Intel's Ivy Bridge Architecture Exposed
by Anand Lal Shimpi on September 17, 2011 2:00 AM EST- Posted in
- CPUs
- Intel
- Ivy Bridge
- IDF 2011
- Trade Shows
Core Architecture Changes
Ivy Bridge is considered a tick from the CPU perspective but a tock from the GPU perspective. On the CPU core side that means you can expect clock-for-clock performance improvements in the 4 - 6% range. Despite the limited improvement in core-level performance there's a lot of cleanup that went into the design. In order to maintain a strict design schedule it's not uncommon for a number of features not to make it into a design, only to be added later in the subsequent product. Ticks are great for this.






Five years ago Intel introduced Conroe which defined the high level architecture for every generation since. Sandy Bridge was the first significant overhaul since Conroe and even it didn't look very different from the original Core 2. Ivy Bridge continues the trend.
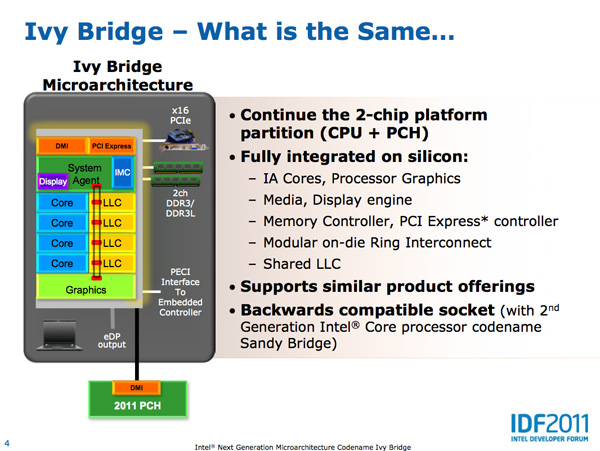
The front end in Ivy Bridge is still 4-wide with support for fusion of both x86 instructions and decoded uOps. The uOp cache introduced in Sandy Bridge remains in Ivy with no major changes.
Some structures within the chip are now better optimized for single threaded execution. Hyper Threading requires a bunch of partitioning of internal structures (e.g. buffers/queues) to allow instructions from multiple threads to use those structures simultaneously. In Sandy Bridge, many of those structures are statically partitioned. If you have a buffer that can hold 20 entries, each thread gets up to 10 entries in the buffer. In the event of a single threaded workload, half of the buffer goes unused. Ivy Bridge reworks a number of these data structures to dynamically allocate resources to threads. Now if there's only a single thread active, these structures will dedicate all resources to servicing that thread. One such example is the DSB queue that serves the uOp cache mentioned above. There's a lookup mechanism for putting uOps into the cache. Those requests are placed into the DSB queue, which used to be split evenly between threads. In Ivy Bridge the DSB queue is allocated dynamically to one or both threads.

In Sandy Bridge Intel did a ground up redesign of its branch predictor. Once again it doesn't make sense to redo it for Ivy Bridge so branch prediction remains the same. In the past prefetchers have stopped at page boundaries since they are physically based. Ivy Bridge lifts this restriction.
The number of execution units hasn't changed in Ivy Bridge, but there are some changes here. The FP/integer divider sees another performance gain this round. Ivy Bridge's divider has twice the throughput of the unit in Sandy Bridge. The advantage here shows up mostly in FP workloads as they tend to be more computationally heavy.
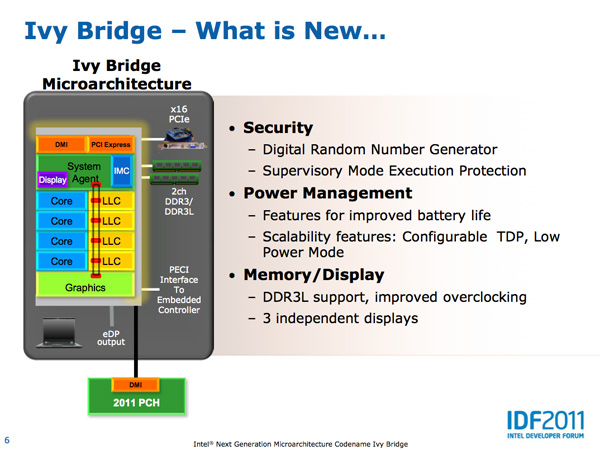
MOV operations can now take place in the register renaming stage instead of making it occupy an execution port. The x86 MOV instruction simply copies the contents of a register into another register. In Ivy Bridge MOVs are executed by simply pointing one register at the location of the destination register. This is enabled by the physical register file first introduced in Sandy Bridge, in addition to a whole lot of clever logic within IVB. Although MOVs still occupy decode bandwidth, the instruction doesn't take up an execution port allowing other instructions to execute in place of it.
ISA Changes

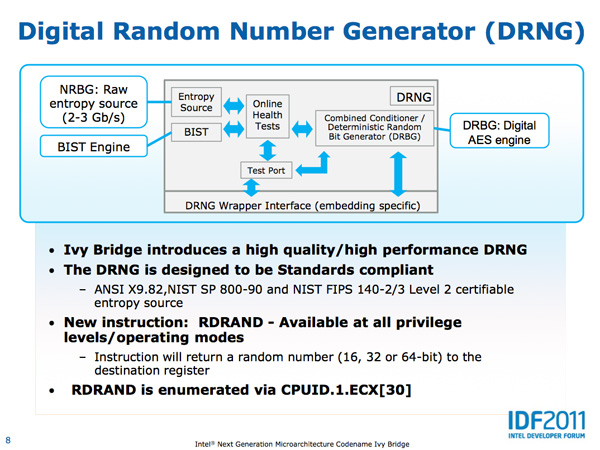
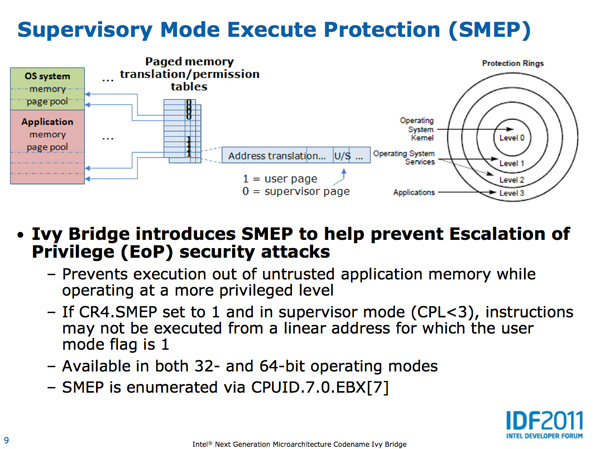
Intel also introduced a number of ISA changes in Ivy Bridge. The ones that stand out the most to me are the inclusion of a very high speed digital random number generator (DRNG) and supervisory mode execution protection (SMEP).
Ivy Bridge's DRNG can generate high quality random numbers (standards compliant) at 2 - 3Gbps. The DRNG is available to both user and OS level code. This will be very important for security and algorithms going forward.
SMEP in Ivy Bridge provides hardware protection against user mode code being executed in more privileged levels.








97 Comments
View All Comments
AstroGuardian - Monday, September 19, 2011 - link
"Intel implied that upward scalability was a key goal of the Ivy Bridge GPU design, perhaps we will see that happen in 2013."No we wont. The world ends in 2012 remember?
JonnyDough - Monday, September 19, 2011 - link
It ended in the year 2000. Hello! Y2K ring any bells? Come on, keep up with current events would ya?TheRyuu - Monday, September 19, 2011 - link
"I've complained in the past about the lack of free transcoding applications (e.g. Handbrake, x264) that support Quick Sync. I suspect things will be better upon Ivy Bridge's arrival."As long as Intel doesn't expose the Quick Sync API there is no way for such applications to make use of it, not to mention the technical limitations.
There are hints on doom9 that they know a bit about the lower level details but that it's all NDA'ed. Even with that knowledge he says that it's probably not possible or probable to do so.
You can find various rambling/rage here:
http://forum.doom9.org/showthread.php?t=156761 (Dark_Shikari and pengvado are the x264 devs).
tl;dr: http://forum.doom9.org/showthread.php?p=1511469#po... (to the end of the thread)
fic2 - Monday, September 19, 2011 - link
I would also wonder who (software wise) would be willing to put a lot of resources into supporting something that isn't really available on most SB platforms - or at least not available without jumping through hoops (correct mb, correct chip, 3rd party software, etc).fic2 - Monday, September 19, 2011 - link
"By the time Ivy Bridge arrives however, AMD will have already taken another step forward with Trinity."I wonder how realistic this is considering that AMD can't even get Bulldozer out the door.
My money is on Ivy Bridge showing up before Trinity.
Beenthere - Monday, September 19, 2011 - link
Considering Trinity was shown at IDF up and running and the fact that Trinity and other AMD nex gen products were developed concurrently with Zambezi and Opteron Bulldozer chips - which have been shipping by the tens of thousands already, I'd say Trinity will be here in Q1 '12.fic2 - Monday, September 19, 2011 - link
"Opteron Bulldozer chips - which have been shipping by the tens of thousands already"And, yet, nobody can benchmark them.
I hope that I am wrong, but given AMD's continual delays shipping the desktop BD I am not holding my breath.
Whichever comes first gets my money - assuming that BD is actually competitive with SB performance.
thebeastie - Tuesday, September 20, 2011 - link
You talk about what's for support for handbrake but to put it harshly your mind is stuck in the past gen device era.I simply grab a full DVD and run makemkv on it to just store it unmodified in a single file and copy it to my iPad2 directly.
Plays perfectly fine under avplayerhd.
I consider it that you would have to be insane as in you think your an onion to bother handbrakin your videos if you got a device like ipad2 that can just play them straight.
If your the hoarder type that insists that you watch Rambo 4 etc every week and need to pack 100+ full movies on your single device at the same time your a freak so pipe you niche life style comments to /dev/null.
I would not understand why you have time to bother shrinking/ converting your movies all the time over just getting sick of some of them and putting new stuff on from time to time.
TheRyuu - Tuesday, September 20, 2011 - link
8.5GB for a movie seems a bit impractical for an ipad.thebeastie - Wednesday, September 21, 2011 - link
Full 8gb is big but they still copy of amazingly quickly over to a ipad2 64gb, a lot of DVDs don't get that full size anyway.If you bought a honeycomb tablet and put sdslot storage on it, I am sure it would be a extremely painfull slow copying experience if you use SD over built in flash, maybe this is what Apple avoid sd lslotd in the first place. Built in flash is lighting fast and less draw on battery.
Having full on pc and just coying over in 2mins vs bothering to convert I know what i just choose full copy every time.
Once I have watched it takes at least a year before I consider watching the same thing again.