The Plextor M3 (256GB) Review
by Kristian Vättö on April 5, 2012 3:05 AM ESTPerformance Over Time and TRIM
When Plextor sent the drive in for review, they emphazised one thing: a technology they call "True Speed". Supposedly, its job is to guarantee a high performance experience throughout the lifetime of the drive, and even when the drive is at a dirty state. As this technology is firmware related, we don't know how it differs from what others (e.g. Intel and Crucial) have done.
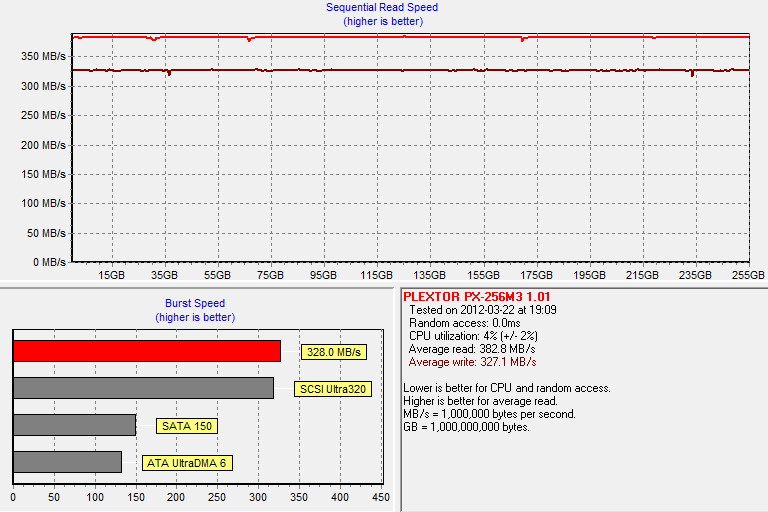
First, lets get the base performance by running HD Tach on a clean drive:
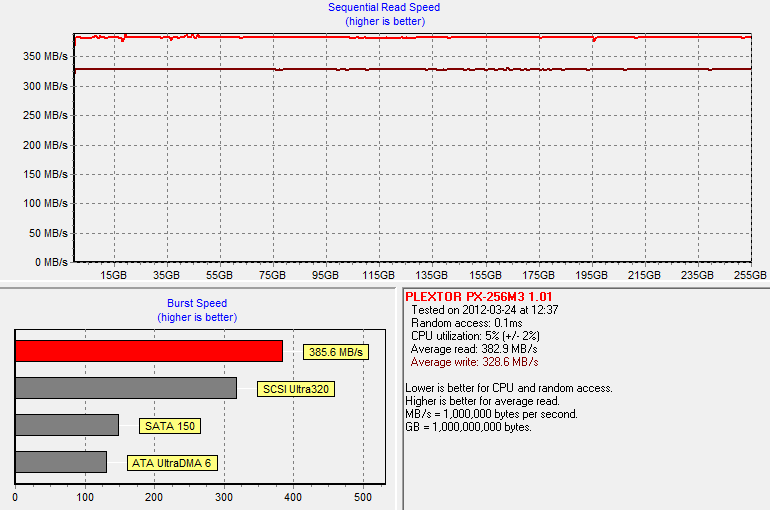
In a clean state, we get 383MB/s read speeds and 329MB/s write speeds. Next we ran the drive through our torture test, which consists of 20 minutes of 4KB random writes (QD=32, 100% LBA space) run on a full drive:
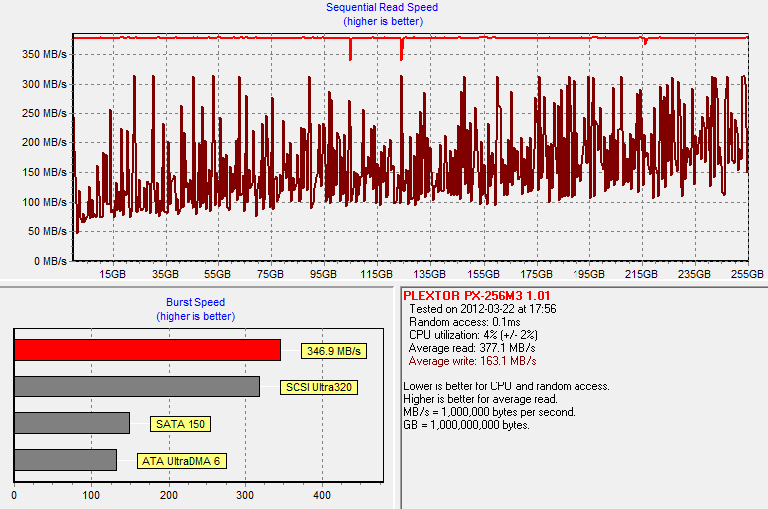
The M3 is still able to manage an average write speed of ~163MB/s. However, the write speed drops to as low as 50MB/s for the first LBAs, while the peak performance is still easily over 300MB/s. Plextor does noticeably better than Crucial in this regard as the performance of the m4 dropped to an average of 35MB/s. However, it should also be noted that the M3 had a higher write speed to begin with.
I wasn't ready to let Plextor go this easily. To see how the "True Speed" technology really works, I secure erased the drive, filled it with sequential data and then tripled the amount of 4KB random writes to 60 minutes:
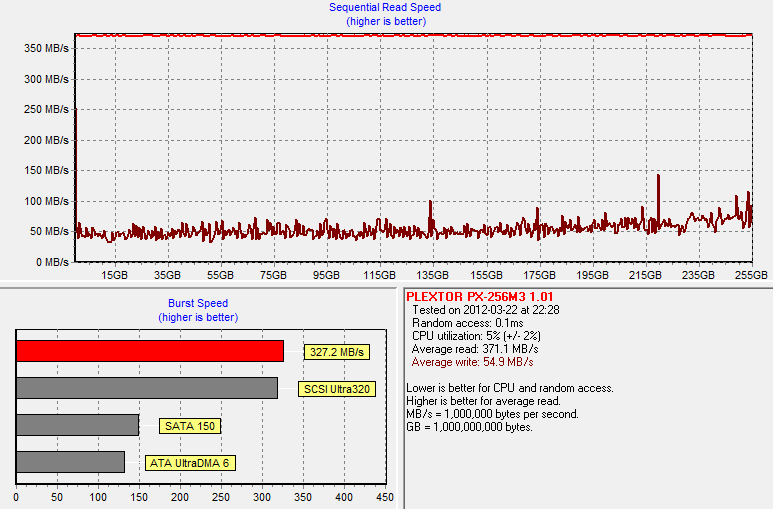
The amplitude of the graph is a lot smaller now and there are only two small peaks, compared to the previous graph with dozens of peaks. The performance drop is significant as we are looking at 50MB/s on average regardless of the LBA. At the lowest, the performance is 35-40MB/s. That's still better than the Crucial m4, however, even with three times the random data thrown at the M4.
Next I secure erased the drive, reran our 20 minute torture test and let the drive idle for 40 minutes:
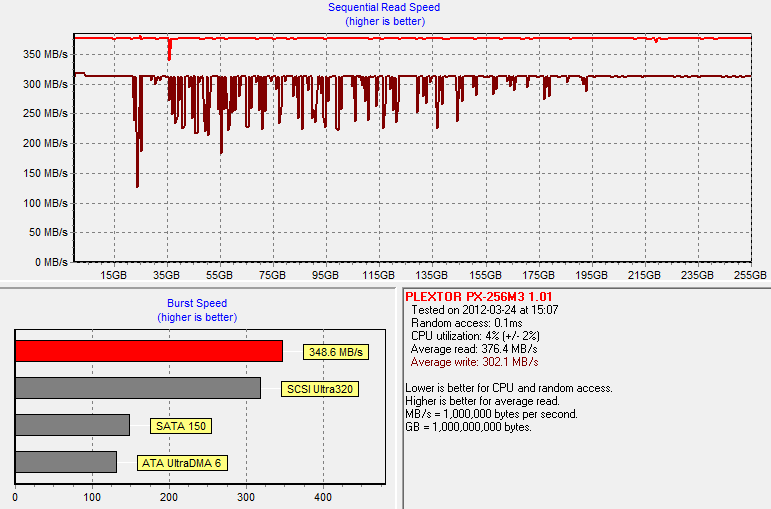
It does recover pretty well and we are looking at almost as new performance. There are a few negative peaks where the write speed drops to ~130MB/s, but on average the performance is only 25MB/s short of clean performance.
Finally I formatted the drive to see how it responds to the ATA TRIM command:
And the performance is back to brand new.
These graphs show us that if you are running an operating system with TRIM support (e.g. Windows 7), then there is absolutely no problem with the Plextor M3. If you are running an OS with no official TRIM support for the SSD (e.g. Mac OS X), then a SandForce based SSD will still be a better choice in this regard. However, what I would like to note is that our torture test reflects an extreme usage case.
Even if you are an enthusiast or professional, it's unlikely that your usage model will put the drive in a similar state as our torture test. Our torture test is continuously writing 4KB random data across the drive; in the real world there is almost always some sequential data and idle time in between. As shown in the garbage collection graph, the M3 does not need hours of idle time to restore its performance, so it should maintain its performance pretty well even under an OS with no TRIM.








113 Comments
View All Comments
epobirs - Thursday, April 5, 2012 - link
Kind of sad to see a review where Plextor is treated as an unknown. For quite a long time they were the brand against which all others were judged. For one simple reason: ifPlextor said their drive functioned at speed X, it did. If other companies were claiming a new high performance mark and Plextor hadn't produced a matching product yet, it often meant those other companies were lying about their performance.cjcoats - Thursday, April 5, 2012 - link
I'm a scientific user (environmental model), and I have a transaction-pattern I've never seen SSD benchmarks use:My dataset transactions are of the form "read or
write the record for variable V for time T"
(where record-size S may depend upon the variable;
typical values range from 16K to 100 MB).
The datasets have a matching form:
* a header that indexes the variables, their
records, and various other metadata
* a sequence of data records for the time
steps of the variables.
This may be implemented using one of various
standard scientific dataset libraries (netCDF,
HDF, ...)
A transaction basically is of the form:
Seek to the start of the record for variable
V, time T
Read or write S bytes at that location.
NONE of the SSD benchmarks I've seen have this
kind of "seek, then access" pattern. I have the
suspicion that Sandforce based drives will do
miserably with it, but have no hard info.
Any ideas?
bji - Thursday, April 5, 2012 - link
SSDs have no "seek". Your program's concept of "seek" is just setting the blocks that it will be reading to those at the beginning of a file, but from an SSDs perspective, there is little to no difference between the random access patterns used for a particular operation and any other random access patterns. The only significant difference is between random and serial access.My point being, your case sounds like it is covered exactly by the "random write" and "random read" benchmarks. It doesn't matter which part of the file you are "seeking" to, just that your access is non-sequential. All random access is the same (more or less) to an SSD.
This is most of the performance win of SSDs over HDDs - no seek time. SSDs have no head to move and no latency waiting for the desired sectors to arrive under the head.
cjcoats - Friday, April 6, 2012 - link
I guessed you'd understand the obvious: seek() interacts with data-compression.A seek to a 500MB point may depend upon sequentially decompressing the preceding 500 MB of data in order to figure out what the data-compression has done with that 500MB seek-point!
That's how you have to do seeks in conjunction with the software "gzlib", for example.
So how do SandForce drives deal with that scenario ??
Cerb - Saturday, April 7, 2012 - link
Nobody can say exactly the results for your specific uses, but it would probably be best to focus on other aspects of the drives, given performance of the current lot. You might get a 830, while a 520 could be faster at your specific application, but you'd more than likely be dealing with <10% either way. If it was more than that, a good RAID card would be a worthy addition to your hardware.If you must read the file up to point X, then that's a sequential read. If you read an index and then just read what you need, then that's a random read.
Compression of the data *IN*SOFTWARE* is a CPU/RAM issue, not an SSD issue. For that, focus on incompressible data results.
TBH, though, if you must read 500MB into it to edit a single small record, you should consider seekable data formats, instead of wasting all that CPU time.
bji - Saturday, April 7, 2012 - link
They don't use streaming ciphers. They use block ciphers that encrypt each block individually and independently. Once the data makes it to the drive, there is no concept of 'file', it's just 'sectors' or whatever the block concept is at the SATA interface level. As far as the SSD is concerned, no two sectors have any relationship and wear levelling moves them around the drive in seemingly arbitrary (but designed to spread writes out) ways.Basically what happens is that the drive represents the sequence of sectors on the drive using the same linear addressing scheme as is present in hard drives, but maintains a mapping for each sector from the linear address that the operating system uses to identify it, to whatever unrelated actual block and sub-block address on the device that it is physically located at. Via this mapping the SSD controller can write blocks wherever makes the most sense, but present a consistent linear sector addressing scheme to the operating system. The SSD can even move blocks around in the background and during unrelated writes, which it definitely does to reduce write amplification and once again for wear levelling purposes. The operating system always believes that it wrote the sector at address N, and the SSD will always deliver the same data back when address N is read back, but under the covers the actual data can be moved around and positioned arbitrarily by the SSD.
Given the above, and given that blocks are being written all over the flash all the time regardless of how linearly the operating system thinks it has arranged them, there really isn't any concept of contiguously compressed blocks and having to start back at the beginning of some stream of data to uncompress data.
Keep in mind also that the Sanforce drives do de-duplication as well (as far as I know), which means that for many blocks that have the same contents, only one copy needs to actually be stored in the flash and the block mapping can point multiple operating system sector addresses at the same physical flash block and sub-block segment that has the data. Of course it would have to do copy-on-write when the sector is written but that's not hard once you have all of the rest of the controller machinery built.
SSD controllers must be really interesting tech to work on. I can't imagine all of the cool algorithmic tricks that must be going on under the covers, but it's fun to try.
BolleY2K - Thursday, April 5, 2012 - link
Don´t forget about the Yamaha CRW-F1... ;-)Metaluna - Saturday, April 7, 2012 - link
Heh I still have one of those Yamahas, along with some old Kodak Gold CD-R's. I have no real use for them anymore but hate to toss them.Hourglasss - Thursday, April 5, 2012 - link
You made a forgivable mistake with OCZ's Vertex 4. You said the M3 was the fastest non-sandforce drive. The Vertex 4 is made with OCZ's new everest-2 controller that they developed in-house after acquiring indillix (don't know if they spelled that right). So the M3 is fast, but it's second for non sandforce.zipz0p - Thursday, April 5, 2012 - link
I am glad that I'm not the only one who noticed this! :)