NVIDIA’s GeForce GTX 480 and GTX 470: 6 Months Late, Was It Worth the Wait?
by Ryan Smith on March 26, 2010 7:00 PM EST- Posted in
- GPUs
Tessellation & PhysX
We’ll kick off our in-depth look at the performance of the GTX400 series with Tessellation and PhysX. These are two of the biggest features that NVIDIA is pushing with the GTX400 series, with tessellation in particular being the major beneficiary of NVIDIA’s PolyMorph Engine strategy.
As we covered in our GF100 Recap, NVIDIA seeks to separate themselves from AMD in spite of the rigid feature set imposed by DirectX 11. Tessellation is one of the ways they intend to do that, as the DirectX 11 standard leaves them plenty of freedom with respect to tessellation performance. To accomplish this goal, NVIDIA needs significantly better tessellation performance, which has lead to them having 14/15/16 tesselators through having that many PolyMorph Engines. With enough tessellation performance NVIDIA can create an obvious image quality improvement compared to AMD, all the while requiring very little on the part of developers to take advantage of this.
All things considered, NVIDIA’s claim of having superior tessellation performance is one of the easiest claims to buy, but all the same we’ve gone ahead and attempted to confirm it.
Our first tessellation test is the newly released Unigine Heaven 2.0 benchmark, which was released a few days ago. 2.0 added support for multiple levels of tessellation (with 1.0 having earned a reputation of using extreme levels of tessellation), which allows us to look at tessellation performance by varying tessellation levels. If the GTX 480’s tessellation capabilities are several times faster than the Radeon 5870’s as NVIDIA claims, then it should better handle the increased tessellation levels.
Since Heaven is a largely a synthetic benchmark at the moment (the DX11 engine isn’t currently used in any games) we’ll be focusing on the relative performance of cards to themselves in keeping with our editorial policy of avoiding synthetic GPU tests when possible.

Heaven: Moderate & Extreme Tessellation

Heaven has 4 tessellation levels: off, moderate, normal, extreme. For our test we’re using the moderate and extreme modes, comparing the performance of extreme as a percentage of moderate performance.
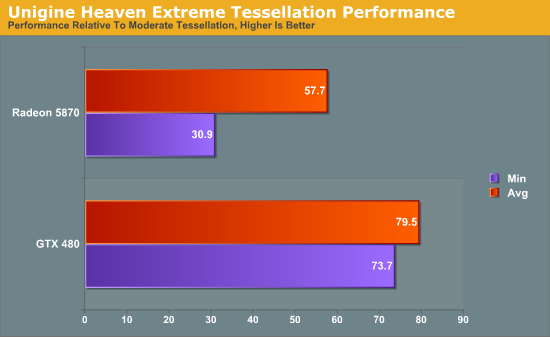
Starting with averages, the GTX 480 keeps 79% of its performance moving from moderate to extreme. On the Radeon 5870 however, the performance drop-off is much more severe, losing 42% of its performance to bring it down to 58%.
The minimum framerates are even more telling. The GTX 480 minimum framerates drop by 26% when switching to extreme tessellation. The Radeon 5870 is much worse off here, bringing in minimum framerates 69% lower when using extreme tessellation. From these numbers it’s readily apparent that the GTX 480 is much more capable of dealing with very high tessellation levels than the Radeon 5870 is.
Our second tessellation test is similar in nature, this time taken from one of Microsoft’s DX11 sample programs: Detail Tessellation. Detail Tessellation is a simple scene where tessellation plus displacement mapping is used to turn a flat rock texture in to a simulated field of rocks by using tessellation to create the geometry. Here we measure the average framerate at different tessellation factors (7 and 11) and compare the framerate at the higher tessellation factor to the lower tessellation factor.

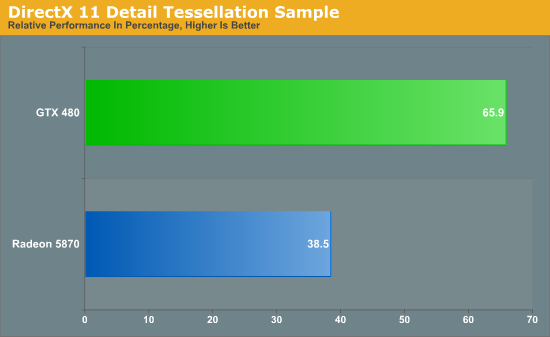
Looking at just the averages (the framerate is rather solid) we see that the GTX 480 retains 65% of its performance moving from factor 7 to factor 11. The Radeon 5870 on the other hand only retains 38% of its performance. Just as what we saw in Unigine, the GTX 480 takes a much lighter performance hit from higher tessellation factors than the Radeon 5870 does, driving home the point that the GTX 480 has a much more powerful tessellator.
With the results of these tests, there’s no reason to doubt NVIDIA’s claims about GF100’s tessellation abilities. All the data we have points GF100/GTX 480 being much more powerful than the Radeon 5000 series when it comes to tessellation.
But with that said, NVIDIA having a more powerful tessellator doesn’t mean much on its own. Tessellation is wholly dependent on game developers to make use of it and to empower users to adjust the tessellation levels. Currently every DX11 game using tessellation uses a fixed amount of it, so NVIDIA’s extra tessellation abilities are going unused. This doesn’t mean that tessellation will always be used like this, but it means things have to change, and counting on change is a risky thing.
NVIDIA’s superior tessellation abilities will require that developers offer a variable degree of tessellation in order to fully utilize their tessellation hardware, and that means NVIDIA needs to convince developers to do the extra work to implement this. At this point there’s no way for us to tell how things will go: NVIDIA’s superior tessellation abilities could be the next big thing that seperates them from AMD like they’re shooting for, or it could be the next DirectX 10.1 by being held back by weaker hardware. Without some better sense of direction on the future use of tessellation, we can’t make any recommendations based on NVIDIA’s greater tessellation performance.
Moving on we have PhysX, NVIDIA’s in-house physics simulation middleware. After picking up PhysX and its developer AGEIA in 2008, NVIDIA re-implemented PhysX hardware acceleration as a CUDA application, allowing their GPUs to physics simulations in hardware. NVIDIA has been pushing it on developers and consumers alike with limited success, and PhysX only finally had a breakthrough title last year with the critically acclaimed Batman: Arkham Asylum.
With Fermi’s greatly enhanced compute abilities, NVIDIA is now pushing the idea that PhysX performance will be much better on Fermi cards, allowing developers to use additional and more complex physics actions than ever before. In particular, with the ability to use concurrent kernels and the ability to do fast context switching, PhysX should have a reduced degree of overhead on Fermi hardware than it did on GT200/G80 hardware.
To put this idea to the test, we will be using the Batman: Arkham Asylum benchmark to measure PhysX performance. If PhysX has less overhead on Fermi hardware then the framerate hit on the GTX 480 from enabling PhysX effects should be lower than the framerate hit on the GTX 285. For this test we are running at 2560x1600, comparing performance between PhysX being disabled and when it’s set on High.
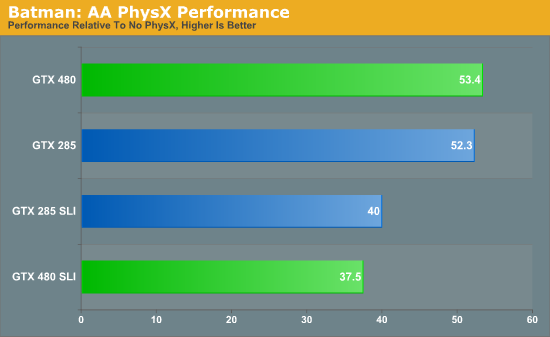
If PhysX has less overhead on Fermi hardware, Batman is not the game to show it. On both the GTX 480 and the GTX 285, the performance hit on a percentage basis for enabling PhysX is roughly 47%. The GTX 480 may be faster overall, but it takes the same heavy performance hit for enabling PhysX. The SLI cards fare even worse here: the performance hit for enabling PhysX is 60% on both the GTX 480 SLI and the GTX 285 SLI.
PhysX unquestionably has the same amount of overhead on the GTX 480 as it does the GTX 285. If PhysX is going to take up less overhead, then from what we can gather it either will be a benefit limited to PhysX 3, or will require future PhysX 2.x updates that have yet to be delivered.
Or second PhysX test is a more generalized look at PhysX performance. Here we’re using NVIDIA’s Raging Rapids tech demo to measure PhysX performance. Raging Rapids is a water simulation demonstration that uses PhysX to simulate waves, waterfalls, and more. Here we are measuring the framerate in the demo’s benchmark mode.
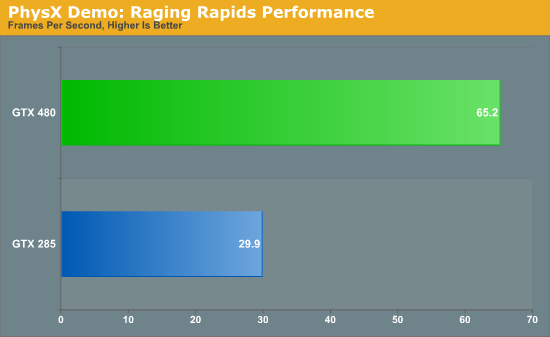
Overall the Raging Rapids benchmark gives us mixed results. Out of all of the benchmarks we have run on the GTX 480, this is one of the larger performance jumps over the GTX 285. On the other hand, once we compensate for the GTX 480’s additional shaders, we end up with a result only around 10% faster than a strict doubling in performance. This is a sign of good scaling, but it isn’t a sign that the GTX 480 is significantly faster than the GTX 285 due to more efficient use of compute resources. Just having all of this extra compute power is certainly going to make a difference overall, but on an architectural level the GTX 480 doesn’t look to be significantly faster at PhysX than the GTX 285 on a per-clock/per-shader basis.








196 Comments
View All Comments
henrikfm - Tuesday, March 30, 2010 - link
Now it would be easier to believe only idiots buy ultra-high end PC hardware parts.ryta1203 - Tuesday, March 30, 2010 - link
Is it irresponsible to use benchmarks desgined for one card to measure the performance of another card?Sadly, the "community" tries to hold the belief that all GPU architectures are the same, which is of course not true.
The N-queen solver is poorly coded for ATI GPUs, so of course, you can post benchmarks that say whatever you want them to say if they are coded that way.
Personally, I find this fact invalidates the entire article, or at least the "compute" section of this article.
Ryan Smith - Wednesday, March 31, 2010 - link
One of the things we absolutely wanted to do starting with Fermi is to include compute benchmarks. It's going to be a big deal if AMD and NVIDIA have anything to say about it, and in the case of Fermi it's a big part of the design decision.Our hope was that we'd have some proper OpenCL/DirectCompute apps by the time of the Fermi launch, but this hasn't happened. So our decision was to go ahead with what we had, and to try to make it clear that our OpenCL benchmarks were to explore the state of GPGPU rather than to make any significant claims about the compute capabilities of NVIDIA or AMD's GPUs. We would rather do this than to ignore compute entirely.
It sounds like we didn't make this clear enough for your liking, and if so I apologize. But it doesn't make the results invalid - these are OpenCL programs and this is what we got. It just doesn't mean that these results will carry over to what a commercial OpenCL program may perform like. In fact if anything it adds fuel to the notion that OpenCL/DirectCompute will not be the great unifier we had hoped for them to be if it means developers are going to have to basically write paths optimized around NVIDIA and AMD's different shader structure.
ryta1203 - Tuesday, March 30, 2010 - link
The compute section of this article is just nonsense. Is this guy a journalist? What does he know about programming GPUs?Firen - Tuesday, March 30, 2010 - link
Thanks for this comprehensive review, it covers some very interesting topics betwen Team Green and Team Red.Yet, I agree with one of the comments here, you missed how easy that ATI 5850 and 5870 can be overlocked thanks to their lite design, a 5870 can easily deliver more or less the same performance as a 480 card while still running cooler and consumes less power..
Some people might point out that our new 'champion' card can be overlocked as well..that's true..however, doesn't it feel terrifying to have a graphic card running hotter than boiling water!
Fulle - Tuesday, March 30, 2010 - link
I wonder what kind of overclocking headroom the 470 has.... since someone with a 5850 can easily bump the voltage up a smidge, and get about a 30% overclock with minimal effort... people who tinker can usually safely reach about 1GHz core, for about a 37% overclock.Unless the 470 has a bit of overclocking headroom, someone with a 5850 could easily overclock to have superior performance, lower heat, lower noise, and lower power consumption.
After all these months and months of waiting, Nvidia has basically released a few products that ATI can defeat by just binning their current GPUs and bumping up the clockspeed? *sigh* I really don't know who would buy these cards.
Shadowmaster625 - Tuesday, March 30, 2010 - link
You're being way too kind to Nvidia. Up to 50% more power consumption for a very slight (at best) price/performance advantage? This isnt a repeat of the AMD/Intel thing. This is a massive difference in power consumption. We're talking about approximately $1 a year per hour a week of gaming. If you game for 20 hours a week, expect to pay $20 a year more for using the GTX470 vs a 5850. May as well add that right to the price of the card.But the real issue is what happens to these cards when they get even a modest coating of dust in them? They're going to detonate...
Even if the 470 outperformed the 5850 by 30%, I dont think it would be worth it. I cant stand loud video cards. It is totally unacceptable to me. I again have to ask the question I find myself asking quite often: what kind of world are you guys living in? nVidia should get nothing more than a poop-in-a-box award for this.
jujumedia - Wednesday, March 31, 2010 - link
with those power draws and the temps it reaches for daily operation i see gpu failure rates high on the gtx 480 and 470 as they are already faulty from the fab lab. Ill stick with ATI for 10 fps less.njs72 - Wednesday, March 31, 2010 - link
I been holding on for months to see what Fermi would bring in the world of GPUs. After reading countless reviews of this card i dont think its a justifyable upgrade for my gtx260. I mean yeah the performance is much higher but in most reviews of benchmarks with games like Crysis this card barely wins against the 5870, but buying this card i would need to upgrade the psu and posibly a new case for ventilation. I keep loading up Novatechs website and and almost adding a 5870 to the basket, and not pre ordering gtx480 like i was intending. What puts me off more than anything with the new nvidia card is its noise and temps. I cant see this card living for very long.Ive been a nvidia fan ever since the the first geforce card came out, which i still have tucked away in a draw somewhere. I find myself thinking of switching to ATI, but read too many horror stories about their driver implementation that puts me off. Maybe i should just wait for Nvidia to refresh its new card and keep hold of my 260 for a bit longer. i really dont know :-(
Zaitsev - Wednesday, March 31, 2010 - link
There is an error with the Bad Company 2 image mouse overs for the GTX 480. I think the images for 2xAA and 4xAA have been mixed up. 2xAA clearly has more AA than the 4xAA image.Compare GTX 480 2x with GTX 285 4x and they look very similar. Also compare 480 4x with 285 2x.
Very nice article, Ryan! I really enjoyed the tessellation tests. Keep up the good work.