Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTDecoupled L3 Cache
With Nehalem Intel introduced an on-die L3 cache behind a smaller, low latency private L2 cache. At the time, Intel maintained two separate clock domains for the CPU (core + uncore) and a third for what was, at the time, an off-die integrated graphics core. The core clock referred to the CPU cores, while the uncore clock controlled the speed of the L3 cache. Intel believed that its L3 cache wasn't incredibly latency sensitive and could run at a lower frequency and burn less power. Core CPU performance typically mattered more to most workloads than L3 cache performance, so Intel was ok with the tradeoff.
In Sandy Bridge, Intel revised its beliefs and moved to a single clock domain for the core and uncore, while keeping a separate clock for the now on-die processor graphics core. Intel now felt that race to sleep was a better philosophy for dealing with the L3 cache and it would rather keep things simple by running everything at the same frequency. Obviously there are performance benefits, but there was one major downside: with the CPU cores and L3 cache running in lockstep, there was concern over what would happen if the GPU ever needed to access the L3 cache while the CPU (and thus L3 cache) was in a low frequency state. The options were either to force the CPU and L3 cache into a higher frequency state together, or to keep the L3 cache at a low frequency even when it was in demand to prevent waking up the CPU cores. Ivy Bridge saw the addition of a small graphics L3 cache to mitigate this situation, but ultimately giving the on-die GPU independent access to the big, primary L3 cache without worrying about power concerns was a big issue for the design team.
When it came time to define Haswell, the engineers once again went to Nehalem's three clock domains. Ronak (Nehalem & Haswell architect, insanely smart guy) tells me that the switching between designs is simply a product of the team learning more about the architecture and understanding the best balance. I think it tells me that these guys are still human and don't always have the right answer for the long term without some trial and error.
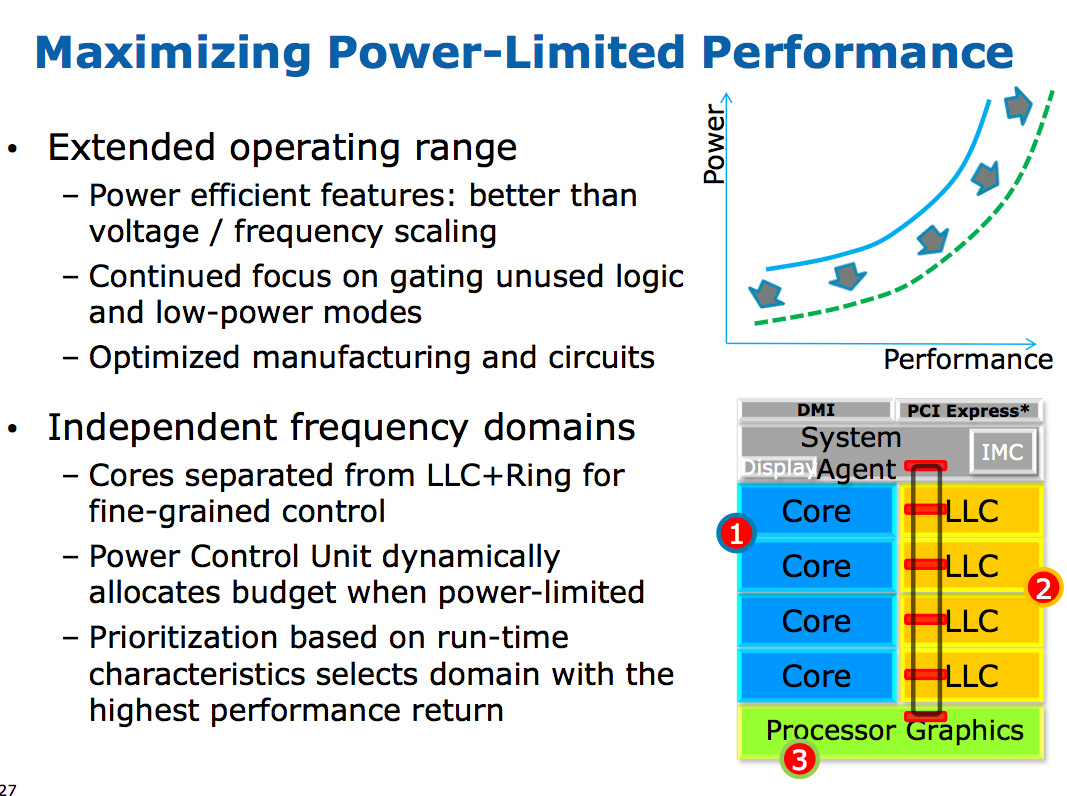
The three clock domains in Haswell are roughly the same as what they were in Nehalem, they just all happen to be on the same die. The CPU cores all run at the same frequency, the on-die GPU runs at a separate frequency and now the L3 + ring bus are in their own independent frequency domain.
Now that CPU requests to L3 cache have to cross a frequency boundary there will be a latency impact to L3 cache accesses. Sandy Bridge had an amazingly fast L3 cache, Haswell's L3 accesses will be slower.
The benefit is obviously power. If the GPU needs to fire up the ring bus to give/get data, it no longer has to drive up the CPU core frequency as well. Furthermore, Haswell's power control unit can dynamically allocate budget between all areas of the chip when power limited.
Although L3 latency is up in Haswell, there's more access bandwidth offered to each slice of the L3 cache. There are now dedicated pipes for data and non-data accesses to the last level cache.
Haswell's memory controller is also improved, with better write throughput to DRAM. Intel has been quietly telling the memory makers to push for even higher DDR3 frequencies in anticipation of Haswell.








245 Comments
View All Comments
kukreknecmi - Friday, October 5, 2012 - link
I hope i know it right. L3 on SB/IB doest used by GPU. L3 still servers as cache on system via memory controller. If GPU nneds to acess to memory, it sends request to memory controller. L3 is not directly accessable to GPU as a texture cache etc.On IB, they added a 512k cache which is seperated to half, 256k of it is used as texture system as backfeeding and other 256k half is used for other things.Article implies that L3 cache on IB is used as a texture buffer like on ordinary graphic cards. Only on Haswell L3 cache will be accessable and can be used as a some kind of GPU specific buffer.
Kevin G - Friday, October 5, 2012 - link
The confusing thing is that consumer Ivy Bridge parts have a L3 cache just for the GPU which is separate memory than the L3 cache that the CPU uses. The Ivy Bridge GPU's can use the CPU's L3 cache as the GPU's L4 cache to a degree.To confuse things further, the CPU side really has four levels of cache too. There is the small 1.5 KB micro-uop cache for instructions which comes before the 32 KB L1 instruction cache.
mayankleoboy1 - Friday, October 5, 2012 - link
From the article, its not very clear : Which platform (DT, Mobile, ultra mobile) will have the integrated voltage regulators/controllers ?Ryan Smith - Friday, October 5, 2012 - link
Ultra Mobile.Anand Lal Shimpi - Friday, October 5, 2012 - link
It's not clear how much of the VR circuitry gets integrated into Haswell or necessarily which parts will have it and which ones won't. Ultra mobile is a shoe in, but I've even heard of desktop parts getting it as well. We'll have to wait and see.DanNeely - Friday, October 5, 2012 - link
Rats. Reading the article I was hoping that Intel had decided to only bake the VRMs into their ultra-mobile parts. Better VRMs are an important factor in high end OCing; with desktop boards not cramped for space I really hope Intel keeps them off the package.Peanutsrevenge - Friday, October 5, 2012 - link
Seconded.However, I wonder whether the VRMs on high end mobos will still be an option, where the on package VRMs will simply extend the capabilities?
But given Intels recent distaste for overclocking, it wouldn't suprise me if we'll soon see CPUs completely locked from overclocking completely or only on E series, high profit chips.
Homeles - Saturday, October 6, 2012 - link
"However, I wonder whether the VRMs on high end mobos will still be an option, where the on package VRMs will simply extend the capabilities?"Bingo.
Homeles - Saturday, October 6, 2012 - link
Low end motherboards won't need them. High end overclocking boards will have them in addition to the ones on package.tuxRoller - Friday, October 5, 2012 - link
Using lvds reclocking you can reduce idle screen induced wakeups to 30 (ditto for the memory controller if the cpu supports self refresh for the sram ).eDP may allow even less.