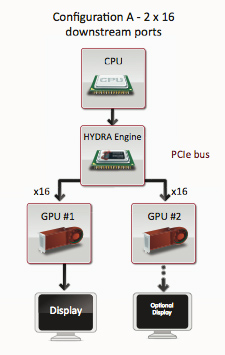
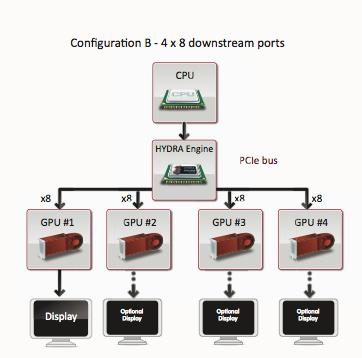
Lucid Hydra 200: Vendor Agnostic Multi-GPU, Available in 30 Days
by Anand Lal Shimpi on September 22, 2009 5:00 PM EST- Posted in
- GPUs
A year ago Lucid announced the Hydra 100: a physical chip that could enable hardware multi-GPU without any pesky SLI/Crossfire software, game profiles or anything like that.
At a high level what Lucid's technology does is intercept OpenGL/DirectX commands from the CPU to the GPU and load balance them across any number of GPUs. The final buffers are read back by the Lucid chip and sent to primary GPU for display.
The technology sounds flawless. You don't need to worry about game profiles or driver support, you just add more GPUs and they should be perfectly load balanced. Even more impressive is Lucid's claim that you can mix and match GPUs of different performance levels. For example you could put a GeForce GTX 285 and a GeForce 9800 GTX in parallel and the two would be perfectly load balanced by Lucid's hardware; you'd get a real speedup. Eventually, Lucid will also enable multi-GPU configurations from different vendors (e.g. one NVIDIA GPU + one AMD GPU).

At least on paper, Lucid's technology has the potential to completely eliminate all of the multi-GPU silliness we've been dealing with for the past several years. Today, Lucid is announcing the final set of hardware that will be shipping within the next ~30 days.

The MSI Big Bang, a P55 motherboard with Lucid's Hydra 200
It's called the Hydra 200 and it will first be featured on MSI's Big Bang P55 motherboard. Unlike the Hydra 100 we talked about last year, 200 is built on a 65nm process node instead of 130nm. The architecture is widely improved thanks to much more experience with the chip on Lucid's part.
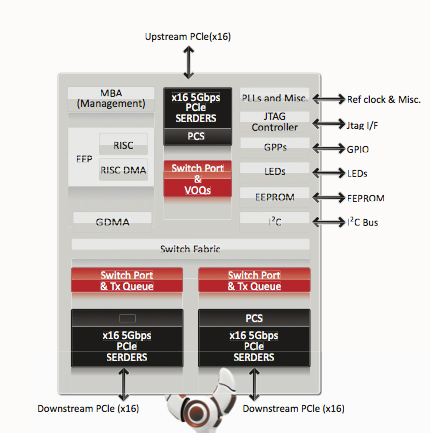
There are three versions of the Hydra 200: the LT22114, the LT22102 and the LT22114. The only difference between the chips are the number of PCIe lanes. The lowest end chip has a x8 connection to the CPU/PCIe controller and two x8 connections to GPUs. The midrange LT22102 has a x16 connection to the CPU and two x16 connections for GPUs. And the highest end solution, the one being used on the MSI board, has a x16 to the CPU and then a configurable pair of x16s to GPUs. You can operate this controller in 4 x8 mode, 1 x16 + 2 x8 or 2 x16. It's all auto sensing and auto-configurable. The high end product will be launching in October, with the other two versions shipping into mainstream and potentially mobile systems some time later.
Lucid wouldn't tell us the added cost on a motherboard but Lucid gave us the guidance of around $1.50 per PCIe lane. The high end chip has 48 total PCIe lanes, which puts the premium at $72. The low end chip has 24 lanes, translating into a $36 cost for the Hydra 200 chip. Note that since the Hydra 200 has an integrated PCIe switch, there's no need for extra chips on the motherboard (and of course no SLI licensing fees). The first implementation of the Hydra 200 will be on MSI's high end P55 motherboard, so we can expect prices to be at the upper end of the spectrum. With enough support, we could see that fall into the upper mainstream segment.
Lucid specs the Hydra 200 at a 6W TDP.
Also unlike last year, we actually got real seat time with the Hydra 200 and MSI's Big Bang. Even better: we got to play on a GeForce GTX 260 + ATI Radeon HD 4890 running in multi-GPU mode.

Of course with two different GPU vendors, we need Windows 7 to allow both drivers to work at the same time. Lucid's software runs in the background and lets you enable/disable multi-GPU mode:
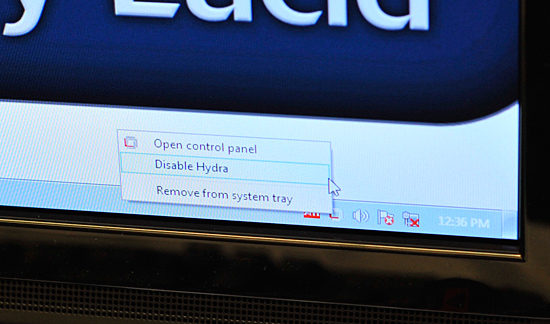
If for any reason Lucid can't run a game in multi-GPU mode, it will always fall back to working on a single GPU without any interaction from the end user. Lucid claims to be able to accelerate all DX9 and DX10 games, although things like AA become easier in DX10 since all hardware should resolve the same way.

NVIDIA and ATI running in multi-GPU mode on a single system

There are a lot of questions about performance and compatibility, but honestly we can't say much on that until we get the hardware ourselves. We were given some time to play with the system and can say that it at least works.

Lucid only had two games installed on the cross-vendor GPU setup: Bioshock and FEAR 2. There are apparently more demos at the show floor, we'll try and bring more impressions from IDF later this week.








94 Comments
View All Comments
scarywoody - Tuesday, September 22, 2009 - link
Errr, so you can run 2x16 with lucid and a socket 1156 mobo? if that's the case it's an interesting move and would explain a bit about why you can only run 2x8 or 1x16 with current p55 boards.Denithor - Wednesday, September 23, 2009 - link
I was wondering the exact same thing - how do you get support for like 32 lanes on a board where there are only 16 lanes total hardwired into the cpu?Triple Omega - Wednesday, September 23, 2009 - link
You don't. Just like the Nvidia Nforce splitter it is limited to the bandwidth coming from the CPU(x16 or x8 with these) and only creates extra overhead "creating" more lanes.Only difference is that the Nvidia solution is completely useless as all it does is create more overhead, while this isn't as it has more then just a splitter function.
GeorgeH - Wednesday, September 23, 2009 - link
Because this isn't SLI or Crossfire. :)At a very simple level, this is essentially a DIY video card that you plug your own Frankenstein GPU combos into. For example, instead of the "old way" of slapping two 4890's together in Crossfire to have them render alternate frames (which means you "need" an x16 connection for each card), here you plug two 4850s and a 4770 into the Hydra to get one 5870 (minus the DX11) that only requires a single x16 connection.
Now we just need to find out if it works or not.
sprockkets - Tuesday, September 22, 2009 - link
Both cards have a monitor cable attached to them, but you only showed one monitor. Was a dual monitor setup?yakuza78 - Tuesday, September 22, 2009 - link
Taking a look to the pictures you can see both the video cables (one vga and one dvi) go to the monitor, it's just the easiest way to enable both cards, connect them to a multi input monitor.jimhsu - Tuesday, September 22, 2009 - link
Maybe I don't know that much about parallelization, but isn't compartmentalizing complicated scenes a very difficult problem?For example, most modern games have surfaces that are at least partially reflective (mirrors, metal, water, etc). Would that not mean that the reflecting surface and the object it's reflecting needs to be rendered on the same GPU? Say you have many such surfaces (a large chrome object). Isn't it a computationally hard problem to decide which surfaces will be visible to each other surface to effectively split up that workload between GPUs of different performance characteristics without "losing anything", every 1/FPS of a second?
How do they do this exactly?
emboss - Saturday, September 26, 2009 - link
This is pretty much the problem, yes. Modern graphics engines do a *lot* of render-to-texture stuff, which is the crux of the problem. If one operation writes to the texture on one GPU, and then the other operation writes to the texture on the other GPU, there's a delay while the texture is transferred between GPUs. Minimizing these transfers is the big problem, and it's basically impossible to do so since there's no communication between the game and the driver as to how the texture is going to be used in the future.SLI/CrossFire profiles deal with this by having the developers at NV/ATI sit down and analyse the operations the game is doing. They then write up some rules from these results, specific to that game, on how to distribute the textures and operations.
Lucid are going to run into the same problem. Maybe their heuristics for dividing up the work will be better than NV/ATI's, maybe they won't. But the *real* solution is to fix the graphics APIs to allow developers to develop for multiple GPUs in the same way that they develop for multiple CPUs.
andrihb - Tuesday, September 29, 2009 - link
Wait.. How does it work now? Do they have to develop a different renderering engine for each GPU or GPU family? I thought APIs like DX actually took care of that shit and standardized everything :S.emboss - Tuesday, September 29, 2009 - link
DirectX and OpenGL provide a standard *software* interface. The actual hardware has a completely different (and more general) structure. The drivers take the software commands and figures out what the hardware needs to do to draw the triangle or whatever. The "problem" is that DirectX and OpenGL are too general, and the driver has to allow for all sorts of possibilities that will probably never occur.So, there's a "general" path in the drivers. This is sort of a reference implementation that follows the API specification as closely as possible. Obviously there's one of these per family. This code isn't especially quick because of having to take into account all the possibilities.
Now, if a game is important, NV and ATI driver developers will either analyze the calls the game makes, or sit down and talk directly with the developers. From this, they will program up a whole lot of game-specific optimizations. Usually it'll be at the family level, but it's not unheard of for specific models to be targetted. Sometimes these optimizations are safe for general use and speed up everything. These migrate back into the general path.
Much more often, these optimizations violate the API spec in some way, but don't have any effect on this specific game. For example, the API spec might require that a function does a number of things, but in the game only a portion of this functionality is required. So, a game-specific implementation of this function is made that only does the bare minimum required. Since this can break other software that might rely on the removed functionality, these are put into a game-specific layer that sits on top of the general layer and is only activated when the game is detected.
This is partially why drivers are so huge nowadays. There's not just one driver, but a reference implementation plus dozens or even hundreds of game- and GPU-specific layers.
So from the game developer point of view, yes DirectX and OpenGL hide all the ugly details. But in reality, all is does is shift the work from the game developers to the driver developers.