The Xeon E5-2600: Dual Sandy Bridge for Servers
by Johan De Gelas on March 6, 2012 9:27 AM EST- Posted in
- IT Computing
- Virtualization
- Xeon
- Opteron
- Cloud Computing
TrueCrypt 7.1 Benchmark
TrueCrypt is a software application used for on-the-fly encryption (OTFE). It is free, open source and offers full AES-NI support. The application also features a built-in encryption benchmark that we can use to measure CPU performance. First we test with the AES algorithm (256-bit key, symmetric).

Core for Core, clock for clock, the Xeon E5 - which also supports AES-NI - is about 30% faster than the best Opteron (Xeon E5-2660 vs Opteron 6276). At a similar pricepoint (Opteron 6276 vs Xeon E5-2660 6C) however, the Opteron and Xeon E5 perform more or less the same, with a small advantage for the latter.
We also test with the heaviest combination of the cascaded algorithms available: Serpent-Twofish-AES.

The combination benchmark is limited by the slowest algorithms: Twofish and Serpent. This one of the few benchmarks where the Opteron 6276 is able to keep up with the Xeon E5.
It is important to realize that these benchmarks are not real-world but rather are synthetic. It would be better to test a website that does some encrypting in the background or a fileserver with encrypted partitions. In that case the encryption software is only a small part of the total code being run. A large performance (dis)advantage might translate into a much smaller performance (dis)advantage in that real-world situation. For example, eight times faster encryption resulted in a website with 23% higher throughput and a 40% faster file encryption (see here).
7-Zip 9.2
7-zip is a file archiver with a high compression ratio. 7-Zip is open source software, with most of the source code available under the GNU LGPL license
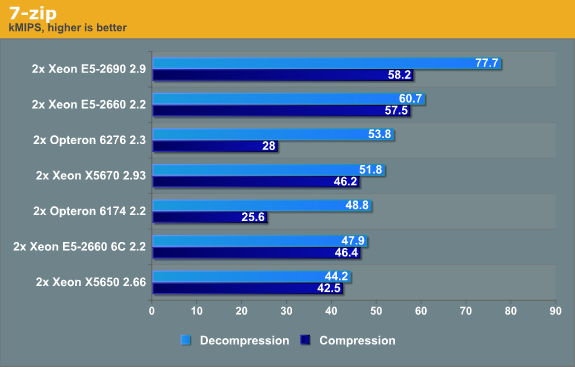
Compression is more CPU intensive than decompression, meanwhile the latter depends a little more on memory bandwidth. When it comes to load/stores and memory bandwidth, the Xeon E5-2660 is about 13% faster than AMD's flagship. Compression is for a part determined by the quality of the branch predictor. The new and improved Sandy Bridge branch predictor is one of the reasons why a 2.2 GHz 6-core 2660 is able to keep up with a 2.93 GHz (!) Xeon 5670, which is also a six-core processor. The Opterons get blown away in the compression benchmark: each core of Xeon E5 is about twice as efficient in this task. The overall winner is thus once again the Xeon E5.








81 Comments
View All Comments
think-ITB-live-OTB - Tuesday, March 6, 2012 - link
Can i ask you a question? do you at least get paid when you bend over for Intel?These are Server Chips - who cares about single-threaded application performance.. or Corporate IPOs. AMD has delivered far greater TCO/performance than Intel has for at least a Decade and running.
You want to praise a company like a Deity? ARM Holdings. nuff said. They can design a 35 dollar computer that can decode H.264 better than Intel can on SoCs that run 4x's the price. Currently have more Chips in more devices than in Intels entire history and Push Power envelopes far beyond anything Intel could ever muster.
Just you wait before the Storm ARM and its Licensees unleash as it will eventually take over ALL markets including the Server space (Calxeda much?). Oh and as for Apple. (an ARM Licensee itself... i can see them moving to in-house ARM designs pretty soon). 4-6-8 Core Cortex A15 (with A7 core for low power iPod/tablet sync) Macbook Airs anyone?
Intel is becoming the strongest of the Dinosaurs. But even the T-Rex fell eventually.
swizeus - Wednesday, March 7, 2012 - link
We have been using the Flemish/Dutch Web 2.0 website Nieuws.be as a benchmark for some time. 99% of the loads on the database are selects and about 5% of them are stored procedures.The database is loaded 104%. is it possible ?
JohanAnandtech - Wednesday, March 7, 2012 - link
Stored procedures can contain selects :-)fredisdead - Saturday, April 7, 2012 - link
From the 'article' .....'The Opteron might also have a role in the low end, price sensitive HPC market, where it still performs very well. It won't have much of chance in the high end clustered one as Intel has the faster and more power efficient PCIe interface'
Well, if that's the case, why exactly would AMD be scoring so many design wins with Interlagos. Including this one ...
http://www.pcmag.com/article2/0,2817,2394515,00.as...
http://www.eweek.com/c/a/IT-Infrastructure/Cray-Ti...
U think those guys at Cray were going for low performance ? In fact, seems like AMD has being rather cleaning up in the HPC market since the arrival of Interlagos. And the markets have picked up on it, AMD stock is thru the roof since the start of the year. Or just see how many Intel processors occupy the the top 10 supercomputers on the planet. Nuff said ...
InsaneScientist - Wednesday, March 7, 2012 - link
Johan, where in the specs where you have this line:Transistors (Billion) 2,26 2x 1,2 2x 904 1,17
I sure hope that 2x 904 (Billion) is a typo... otherwise AMD has some serious explaining to do. ;)
Should be 2x ,904 (I think? Would be 2x .904 for me, I assume you follow the same rules...)
iliev - Wednesday, March 7, 2012 - link
Page 5, Benchmark ConfigurationR2208GZ4GSSPP specs table... E5-2660 is 2.2Ghz, and not 2.9GHz
dodge776 - Wednesday, March 7, 2012 - link
Hi Johan,Always look forward to reading your server reviews at AT, but no SAPS benchmarks this time?
ppennisi - Wednesday, March 7, 2012 - link
For maximum VMware performance on Opteron Interlagos cpu under VMWARE it's better to disable C1E and enable, where available, HPC mode.I found myself on a fresh installation of ESXi 5.0 on Dell R715 that leaving C1E enable literally crippled vm performance.
boudini - Thursday, March 8, 2012 - link
I'm not sure I would recommend using iray as a reliable benchmark renderer in 3ds max. It is not a self configuring mental ray, but an unbiased renderer which behaves fairly differently to mental ray, and most other renderers such as vray, final render and brazil. It is comparible to maxwell and fryrender, but is very new compared to those two longer established unbiased render engines. It also attempts to use the gpu to add to its calculations as well - which could significantly skew results.Using mental ray or vray might well give you quite a different result, and besides I don't think iray is widely used in the industry.
omega4711 - Friday, March 9, 2012 - link
This. The results of iray are mostly dependent on the GPU. The lack of proper scaling certainly isn't due to Amdahl's law. Just use mentalray with small enough render buckets and you can easily satisfy 64+ threads.Also, due to the limitations of iray, it can (at this moment) only be used in about 1-3% of real world scenarios.
Please, for all the people that care about these benchmarks, use mentalray and/or vray.
Otherwise, it's a brilliant article.