro-architecture, meaning it could fetch and decode up to 4 instructions in parallel. We've seen improvements to the front end since Conroe, but the overall machine width hasn't changed - even with Haswell.
Haswell leaves the overall pipeline untouched. It's still the same 14 - 19 stage pipeline that we saw with Sandy Bridge depending on whether or not the instruction is found in the uop cache (which happens around 80% of the time). L1/L2 cache latencies are unchanged as well. Since Nehalem, Intel's Core micro-architectures have supported execution of two instruction threads per core to improve execution hardware utilization. Haswell also supports 2-way SMT/Hyper Threading.
The front end remains 4-wide, although Haswell features a better branch predictor and hardware prefetcher so we'll see better efficiency. Since the pipeline depth hasn't increased but overall branch prediction accuracy is up we'll see a positive impact on overall IPC (instructions executed per clock). Haswell is also more aggressive on the speculative memory access side.
The image below is a crude representation I put together of the Haswell front end compared to the two previous tocks. If you click the buttons below you'll toggle between Haswell, Sandy Bridge and Nehalem diagrams, with major changes highlighted.
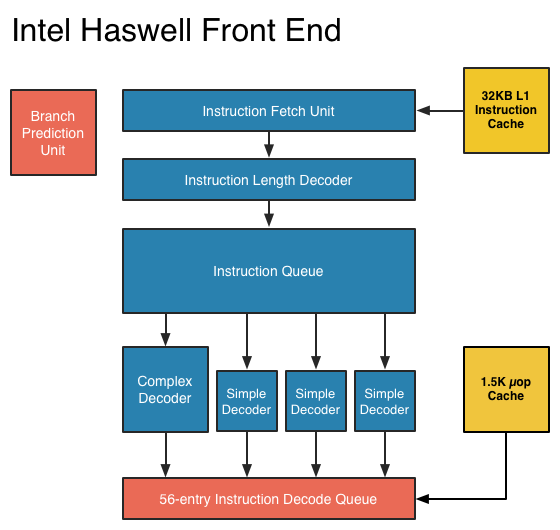
In short, there aren't many major, high-level changes to see here. Instructions are fetched at the top, sent through a bunch of steps before getting to the decoders where they're converted from macro-ops (x86 instructions) to an internally understood format known to Intel as micro-ops (or µops). The instruction fetcher can grab 4 - 5 x86 instructions at a time, and the decoders can output up to 4 micro-ops per clock.
Sandy Bridge introduced the 1.5K µop cache that caches decoded micro-ops. When future instruction fetch requests are made, if the instructions are contained within the µop cache everything north of the cache is powered down and the instructions are serviced from the µop cache. The decode stages are very power hungry so being able to skip them is a boon to power efficiency. There are also performance benefits as well. A hit in the µop cache reduces the effective integer pipeline to 14 stages, the same length as it was in Conroe in 2006. Haswell retains all of these benefits. Even the µop cache size remains unchanged at 1.5K micro-ops (approximately 6KB in size).
Although it's noted above as a new/changed block, the updated instruction decode queue (aka allocation queue) was actually one of the changes made to improve single threaded performance in Ivy Bridge.
The instruction decode queue (where instructions go after they've been decoded) is no longer statically partitioned between the two threads that each core can service.
The big changes in Haswell are at the back end of the pipeline, in the execution engine.








245 Comments
View All Comments
jigglywiggly - Friday, October 5, 2012 - link
wish the onboard gpu was better =/woula been nice for a laptop
tipoo - Friday, October 5, 2012 - link
2x the HD4000 is pretty decent for integrated. I wonder if that's 2x with or without the eDRAM cache though.ElvenLemming - Friday, October 5, 2012 - link
It's been known for a while that Haswell was only going to have a moderate improvement in the iGPU and the next big overhaul would be coming with Broadwell.csroc - Friday, October 5, 2012 - link
This is impressive, it might convince me it's time for a new laptop. On the other hand I also need to build a new desktop workstation and Haswell so far hasn't impressed me in that space.mayankleoboy1 - Friday, October 5, 2012 - link
Is Intel sacrificing Desktop CPU performance to make an architecture that is geared to the mobile space ?csroc - Friday, October 5, 2012 - link
It feels that way to me. Mobile performance seems to be their big concern now, that and improving the GPU. Two things I generally can't be bothered to care about when I'm looking to build a new workstation. I suspect I'll build an Ivy Bridge system because I could use it now and see nothing worth getting excited about.dishayu - Friday, October 5, 2012 - link
I fully share your sentiment. TO be very crude, i don't mind at all, paying for power imporvements, because it will pay back for itself in the long term (by consuming less power AND needing lesser cooling). But i DO mind very much, paying for 40 EUs of GPU on my desktop build which i will not use even for a second. Me, you and many others do not care about on-die graphics and Intel should realize that.I don't know why intel can't offer us both GPU and GPU-less options, the way they did with motherboards back in the days? P965 had no graphics, G965 did. Pretty sure it's technologically not an issue.
DanNeely - Friday, October 5, 2012 - link
If it makes you feel any better; reports elsewhere are that GT3 will be mobile only, because desktops don't have the power/size constraints driving the need for premium IGPs.Intel's not IGP CPUs are the E series parts; unfortunately they've failed to execute on the enthusiast side in terms of price/launch date leaving them as mostly server parts.
There just aren't enough of us to justify Intel adding another die design for their mass market socket that doesn't have an IGP at all instead of just letting us turn it off and use the extra TDP headroom for more time at boost speeds.
Omoronovo - Friday, October 5, 2012 - link
I'm somewhat in disagreement with you both.Whilst I share a concern that Intel is no longer focusing on raw performance improvements in the purely desktop space, they are still delivering incremental updates to the architecture that will benefit all current software (even if only marginally). However, processor performance has been reaching more and more diminishing returns in recent years, namely that software is simply not able to take advantage of multiple cores and improved performance because of (primarily) locks and complexity in creating multi-threaded applications.
As such, Intel has been focusing on that area - to make it easier for software and software developers to take advantage of the performance that exists *now* rather than brute forcing the issue by simply delivering more raw performance (much of which will be wasted/remain idle due to current software constraints).
With this, Intel has been able to focus on keeping performance high whilst subsequently dropping power usage substantially - the fact the iGPU is oftentimes not being used in a desktop environment does not invalidate it's utility - QuickSync is a prime example of where the gpu can accelerate certain types of processing, and if more software takes advantage of this we should see even more gains in future.
For the last 6 years or so, Intel has shown that it knows what demands will be placed on future computing hardware, and they seem convinced that this is the way to go. We might not be there yet, but technologies like C++AMP, OpenCL and such make me hopeful that this will change in a few years.
cmrx64 - Friday, October 5, 2012 - link
I solved this problem by buying an Ivy Bridge Xeon (specifically, an E3-1230v2). No GPU, lower power consumption than the equivalent i5/i7, has hyperthreading, performs really good, and a lot cheaper than an i7.If you don't care about the GPU, look to the Xeon line.