Intel's Ivy Bridge Architecture Exposed
by Anand Lal Shimpi on September 17, 2011 2:00 AM EST- Posted in
- CPUs
- Intel
- Ivy Bridge
- IDF 2011
- Trade Shows
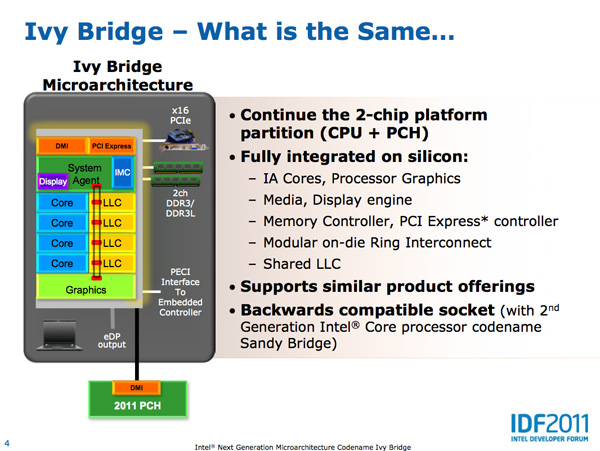
Core Architecture Changes
Ivy Bridge is considered a tick from the CPU perspective but a tock from the GPU perspective. On the CPU core side that means you can expect clock-for-clock performance improvements in the 4 - 6% range. Despite the limited improvement in core-level performance there's a lot of cleanup that went into the design. In order to maintain a strict design schedule it's not uncommon for a number of features not to make it into a design, only to be added later in the subsequent product. Ticks are great for this.






Five years ago Intel introduced Conroe which defined the high level architecture for every generation since. Sandy Bridge was the first significant overhaul since Conroe and even it didn't look very different from the original Core 2. Ivy Bridge continues the trend.
The front end in Ivy Bridge is still 4-wide with support for fusion of both x86 instructions and decoded uOps. The uOp cache introduced in Sandy Bridge remains in Ivy with no major changes.
Some structures within the chip are now better optimized for single threaded execution. Hyper Threading requires a bunch of partitioning of internal structures (e.g. buffers/queues) to allow instructions from multiple threads to use those structures simultaneously. In Sandy Bridge, many of those structures are statically partitioned. If you have a buffer that can hold 20 entries, each thread gets up to 10 entries in the buffer. In the event of a single threaded workload, half of the buffer goes unused. Ivy Bridge reworks a number of these data structures to dynamically allocate resources to threads. Now if there's only a single thread active, these structures will dedicate all resources to servicing that thread. One such example is the DSB queue that serves the uOp cache mentioned above. There's a lookup mechanism for putting uOps into the cache. Those requests are placed into the DSB queue, which used to be split evenly between threads. In Ivy Bridge the DSB queue is allocated dynamically to one or both threads.

In Sandy Bridge Intel did a ground up redesign of its branch predictor. Once again it doesn't make sense to redo it for Ivy Bridge so branch prediction remains the same. In the past prefetchers have stopped at page boundaries since they are physically based. Ivy Bridge lifts this restriction.
The number of execution units hasn't changed in Ivy Bridge, but there are some changes here. The FP/integer divider sees another performance gain this round. Ivy Bridge's divider has twice the throughput of the unit in Sandy Bridge. The advantage here shows up mostly in FP workloads as they tend to be more computationally heavy.
MOV operations can now take place in the register renaming stage instead of making it occupy an execution port. The x86 MOV instruction simply copies the contents of a register into another register. In Ivy Bridge MOVs are executed by simply pointing one register at the location of the destination register. This is enabled by the physical register file first introduced in Sandy Bridge, in addition to a whole lot of clever logic within IVB. Although MOVs still occupy decode bandwidth, the instruction doesn't take up an execution port allowing other instructions to execute in place of it.
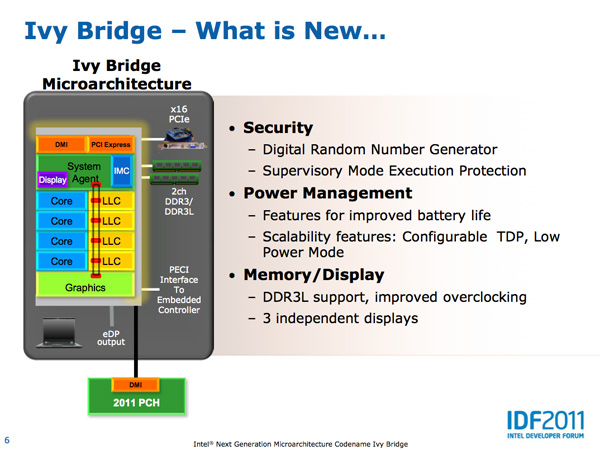
ISA Changes

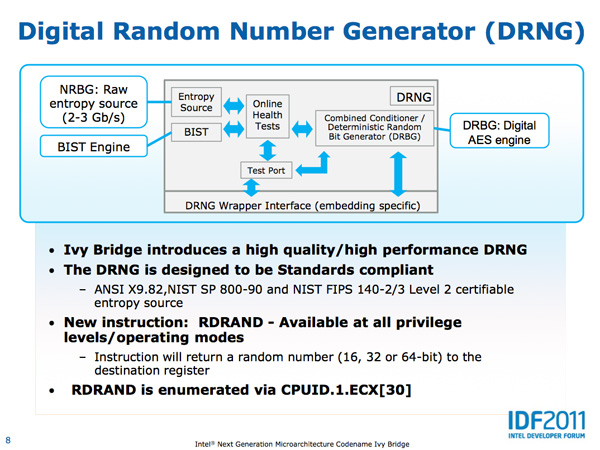
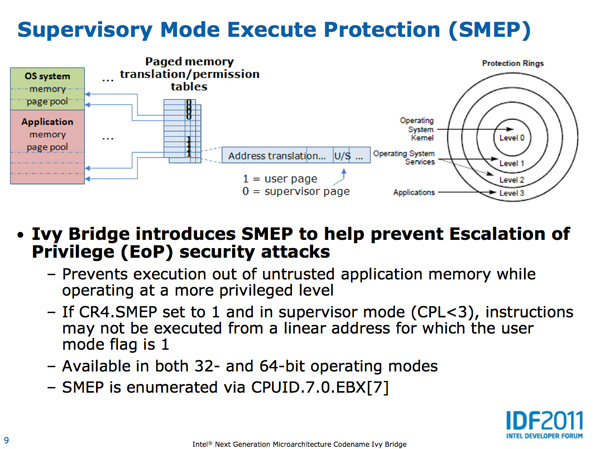
Intel also introduced a number of ISA changes in Ivy Bridge. The ones that stand out the most to me are the inclusion of a very high speed digital random number generator (DRNG) and supervisory mode execution protection (SMEP).
Ivy Bridge's DRNG can generate high quality random numbers (standards compliant) at 2 - 3Gbps. The DRNG is available to both user and OS level code. This will be very important for security and algorithms going forward.
SMEP in Ivy Bridge provides hardware protection against user mode code being executed in more privileged levels.








97 Comments
View All Comments
JonnyDough - Monday, September 19, 2011 - link
4-5 year old GPU? Heh, bud...most hardware takes years to develop. And the HD3000 series may be a bit dated but it makes even the XBox 360 look weak in comparison. Hardly dismal.moozoo - Saturday, September 17, 2011 - link
Does its GPU support double precision under OpenCL? i.e. cl_khr_fp64Does Trinity?
Ryan Smith - Saturday, September 17, 2011 - link
We don't have solid details on either one, but don't count on it. The reasons we don't see full FP64 support on non-halo GPUs are still in play for CPUs.Galcobar - Saturday, September 17, 2011 - link
Perhaps I'm missing something in the acronyms, but the table and text seems to disagree on the availability of SSD caching.The text states "All of the 7-series consumer chipsets will support Intel's Rapid Storage Technology (RST, aka SSD caching)."
The table, however, puts No under the Z75 column for Intel SRT (SSD caching).
As I understand things, you need RST (software) to support SRT (bound to the motherboard), but without SRT you don't get SSD caching.
Anand Lal Shimpi - Saturday, September 17, 2011 - link
Fixed :) SRT is only on the Z77/H77, not the Z75.Take care,
Anand
mlkmade - Saturday, September 17, 2011 - link
I know its really early to be talking about this cause ivy won't be out for awhile..but what about what amounts to be "ivyb-e" ? I'm sure details are very scarce...but will it follow the desktop path (both s1155) and be socket compatible? in this case s2011? if ivyb-e is socket compatible with sb-e...that'd be great..but by then all the chipset problems would be fleshed out huh..buy a new mono anywayAnand Lal Shimpi - Saturday, September 17, 2011 - link
I would hope so, but as of now there is no IVB-E on the roadmaps so anything I'd say here would be uninformed and speculative at this point :-/Take care,
Anand
ltcommanderdata - Saturday, September 17, 2011 - link
Does Ivy Bridge finally allow the IGP and QuickSync engine to be available even with a discrete GPU plugged in for both mobile and desktop without resorting to specific chipsets (ie. limited to the high-end chipset) or third-party software (relying on motherboard makers and OEMs to deal with Lucid)? WIth the IGP being OpenCL and DirectCompute capable, even if you have the latest Quad SLI/Crossfire setup it would be useful to have the IGP help out in GPGPU tasks.And it's interesting that with AMD introducing a beefier form of SMT with two full integer cores, Intel decided not to similarly increase hardware resource duplication to expand Hyperthreading. Instead Intel is focusing on improving single threaded performance by making sure a single thread can use all the resources if Hyperthreading is not needed. Seeing most software isn't making use of 8 simultaneous threads, focusing on making 4 threads (1 per core) work as fast as possible does make sense.
Meegulthwarp - Saturday, September 17, 2011 - link
"As we've already seen, introducing a 35W quad-core part could enable Apple to ship a quad-core IVB in a 13-inch MacBook Pro." Here is to hoping that someone other than apple will also ship a decent 13-inch with a quad.Other than that great insight, I really hope the GPU on IVB will be half way useable. I think we've hit a point where CPU performance is more than adequate for 95% of consumers. Now just need to up the GPU performance and get power down so we can use our laptops on battery all day. I'm more than happy with my 2 year old C2D CPU performance but want battery life, hugely tempted with AMD's A6-3400M. But with Bulldozer looming I think I may hold back for 6 months.
Anand Lal Shimpi - Saturday, September 17, 2011 - link
I hope so too, I simply used Apple as an example because it has migrated to quad-core in every member of its MBP family with the exception of the 13-inch. I've updated the statement to be a bit more broad :)Take care,
Anand