Intel's Ivy Bridge Architecture Exposed
by Anand Lal Shimpi on September 17, 2011 2:00 AM EST- Posted in
- CPUs
- Intel
- Ivy Bridge
- IDF 2011
- Trade Shows
Core Architecture Changes
Ivy Bridge is considered a tick from the CPU perspective but a tock from the GPU perspective. On the CPU core side that means you can expect clock-for-clock performance improvements in the 4 - 6% range. Despite the limited improvement in core-level performance there's a lot of cleanup that went into the design. In order to maintain a strict design schedule it's not uncommon for a number of features not to make it into a design, only to be added later in the subsequent product. Ticks are great for this.






Five years ago Intel introduced Conroe which defined the high level architecture for every generation since. Sandy Bridge was the first significant overhaul since Conroe and even it didn't look very different from the original Core 2. Ivy Bridge continues the trend.
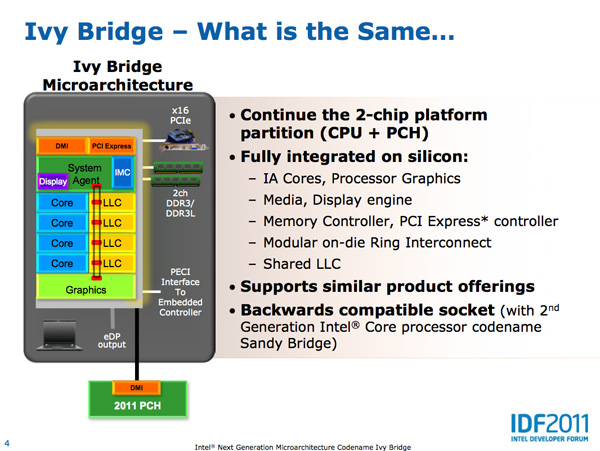
The front end in Ivy Bridge is still 4-wide with support for fusion of both x86 instructions and decoded uOps. The uOp cache introduced in Sandy Bridge remains in Ivy with no major changes.
Some structures within the chip are now better optimized for single threaded execution. Hyper Threading requires a bunch of partitioning of internal structures (e.g. buffers/queues) to allow instructions from multiple threads to use those structures simultaneously. In Sandy Bridge, many of those structures are statically partitioned. If you have a buffer that can hold 20 entries, each thread gets up to 10 entries in the buffer. In the event of a single threaded workload, half of the buffer goes unused. Ivy Bridge reworks a number of these data structures to dynamically allocate resources to threads. Now if there's only a single thread active, these structures will dedicate all resources to servicing that thread. One such example is the DSB queue that serves the uOp cache mentioned above. There's a lookup mechanism for putting uOps into the cache. Those requests are placed into the DSB queue, which used to be split evenly between threads. In Ivy Bridge the DSB queue is allocated dynamically to one or both threads.

In Sandy Bridge Intel did a ground up redesign of its branch predictor. Once again it doesn't make sense to redo it for Ivy Bridge so branch prediction remains the same. In the past prefetchers have stopped at page boundaries since they are physically based. Ivy Bridge lifts this restriction.
The number of execution units hasn't changed in Ivy Bridge, but there are some changes here. The FP/integer divider sees another performance gain this round. Ivy Bridge's divider has twice the throughput of the unit in Sandy Bridge. The advantage here shows up mostly in FP workloads as they tend to be more computationally heavy.
MOV operations can now take place in the register renaming stage instead of making it occupy an execution port. The x86 MOV instruction simply copies the contents of a register into another register. In Ivy Bridge MOVs are executed by simply pointing one register at the location of the destination register. This is enabled by the physical register file first introduced in Sandy Bridge, in addition to a whole lot of clever logic within IVB. Although MOVs still occupy decode bandwidth, the instruction doesn't take up an execution port allowing other instructions to execute in place of it.
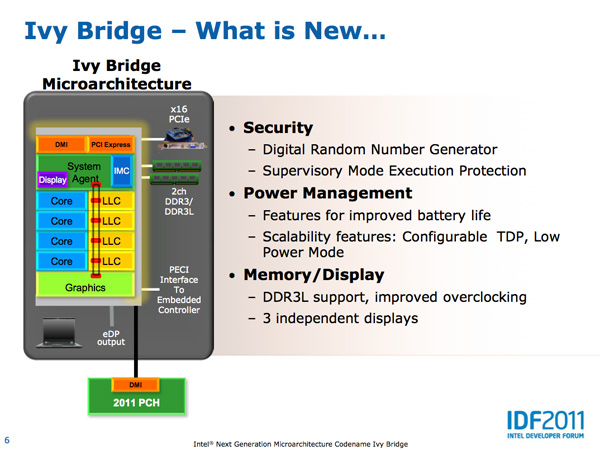
ISA Changes

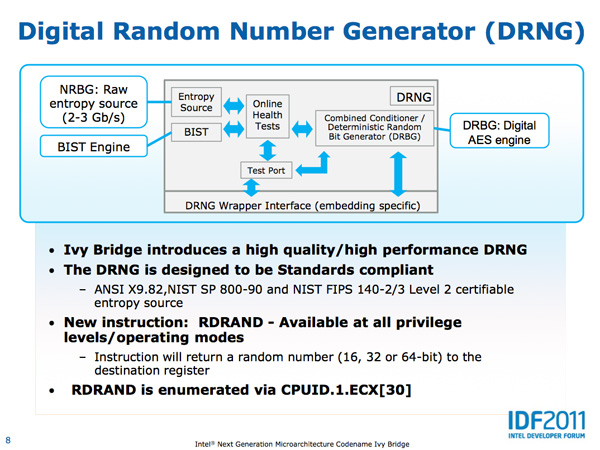
Intel also introduced a number of ISA changes in Ivy Bridge. The ones that stand out the most to me are the inclusion of a very high speed digital random number generator (DRNG) and supervisory mode execution protection (SMEP).
Ivy Bridge's DRNG can generate high quality random numbers (standards compliant) at 2 - 3Gbps. The DRNG is available to both user and OS level code. This will be very important for security and algorithms going forward.
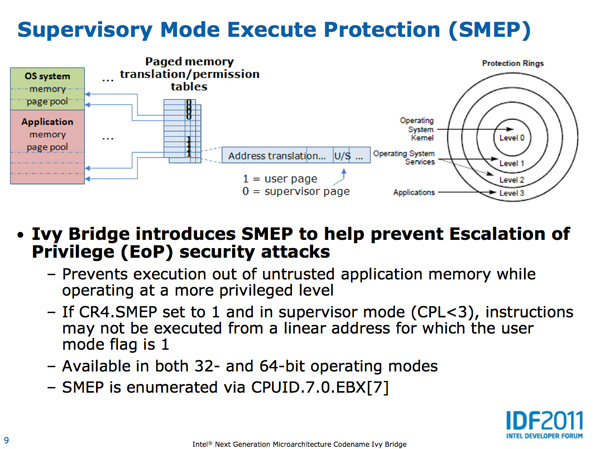
SMEP in Ivy Bridge provides hardware protection against user mode code being executed in more privileged levels.








97 Comments
View All Comments
NeBlackCat - Wednesday, September 21, 2011 - link
The GPU part would be streets ahead, the drivers would be good, Tegra 3 (4..5...) on the 22nm trigate process is an absolutely mouth-watering proposition, and who knows what else could have been accomplished with the engineering effort saved on Intel GPUs and the (so far) fruitless efforts to push x86 into smart consumer devices.On the downside, there's be no AMD.
mrpatel - Wednesday, September 21, 2011 - link
The iMac 2011 27" model ships with the Z68 chipset.So the question is whether or not it would support IVY BRIDGE CPUs in it? (given that all other things like TDP etc requirements match up).
I wonder if IVY BRIDGE CPUs would require a full EFI or kernel module upgrade to be supported? (i mean i really don't care if the USB 3.0 works, but I do care about the new design, gpu performance and lower power to performance ratio compared to sandy bridge!).
caggregate - Friday, September 23, 2011 - link
So being that this is a current/future platform, what's the big deal about support for DDR3L (which as a standard was ratified in July 2010)? I realize the specs of DDR3U ("Ultra low voltage" 1.25V) are not "final" yet, but you'd think it would be implemented given that DDR3U has been available to engineers (according to Hynix/Google) since June 2010.fb39ca4 - Sunday, September 25, 2011 - link
No OpenGL 4 support? Seriously?OCguy - Tuesday, September 27, 2011 - link
Are they even trying anymore?Olbi - Tuesday, October 18, 2011 - link
I wonder why Intel add DX11, but no OpenGL 4? Both are needed by developers of apps and DX11 isnt need by allmost all app. OpenGL 4 is needed by Linux desktop like KDE 4, GNOME, Xfce and others. So why Intel still doesnt support it.tkafafi - Tuesday, March 20, 2012 - link
Why do the new intel chipsets (series 7) still contain so many (10) usb2 ports ? Would any PC/laptop manufacturer chose to use a usb2 port instead of anavailable usb3 port from the chipset ? for e.g would they use 2 usb2 + 2usb3 instead of 4 usb3 from the chipset ?I know PC manufacturers are using this configuration (2 usb2 + 2 usb3) because now they need to support usb3 through an external controller so they are saving cost by using a 2 port controller. But once series 7 chipsets arrive with native usb3 support, there would be no cost advantage to do this. Is this to derisk any interoperability issues with older usb2 devices (i.e if for some reason usb3 ports don't work well with some existing usb2 devices) ?
Thanks