OCZ's Fastest SSD, The IBIS and HSDL Interface Reviewed
by Anand Lal Shimpi on September 29, 2010 12:01 AM ESTNo TRIM, but Garbage Collection
The IBIS drive features a four-controller internal RAID, and there’s currently no way to pass TRIM along to drives in a RAID array, which means its very important to have a resilient controller. OCZ stuck with SandForce and the SF-1200, the most resilient controller on the market today. To make things better however the drive supports idle time garbage collection. With an active NTFS partition on the drive, no IO activity and sufficient free space, the controllers will begin cleaning up the NAND. The effect is profound, below we have a clean drive:
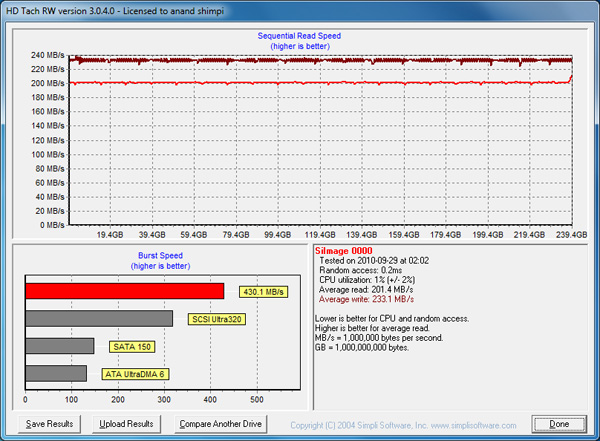
Now, after we've filled the drive and tortured it with random writes:
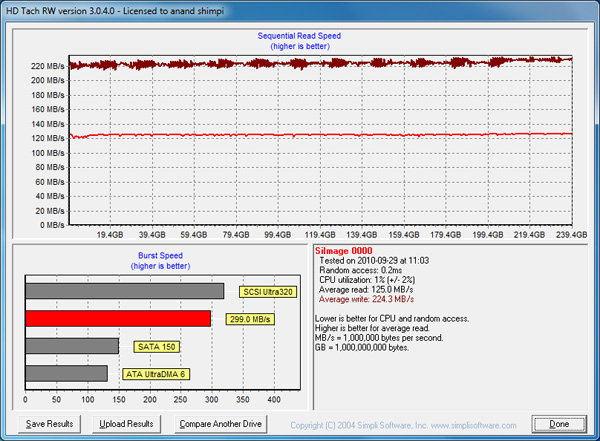
Note that peak low queue-depth read speed dropped from ~233MB/s down to 120MB/s. Now here’s performance after the drive has been left idle for half an hour:
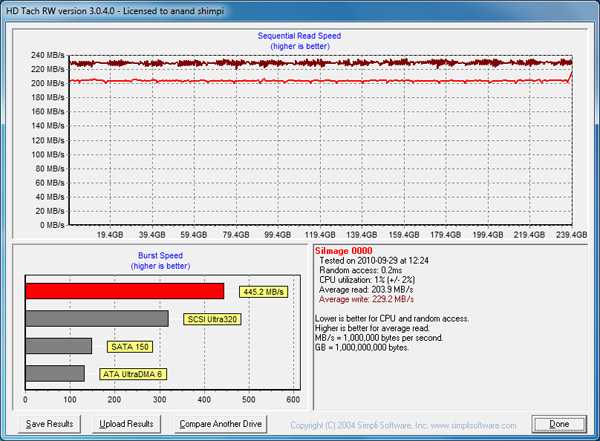
Remember this is very low queue depth testing so the peak values aren't very high, but it's enough to show the idle garbage collection working.








74 Comments
View All Comments
jwilliams4200 - Wednesday, September 29, 2010 - link
Anand:I suspect your resiliency test is flawed. Doesn't HD Tach essentially write a string of zeros to the drive? And a Sandforce drive would compress that and only write a tiny amount to flash memory. So it seems to me that you have only proved that the drives are resilient when they are presented with an unrealistic workload of highly compressible data.
I think you need to do two things to get a good idea of resiliency:
(1) Write a lot of random (incompressible) data to the drive to get it "dirty"
(2) Measure the write performance of random (incompressible) data while the SSD is "dirty"
It is also possible to combine (1) and (2) in a single test. Start with a "clean" SSD, then configure IO meter to write incompressible data continuously over the entire SSD span, say random 4KB 100% write. Measure the write speed once a minute and plot the write speed vs. time to see how the write speed degrades as the SSD gets dirty. This is a standard test done by Calypso system's industrial SSD testers. See, for example, the last graph here:
http://www.micronblogs.com/2010/08/setting-a-new-b...
Also, there is a strange problem with Sandforce-controlled "dirty" SSDs having degraded write speed which is not recovered after TRIM, but it only shows up with incompressible data. See, for example:
http://www.bit-tech.net/hardware/storage/2010/08/1...
Anand Lal Shimpi - Wednesday, September 29, 2010 - link
It boils down to write amplification. I'm working on an article now to quantify exactly how low SandForce's WA is in comparison to other controller makers using methods similar to what you've suggested. In the case of the IBIS I'm simply trying to confirm whether or not the background garbage collection works. In this case I'm writing 100% random data sequentially across the entire drive using iometer, then peppering it with 100% random data randomly across the entire drive for 20 minutes. HDTach is simply used to measure write latency across all LBAs.I haven't seen any issues with SF drives not TRIMing properly when faced with random data. I will augment our HDTach TRIM test with another iometer pass of random data to see if I can duplicate the results.
Take care,
Anand
jwilliams4200 - Wednesday, September 29, 2010 - link
What I would like to see is SSDs with a standard mini-SAS2 connector. That would give a bandwidth of 24 Gbps, and it could be connected to any SAS2 HBA or RAID card. Simple, standards-compliant, and fast. What more could you want?Well, inexpensive would be nice. I guess putting a 4x SAS2 interface in an SSD might be expensive. But at high volume, I would guess the cost could be brought down eventually.
LancerVI - Wednesday, September 29, 2010 - link
I found the article to be interesting. OCZ introducing a new interconnect that is open for all is interesting. That's what I took from it.It's cool to see what these companies are trying to do to increase performance, create new products and possibly new markets.
I think most of you missed the point of the article.
davepermen - Thursday, September 30, 2010 - link
problem is, why?there is NO use of this. there are enough interconnects existing. enough fast, they are, too. so, again, why?
oh, and open and all doesn't matter. there won't be any products besides some ocz stuff.
jwilliams4200 - Wednesday, September 29, 2010 - link
Anand:After reading your response to my comment, I re-read the section of your article with HD Tach results, and I am now more confused. There are 3 HD Tach screenshots that show average read and write speeds in the text at the bottom right of the screen. In order, the avg read and writes for the 3 screenshots are:
read 201.4
write 233.1
read 125.0
write 224.3
"Note that peak low queue-depth write speed dropped from ~233MB/s down to 120MB/s"
read 203.9
write 229.2
I also included your comment from the article about write speed dropping. But are the read and write rates from HD Tach mixed up?
Anand Lal Shimpi - Wednesday, September 29, 2010 - link
Ah good catch, that's a typo. On most drives the HDTach pass shows impact to write latency, but on SF drives the impact is actually on read speed (the writes appear to be mostly compressed/deduped) as there's much more data to track recover since what's being read was originally stored in its entirety.Take care,
Anand
jwilliams4200 - Wednesday, September 29, 2010 - link
My guess is that if you wrote incompressible data to a dirty SF drive, that the write speed would be impacted similarly to the impact you see here on the read speed.In other words, the SF drives are not nearly as resilient as the HD Tach write scans show, since, as you say, the SF controller is just compressing/deduping the data that HD Tach is writing. And HD Tach's writes do not represent a realistic workload.
I suggest you do an article revisiting the resiliency of dirty SSDs, paying particular attention to writing incompressible data.
greggm2000 - Wednesday, September 29, 2010 - link
So how will Lightpeak factor into this? Is OCZ working on a Lightpeak implementation of this? One hopes that OCZ and Intel are communicating here..jwilliams4200 - Wednesday, September 29, 2010 - link
The first lightpeak cables are only supposed to be 10 Gbps. A mini-SAS2 cable has four lanes of 6 Gbps for a total of 24 Gbps. lightpeak loses.