Westmere-EX: Intel's Flagship Benchmarked
by Johan De Gelas on May 19, 2011 1:30 PM EST- Posted in
- IT Computing
- Intel
- Xeon
- Cloud Computing
- Westmere-EX
Intel's Best x86 Server CPU
The launch of the Nehalem-EX a year ago was pretty spectacular. For the first time in Intel's history, the high-end Xeon did not have any real weakness. Before the Nehalem-EX, the best Xeons trailed behind the best RISC chips in either RAS, memory bandwidh, or raw processing power. The Nehalem-EX chip was well received in the market. In 2010, Intel's datacenter group reportedly brought in $8.57 billion, an increase of 35% over 2009.
The RISC server vendors have lost a lot of ground to the x86 world. According to IDC's Server Tracker (Q4 2010), the RISC/mainframe market share has halved since 2002, while Intel x86 chips now command almost 60% of the market. Interestingly, AMD grew from a negligble 0.7% to a decent 5.5%.

Only one year later, Intel is upgrading the top Xeon by introducing Westmere-EX. Shrinking Intel's largest Xeon to 32nm allows it to be clocked slightly higher, get two extra cores, and add 6MB L3 cache. At the same time the chip is quite a bit smaller, which makes it cheaper to produce. Unfortunately, the customer does not really benefit from that fact, as the top Xeon became more expensive. Anyway, the Nehalem-EX was a popular chip, so it is no surprise that the improved version has persuaded 19 vendors to produce 60 different designs, ranging from two up to 256 sockets.
Of course, this isn't surprising as even mediocre chips like Intel Xeon 7100 series got a lot of system vendor support, a result of Intel's dominant position in the server market. With their latest chip, Intel promises up to 40% better performance at slightly lower power consumption. Considering that the Westmere-EX is the most expensive x86 CPU, it needs to deliver on these promises, on top of providing rich RAS features.
We were able to test Intel's newest QSSC-S4R server, with both "normal" and new "low power" Samsung DIMMs.
Some impressive numbers
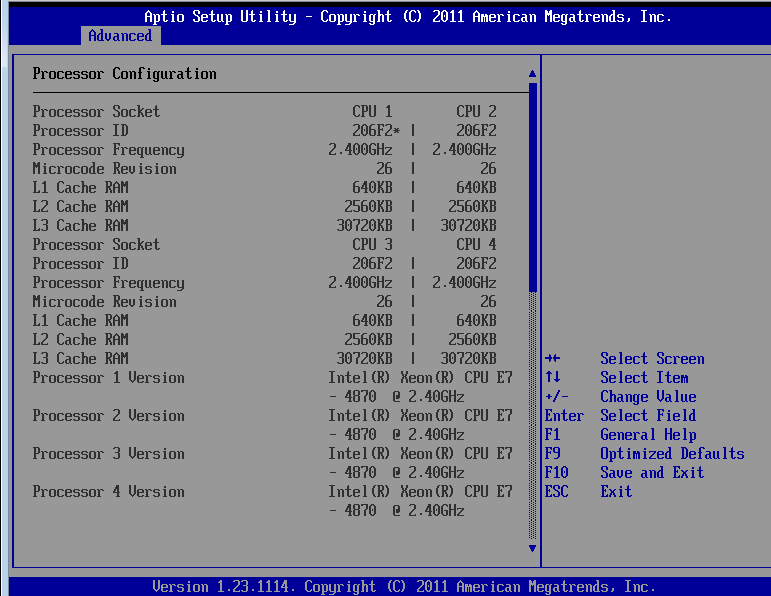
The new Xeon can boast some impressive numbers. Thanks to its massive 30MB L3 cache it has even more transistors than the Intel "Tukwilla" Itanium: 2.6 billion versus 2 billion transistors. Not that such items really matter without the performance and architecture to back it up, but the numbers ably demonstrate the complexity of these server CPUs.
| Processor Size and Technology Comparison | ||||
| CPU | transistors count (million) | Process |
Die Size (mm²) |
Cores |
| Intel Westmere-EX | 2600 | 32 nm | 513 | 10 |
| Intel Nehalem-EX | 2300 | 45 nm | 684 | 8 |
| Intel Dunnington | 1900 | 45 nm | 503 | 6 |
| Intel Nehalem | 731 | 45 nm | 265 | 4 |
| IBM Power 7 | 1200 | 45 nm | 567 | 8 |
| AMD Magny-cours | 1808 (2x 904) | 45 nm | 692 (2x 346) | 12 |
| AMD Shanghai | 705 | 45 nm | 263 | 4 |








62 Comments
View All Comments
extide - Monday, June 6, 2011 - link
When you spend $100,000 + on the S/W running on it, the HW costs don't matter. Recently I was in a board meeting for launching a new website that the company I work for is going to be running. These guys don't know/care about these detailed specs/etc. They simply said, "Cost doesn't matter just get whatever is the fastest."alpha754293 - Thursday, May 19, 2011 - link
Can you run the Fluent and LS-DYNA benchmarks on the system please? Thanks.mosu - Thursday, May 19, 2011 - link
A good presentation with onest conclusions, I like this one.ProDigit - Thursday, May 19, 2011 - link
What if you would compare it to 2x corei7 desktops, running Linux and free server software, what keeps companies from doing that?Orwell - Thursday, May 19, 2011 - link
Most probably the lack of support for more than about 48GiB of RAM, the lack of ECC in the case of Intel and the lack of multisocket-support, just to name a few.ganjha - Thursday, May 19, 2011 - link
There is always the option of clusters...L. - Friday, May 20, 2011 - link
Err... like you're going to go cheap for the CPU and then put everything on infiniband --DanNeely - Thursday, May 19, 2011 - link
Many of the uses for this class of server involve software that won't scale across multiple boxes due to network latency, or monolithic design. The VM farm test was one example that would; but the lack of features like ECC support would preclude it from consideration by 99% of the buyers of godbox servers.erple2 - Thursday, May 19, 2011 - link
I think that more and more people are realizing that the issue is more about lack of scaling linearly than anything like ECC. Buying a bullet proof server is turning out to cost way too much money (I mean ACTUALLY bullet proof, not "so far, this server has been rock solid for me").I read an interesting article about "design for failure" (note, NOT the same thing as "design to fail") by Jeff Atwood the other day, and it really opened my eyes. Each extra 9 in 99.99% uptime starts costing exponentially more money. That kind of begs the question, should you be investing more money into a server that shouldn't fail, or should you be investigating why your software is so fragile as to not be able to accommodate a hardware failure?
I dunno. Designing and developing software that can work around hardware failures is a very difficult thing to do.
L. - Thursday, May 19, 2011 - link
Well ./ obvious.Who has a fton of servers ? Google
How do they manage availability ?
So much redundancy that resilience is implicit and "reduced service" isn't even all that reduced.
And no designing / dev s/w that works around h/w failures is not that hard at all, and it is in fact quite common (load balancing, active/passive stuff, virtualization helps too etc.).