AMD Core Counts and Bulldozer: Preparing for an APU World
by Anand Lal Shimpi on November 30, 2009 12:00 AM EST- Posted in
- CPUs
The New Way to Count Cores
Henceforth AMD is referring to the number of integer cores on a processor when it counts cores. So a quad-core Zambezi is made up of four integer cores, or two Bulldozer modules. An eight-core would be four Bulldozer modules.

A hypothetical quad-core Bulldozer. Presumably the L3 cache would be shared by both modules.
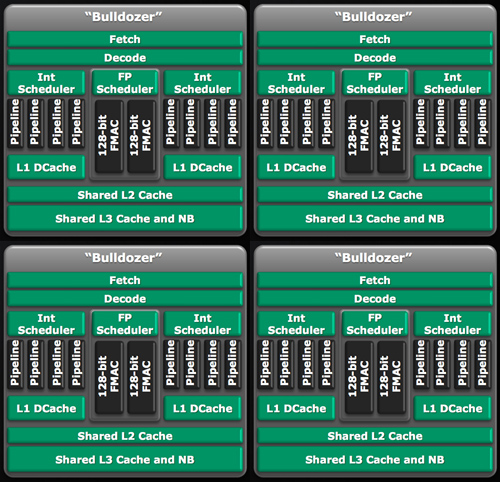
A hypothetical eight-core Bulldozer. Presumably the L3 cache would be shared by all four modules.
It's a distinct shift from AMD's (and Intel's) current method of counting cores. A quad-core Phenom II X4 is literally four Phenom II cores on a single die, if you disabled three you would be left with a single core Phenom II. The same can't be said about a quad-core Bulldozer. The smallest functional block there is a module, which is two cores according to AMD.
Better than Hyper Threading?
Intel doesn't take, at least today, quite aggressive of a step towards multithreading. Nehalem uses SMT to send two threads to a single core, resulting in as much as a 30% increase in performance:
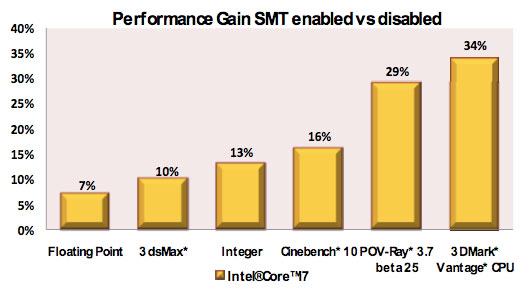
The added die area to enable HT on Nehalem is very small, far less than 5%.
AMD claims that the performance benefit from the second integer core on a single Bulldozer module is up to 80% on threaded code. That's more than what AMD could get through something like Hyper Threading, but as we've recently found out the impact to die size is not negligible. It really boils down to the sorts of workloads AMD will be running on Bulldozer. If they are indeed mostly integer, then the performance per die area will be quite good and the tradeoff worth it. Part of the integer/FP balance does depend on how quickly the world embraces computing on the GPU however...
According to AMD's roadmaps, Zambezi will use either 4 or 8 Bulldozer cores (that's 2 or 4 modules). The quad-core Zambezi should have roughly 10 - 35% better integer performance than a similarly clocked quad-core Phenom II. An eight-core Zambezi will be a threaded monster.
No GPU, for Now
The first APU from AMD will be Llano, but based on existing Phenom II cores. The move to a new manufacturing process combined with the first monolithic CPU/GPU is enough to do at once, there's no need to toss in a brand new microarchitecture at the same time.

AMD did add that eventually, in a matter of 3 - 5 years, most floating point workloads would be moved off of the CPU and onto the GPU. At that point you could even argue against including any sort of FP logic on the "CPU" at all. It's clear that AMD's design direction with Bulldozer is to prepare for that future.
In recent history AMD's architectural decisions have predicted, earlier than Intel, where the the microprocessor industry was headed. The K8 embraced 64-bit computing, a move that Intel eventually echoed some years later. Phenom was first to migrate to the 3 level cache hierarchy that we have today, with private L2 caches. Nehalem mimicked and improved on that philosophy. Bulldozer appears to be similarly ahead of its time, ready for world where heterogenous CPU/GPU computing is commonplace. I wonder if we'll see a similar architecture from Intel in a few years.








94 Comments
View All Comments
Alberto - Tuesday, December 1, 2009 - link
You are right.The eight core Sandy Bridge will have over 200 Gflops Double Precision with a power budget of 130W in 32nm and 95W in 22nm.
In these conditions the "dream" to throw away the Fp unit from the CPU it's only a Nvidia desire.....to survive.
gruffi - Sunday, December 6, 2009 - link
Give me your calculation please. I see Sandy Bridge nowhere near 200 GFLOPS in DP.Sandy Bridge may have up to 8 cores/16 threads (the known die shot shows only 4 cores), probably clocked around 3 GHz.
4 DP (AVX/256-bit) * 1 op/cycle (no FMA) * 8 cores * 3 GHz = 96 GFLOPS
OTOH, AMD may have twice as much FP throughput with "Interlagos" (8 modules/16 cores/16 threads) if we assume similar clock rates.
4 DP (AVX/256-bit) * 2 ops/cycle (FMA4) * 8 modules * 3 GHz = 192 GFLOPS
psychobriggsy - Tuesday, December 1, 2009 - link
That certainly beats AMD's ~100GFLOPS in double precision from an 8-core Bulldozer.Calculation: 3GHz * 2 (FMA) * 2 (units) * 2 DP (128-bit unit) * 4 (modules).
Clearly AMD are providing enough CPU power for OpenCL, etc, to run "well", but if you need "serious" power then you'll plug in an RV900 series GPU that will probably try to get near 1TFLOP in DP in the same timeframe. With OpenCL, the exact same code will run (AMD's OpenCL driver can switch between CPU and GPU without any application changes).
epobirs - Tuesday, December 1, 2009 - link
It looks like AMD is engaging in another word of words instead of performance. Remember when they claimed ownership of what was or was not 'dual core' and 'quad core?' While AMD declared the C2Q line as 'not true quad-core' the Intel product was actually shipping and available for use a year before AMD's 'true' chips came out with less performance and some serious bugs for added enjoyment.This gets tiresome to the point where I hold AMD in great suspicion when they lead with a new official vocabulary instead of the product and how it actually performs.
I truly don't give a damn about your modules, AMD. Take your new architecture and define the smallest portion that could be sold as a discrete product to run a PC. That is a core. It doesn't matter how many threads it runs. It is a core. If we cannot have meaningful definition to which all companies adhere, the conversation is dead and all that remains is useless PR blather.
Nehemoth - Tuesday, December 1, 2009 - link
Well said. At the end of the day users don't care about the elegance of the architecture they'll care about performance, performance per watt, etc, etc.PD : Where is the Z Ram technology they're licensed back time ago for the Cache Memory?
What about the license for XDR from Rambus?
At less for some servers should have a value.
Nehemoth - Tuesday, December 1, 2009 - link
Well said. At the end of the day users don't care about the elegance of the architecture they'll care about performance, performance per watt, etc, etc.PD : Where is the Z Ram technology they're licensed back time ago for the Cache Memory?
What about the license for XDR from Rambus?
At less for some servers should have a value.
Milleman - Monday, November 30, 2009 - link
It's good to see that the existance of AMD is healthy for the competition, progress and innovation. The existance of AMD is even good for the Intel fan-boys. The Inte CPU's wouldent be half that fast today, if there wasn't any competition on the market.jmurbank - Monday, November 30, 2009 - link
An AMD representative said that the picture you provided is one core, but it has two integer units. These two integer units are hardware basis of a similar feature of Intel's Hyperthreading. The following picture is a dual core.http://images.anandtech.com/reviews/cpu/amd/Bulldo...">http://images.anandtech.com/reviews/cpu/amd/Bulldo...
The four core is the following image.
http://images.anandtech.com/reviews/cpu/amd/Bulldo...">http://images.anandtech.com/reviews/cpu/amd/Bulldo...
This is all assuming the Bulldozer core is for their enthusiasts or high end setups. For the low end, these pictures will not include two integer units. Though it all depends what AMD has in store for the microcode for their Bulldozer core because it can be one way and other or it can be both that can take advantage of both features by including a switch in the BIOS or software, but it is too soon.
Milleman - Monday, November 30, 2009 - link
Looks like the AMD CPU's are slowly getting structures "borrowed" from ATI GPU's, which is very interrresting. The traditional CPU strukture from the seventies are on the way out. The future looks really exciting!tatertot - Monday, November 30, 2009 - link
AMD marketing made a mistake (Fruehe, on his blog) when referring to an AMD engineering claim made by Moore.The claim is on slide 4:
http://www.amd.com.cn/chcn/assets/content_type/Dow...">http://www.amd.com.cn/chcn/assets/conte...loadable...
80% more throughput (integer work) for 50% more (core) area.
Fruehe LOLed this into 80% more performance for 5% more area (ooops!), and now this meme has taken hold.
It's wrong. Each module is 50% larger to get 80% more integer throughput, and even adding in all the "uncore" portions on a chip does not get this number anywhere NEAR 5%. (The uncore is nowhere near 10x the area of all the core area combined)