OCZ Vertex 3 (240GB) Review
by Anand Lal Shimpi on May 6, 2011 1:50 AM ESTThree months ago we previewed the first client focused SF-2200 SSD: OCZ's Vertex 3. The 240GB sample OCZ sent for the preview was four firmware revisions older than what ended up shipping to retail last month, but we hoped that the preview numbers were indicative of final performance.
The first drives off the line when OCZ went to production were 120GB capacity models. These drives have 128GiB of NAND on board and 111GiB of user accessible space, the remaining 12.7% is used for redundancy in the event of NAND failure and spare area for bad block allocation and block recycling.

Unfortunately the 120GB models didn't perform as well as the 240GB sample we previewed. To understand why, we need to understand a bit about basic SSD architecture. SandForce's SF-2200 controller has 8 channels that it can access concurrently, it looks sort of like this:
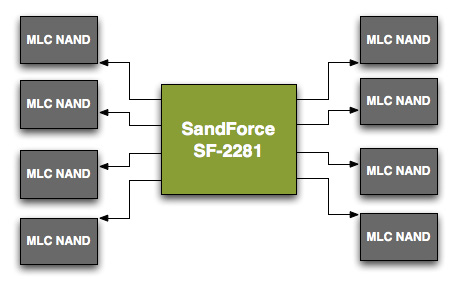
Each arrowed line represents a single 8-byte channel. In reality, SF's NAND channels are routed from one side of the chip so you'll actually see all NAND devices to the right of the controller on actual shipping hardware.
Even though there are 8 NAND channels on the controller, you can put multiple NAND devices on a single channel. Two NAND devices can't be actively transferring data at the same time. Instead what happens is one chip is accessed while another is either idle or busy with internal operations.
When you read from or write to NAND you don't write directly to the pages, you instead deal with an intermediate register that holds the data as it comes from or goes to a page in NAND. The process of reading/programming is a multi-step endeavor that doesn't complete in a single cycle. Thus you can hand off a read request to one NAND device and then while it's fetching the data from an internal page, you can go off and program a separate NAND device on the same channel.
Because of this parallelism that's akin to pipelining, with the right workload and a controller that's smart enough to interleave operations across NAND devices, an 8-channel drive with 16 NAND devices can outperform the same drive with 8 NAND devices. Note that the advantage can't be double since ultimately you can only transfer data to/from one device at a time, but there's room for non-insignificant improvement. Confused?
Let's look at a hypothetical SSD where a read operation takes 5 cycles. With a single die per channel, 8-byte wide data bus and no interleaving that gives us peak bandwidth of 8 bytes every 5 clocks. With a large workload, after 15 clock cycles at most we could get 24 bytes of data from this NAND device.

Hypothetical single channel SSD, 1 read can be issued every 5 clocks, data is received on the 5th clock
Let's take the same SSD, with the same latency but double the number of NAND devices per channel and enable interleaving. Assuming we have the same large workload, after 15 clock cycles we would've read 40 bytes, an increase of 66%.
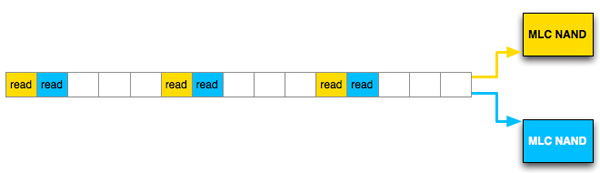
Hypothetical single channel SSD, 1 read can be issued every 5 clocks, data is received on the 5th clock, interleaved operation
This example is overly simplified and it makes a lot of assumptions, but it shows you how you can make better use of a single channel through interleaving requests across multiple NAND die.
The same sort of parallelism applies within a single NAND device. The whole point of the move to 25nm was to increase NAND density, thus you can now get a 64Gbit NAND device with only a single 64Gbit die inside. If you need more than 64Gbit per device however you have to bundle multiple die in a single package. Just as we saw at the 34nm node, it's possible to offer configurations with 1, 2 and 4 die in a single NAND package. With multiple die in a package, it's possible to interleave read/program requests within the individual package as well. Again you don't get 2 or 4x performance improvements since only one die can be transferring data at a time, but interleaving requests across multiple die does help fill any bubbles in the pipeline resulting in higher overall throughput.
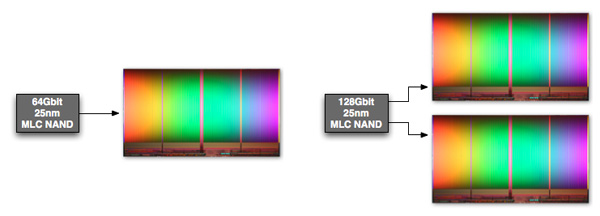
Intel's 128Gbit 25nm MLC NAND features two 64Gbit die in a single package
Now that we understand the basics of interleaving, let's look at the configurations of a couple of Vertex 3s.
The 120GB Vertex 3 we reviewed a while back has sixteen NAND devices, eight on each side of the PCB:

OCZ Vertex 3 120GB - front
These are Intel 25nm NAND devices, looking at the part number tells us a little bit about them.

You can ignore the first three characters in the part number, they tell you that you're looking at Intel NAND. Characters 4 - 6 (if you sin and count at 1) indicate the density of the package, in this case 64G means 64Gbits or 8GB. The next two characters indicate the device bus width (8-bytes). Now the ninth character is the important one - it tells you the number of die inside the package. These parts are marked A, which corresponds to one die per device. The second to last character is also important, here E stands for 25nm.
Now let's look at the 240GB model:

OCZ Vertex 3 240GB - Front

OCZ Vertex 3 240GB - Back
Once again we have sixteen NAND devices, eight on each side. OCZ standardized on Intel 25nm NAND for both capacities initially. The density string on the 240GB drive is 16B for 16Gbytes (128 Gbit), which makes sense given the drive has twice the capacity.
A look at the ninth character on these chips and you see the letter C, which in Intel NAND nomenclature stands for 2 die per package (J is for 4 die per package if you were wondering).

While OCZ's 120GB drive can interleave read/program operations across two NAND die per channel, the 240GB drive can interleave across a total of four NAND die per channel. The end result is a significant improvement in performance as we noticed in our review of the 120GB drive.
| OCZ Vertex 3 Lineup | |||||
| Specs (6Gbps) | 120GB | 240GB | 480GB | ||
| Raw NAND Capacity | 128GB | 256GB | 512GB | ||
| Spare Area | ~12.7% | ~12.7% | ~12.7% | ||
| User Capacity | 111.8GB | 223.5GB | 447.0GB | ||
| Number of NAND Devices | 16 | 16 | 16 | ||
| Number of die per Device | 1 | 2 | 4 | ||
| Max Read | Up to 550MB/s | Up to 550MB/s | Up to 530MB/s | ||
| Max Write | Up to 500MB/s | Up to 520MB/s | Up to 450MB/s | ||
| 4KB Random Read | 20K IOPS | 40K IOPS | 50K IOPS | ||
| 4KB Random Write | 60K IOPS | 60K IOPS | 40K IOPS | ||
| MSRP | $249.99 | $499.99 | $1799.99 | ||
The big question we had back then was how much of the 120/240GB performance delta was due to a reduction in performance due to final firmware vs. a lack of physical die. With a final, shipping 240GB Vertex 3 in hand I can say that the performance is identical to our preview sample - in other words the performance advantage is purely due to the benefits of intra-device die interleaving.
If you want to skip ahead to the conclusion feel free to, the results on the following pages are near identical to what we saw in our preview of the 240GB drive. I won't be offended :)
The Test
| CPU |
Intel Core i7 965 running at 3.2GHz (Turbo & EIST Disabled) Intel Core i7 2600K running at 3.4GHz (Turbo & EIST Disabled) - for AT SB 2011, AS SSD & ATTO |
| Motherboard: |
Intel DX58SO (Intel X58) Intel H67 Motherboard |
| Chipset: |
Intel X58 + Marvell SATA 6Gbps PCIe Intel H67 |
| Chipset Drivers: |
Intel 9.1.1.1015 + Intel IMSM 8.9 Intel 9.1.1.1015 + Intel RST 10.2 |
| Memory: | Qimonda DDR3-1333 4 x 1GB (7-7-7-20) |
| Video Card: | eVGA GeForce GTX 285 |
| Video Drivers: | NVIDIA ForceWare 190.38 64-bit |
| Desktop Resolution: | 1920 x 1200 |
| OS: | Windows 7 x64 |








90 Comments
View All Comments
Just3r1d7 - Saturday, May 7, 2011 - link
Dear Anand,I have been carefully reading SSD articles for the past 18 months waiting for the right time to make a purchase for both my home and work PCs... The depth and breadth of SSD coverage on AnandTech has been stellar, and this latest Vertex 3 review is no exception.
It's clear that the Vertex 3 240GB is the "best performing" drive for $500. However, as other posters have noted, all of the information floating around about SSDs hasn't necessarily resulted in clear guidelines or practical recommendations.
My guess is that the "average" user isn't going to spend $500 on an SSD for their home PC... Thus, as you continue to conduct these reviews, it may be helpful to compile a table/chart to guide your dedicated readers (and anyone else who browses the site). This would also have the benefit of reducing the number of "I have Processor A, Chipset B, and Operating System C, which SSD should I buy?" questions that arise.
Here are a few examples of questions which seem to come up repeatedly and could probably be answered by a summary table of recommendations based on drives currently available in retail channels:
1. What is the best "small" capacity drive? (at any cost)
2. What is the best "low cost" drive? (at any capacity)
3. What is the best performing OS/application drive?
4. What is the best drive for non-TRIM supported OS? (e.g. WinXP or Mac)
5. What is the best (most reliable) drive for a business PC?
Just some food for thought... Keep up the great work on the SSD coverage and reviews!
-Bob
Wardrop - Saturday, May 7, 2011 - link
Anyone know when OCZ will refresh their RevoDrive line with SF2xxx controllers? I'll be getting one of them.iwod - Sunday, May 8, 2011 - link
In an ideal world, the NAND would get smaller every node shrink, and we could fit more die inside an NAND package.However with every die shrink they also double the capacity of the minimum die size. i.e from 64Gbit to 128 Gbit ... etc
If 8 Channel and 8 NAND Package being a constant factor, we are only going to get more capacity at the same price, but not lower price at lower capacity.
Is there any reason behind this?
And that is why when i see people saying i will wait for SSD to drop below $50 etc.... They are halving the price every year so i will wait a year or two before i get it. The truth is it is never going to happen. The absolute minimum BOM *equation* for SSD has stay constant for years. Unless the minimum price per NAND die is going to drop, may be what we see today is already the absolute minimum price / SSD we will ever see?
ibliblibli - Sunday, May 8, 2011 - link
A thorough review, but I'd like to understand why the HDTach charts showing the read-and-write performance before-torture, after-torture and post-TRIM are not shown. I know the average sustained writes do not change much even after torturing the drive, but I'm interested in the volatility. None of other the articles covering the latest Sand Force drives (OCZ Vertex 3 Pro/Non-Pro 240 GB Previews, OCZ Vertex 3 120 GB Review, OWC Mercury Extreme Pro 6G Review) show this data either. However, the reviews for the other new drives (Intel 510, Intel 320 and Crucial m4) includes those charts. Is there a reason for this exclusion? The information from those charts is helpful.NorthShoreExile - Monday, May 9, 2011 - link
Based on the initial review, I ordered one for my new build. It took weeks to arrive but I finally got it. All I can say is "WOW"! It is everything it claims to be.jinino - Monday, May 9, 2011 - link
Great review Anand,From the photo in the last page, I see the disk is made in Taiwan. Do you happen to know that OCZ's SSD is manufactured by the same OEM in Taiwan as the manufacturer for Intel's SSD?
alpha754293 - Monday, May 9, 2011 - link
Wonderful review on the OCZ Vertex 3 SSD.I was wondering if you might be able to run the full h2benchw benchmark on the drive?
You should be able to download it here:
http://www.heise.de/software/download/h2benchw/378... or just google it.
Can you post or email me the results please?
Thank you.
ueharaf - Tuesday, May 10, 2011 - link
what is the difference between vertex 3 and solid 3?http://www.ocztechnology.com/ocz-solid-3-sata-iii-...
sanguy - Tuesday, May 10, 2011 - link
Hi,We just received 5 Vertex 3 240GB drives for installation into some Dell E6520 laptops. We did the install but with the Vertex 3 installed we've been having random system lock-ups that require a hard boot.
We are in AHCI mode in the bios and running Windows 7x64 with the 10.1 Intel RST drivers. Drives are firmware 2.02.
We are seeing this on several laptops/drives so it's not a one off.
Drive is detected by the toolkit OCZ has available, and RST reports it correct at 6Gbps.
These are sandy bridge quad core laptops using a 6 series chipset.
Anyone seeing compatibility issues? I did find a thread at OCZ over disabling some function in the registry which we did without it solving the issue.
DanaG - Wednesday, May 11, 2011 - link
I'd say Sandforce drives are just plain buggy, if you try to do anything non-desktop with them. (Even my old Indilinx drive was more stable.)From what you're seeing, the new ones must be even worse than the old ones.
Check my comments on Page 6, and this link:
http://www.ocztechnologyforum.com/forum/showthread...