The iPhone 5 Review
by Anand Lal Shimpi, Brian Klug & Vivek Gowri on October 16, 2012 11:33 AM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone 5
Apple's Swift: Pipeline Depth & Memory Latency
Section by Anand Shimpi
For the first time since the iPhone's introduction in 2007, Apple is shipping a smartphone with a CPU clock frequency greater than 1GHz. The Cortex A8 in the iPhone 3GS hit 600MHz, while the iPhone 4 took it to 800MHz. With the iPhone 4S, Apple chose to maintain the same 800MHz operating frequency as it moved to dual-Cortex A9s. Staying true to its namesake, Swift runs at a maximum frequency of 1.3GHz as implemented in the iPhone 5's A6 SoC. Note that it's quite likely the 4th generation iPad will implement an even higher clocked version (1.5GHz being an obvious target).
Clock speed alone doesn't tell us everything we need to know about performance. Deeper pipelines can easily boost clock speed but come with steep penalties for mispredicted branches. ARM's Cortex A8 featured a 13 stage pipeline, while the Cortex A9 moved down to only 8 stages while maintining similar clock speeds. Reducing pipeline depth without sacrificing clock speed contributed greatly to the Cortex A9's tangible increase in performance. The Cortex A15 moves to a fairly deep 15 stage pipeline, while Krait is a bit more conservative at 11 stages. Intel's Atom has the deepest pipeline (ironically enough) at 16 stages.
To find out where Swift falls in all of this I wrote two different codepaths. The first featured an easily predictable branch that should almost always be taken. The second codepath featured a fairly unpredictable branch. Branch predictors work by looking at branch history - branches with predictable history should be, well, easy to predict while the opposite is true for branches with a more varied past. This time I measured latency in clocks for the main code loop:
| Branch Prediction Code | ||||||
| Apple A3 (Cortex A8 @ 600MHz | Apple A5 (2 x Cortex A9 @ 800MHz | Apple A6 (2 x Swift @ 1300MHz | ||||
| Easy Branch | 14 clocks | 9 clocks | 12 clocks | |||
| Hard Branch | 70 clocks | 48 clocks | 73 clocks | |||
The hard branch involves more compares and some division (I'm basically branching on odd vs. even values of an incremented variable) so the loop takes much longer to execute, but note the dramatic increase in cycle count between the Cortex A9 and Swift/Cortex A8. If I'm understanding this data correctly it looks like the mispredict penalty for Swift is around 50% longer than for ARM's Cortex A9, and very close to the Cortex A8. Based on this data I would peg Swift's pipeline depth at around 12 stages, very similar to Qualcomm's Krait and just shy of ARM's Cortex A8.
Note that despite the significant increase in pipeline depth Apple appears to have been able to keep IPC, at worst, constant (remember back to our scaled Geekbench scores - Swift never lost to a 1.3GHz Cortex A9). The obvious explanation there is a significant improvement in branch prediction accuracy, which any good chip designer would focus on when increasing pipeline depth like this. Very good work on Apple's part.
The remaining aspect of Swift that we have yet to quantify is memory latency. From our iPhone 5 performance preview we already know there's a tremendous increase in memory bandwidth to the CPU cores, but as the external memory interface remains at 64-bits wide all of the changes must be internal to the cache and memory controllers. I went back to Nirdhar's iOS test vehicle and wrote some new code, this time to access a large data array whose size I could vary. I created an array of a finite size and added numbers stored in the array. I increased the array size and measured the relationship between array size and code latency. With enough data points I should get a good idea of cache and memory latency for Swift compared to Apple's implementation of the Cortex A8 and A9.
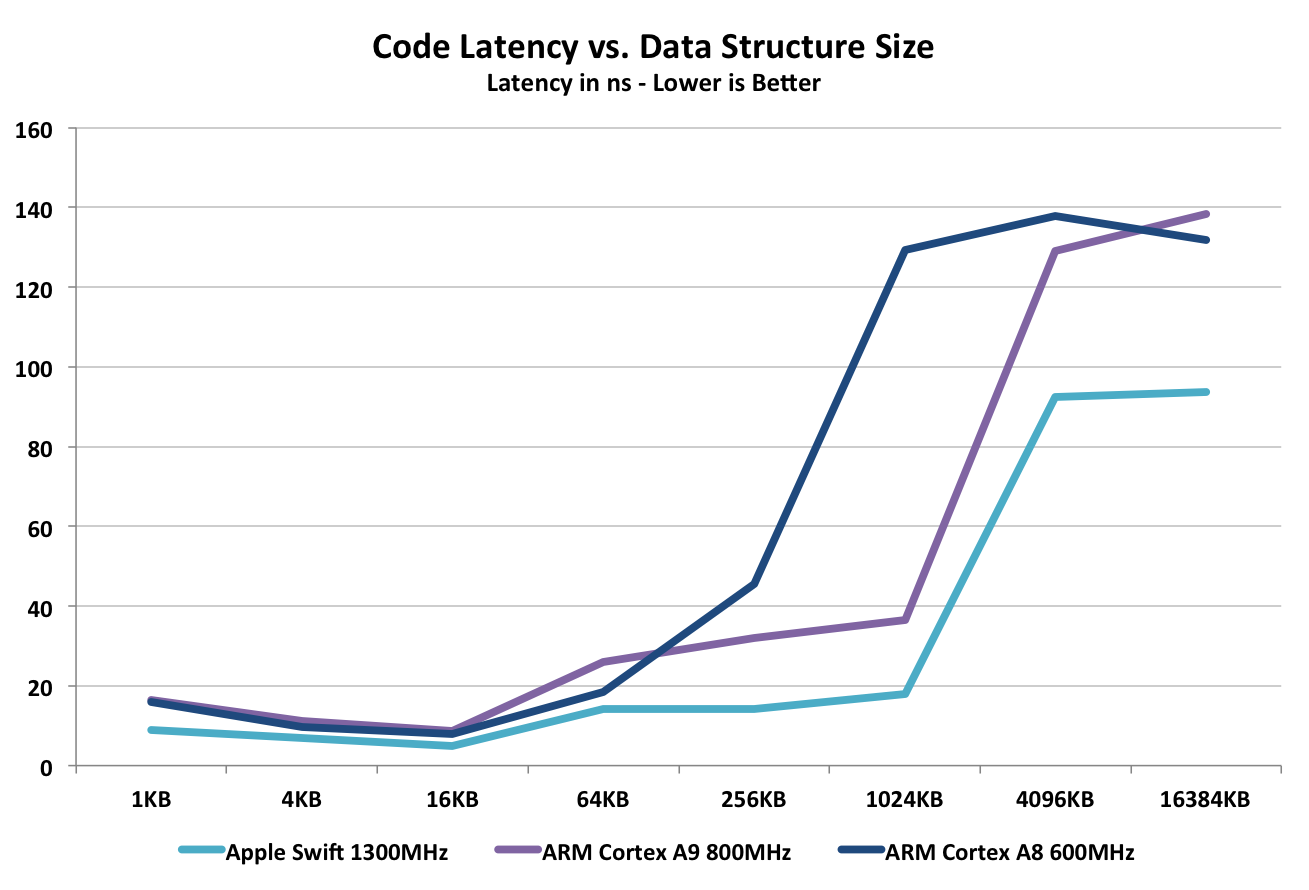
At relatively small data structure sizes Swift appears to be a bit quicker than the Cortex A8/A9, but there's near convergence around 4 - 16KB. Take a look at what happens once we grow beyond the 32KB L1 data cache of these chips. Swift manages around half the latency for running this code as the Cortex A9 (the Cortex A8 has a 256KB L2 cache so its latency shoots up much sooner). Even at very large array sizes Swift's latency is improved substantially. Note that this data is substantiated by all of the other iOS memory benchmarks we've seen. A quick look at Geekbench's memory and stream tests show huge improvements in bandwidth utilization:
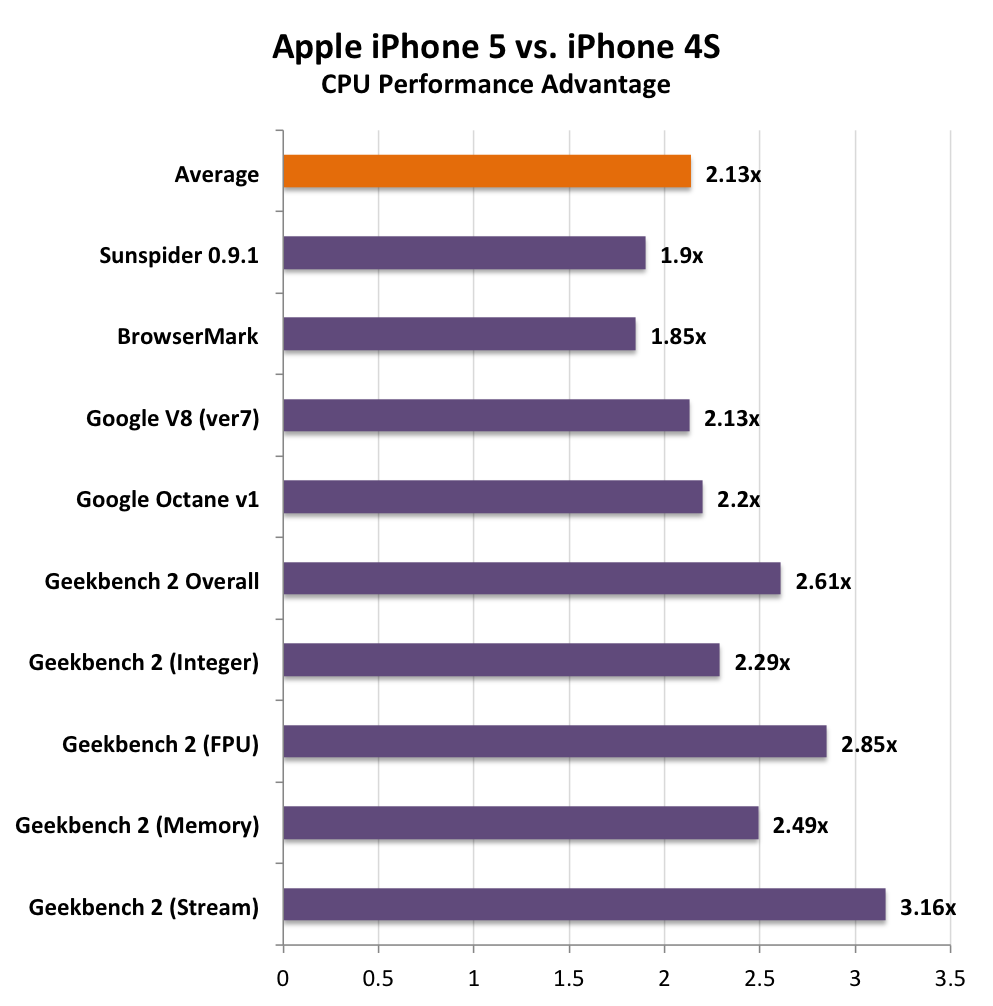
Couple the dedicated load/store port with a much lower latency memory subsystem and you get 2.5 - 3.2x the memory performance of the iPhone 4S. It's the changes to the memory subsystem that really enable Swift's performance.








276 Comments
View All Comments
medi01 - Wednesday, October 17, 2012 - link
Try to do it in a darker environment.If you still don't notice that AMOLED black is actually, cough, black and "iphone"'s black is actually gray, you probably should visit a doctor.
darwiniandude - Friday, October 19, 2012 - link
Who cares about black being 100% black when all the colour accuracy is terrible? The galaxy note looks like is has cellophane over the screen next to an iPhone, the white doesn't look white. You take a photo of a hill side and all the trees and grass is the same over saturated shade of green. It's because of this that I'd only consider the HTC one X excuse it has an accurate LCD. I've personally never found an Amoled screen so far I can put up with. Each to their own, if black is more important to you than the rest of the spectrum, then enjoy it.bpear96 - Thursday, October 18, 2012 - link
Well obiously, there PPI's are almost the same, because of the size difference.If you had a 4.8" 1136 x 640 display, next to a 4" 1136 x 640 the 4.8" would not look nearly as good as the 4" because it would have a lower PPI (pixels per inch) since the GS3 is larger it needs a higher res display to be on par with the 4" iphone 5 display.
bpear96 - Thursday, October 18, 2012 - link
type - obviously *star-affinity - Tuesday, October 23, 2012 - link
The difference (in my opinion) being that the Galaxy S III has over saturated colors which is quite bad.http://www.displaymate.com/Smartphone_ShootOut_2.h...
GabeA - Saturday, January 5, 2013 - link
Sorry, you're comparing a poor screen technology (PenTile subpel matrix) with a top-of-the-line LCD. The comparison is flawed because the effective resolution on text is only ~82% in either direction (something like 1050 x 590 on sharp, black text) due to the interpolated, non-RGB subpixels.A good comparison would absolutely involve the One X series by HTC. In fact, holding the SGS3 and the One X side by side on this page shows an obvious difference in text clarity in favor of the One X.
rocketbuddha - Tuesday, October 16, 2012 - link
Don't you know that every iPhone comes with the halo of the RDF (Reality Distortion Field) :DThus things that other things have been having for months/years in other models appear antiquated/vanish once iPhone comes near ;-)
doobydoo - Friday, October 19, 2012 - link
So having the fastest hardware in any smartphone ever, the iPhone 5 was late to the party?Or was it the fact that it's the thinnest that you're claiming they copied from Android. Or lightest, or thinnest, or shortest, or battery life.
I wonder when any Android phone (bar the Razr Maxx which lets face it is a brick) will catch up?
A5 - Tuesday, October 16, 2012 - link
So you want a Droid Razr HD Maxx, then?webmastir - Tuesday, October 16, 2012 - link
Yep. That should be the #1 choice at the moment.