The SSD Anthology: Understanding SSDs and New Drives from OCZ
by Anand Lal Shimpi on March 18, 2009 12:00 AM EST- Posted in
- Storage
New vs Used SSD Performance
We begin our look at how the overhead of managing pages impacts SSD performance with iometer. The table below shows iometer random write performance; there are two rows for each drive, one for “new” performance after a secure erase and one for “used” performance after the drive has been well used.
| 4KB Random Write Speed | New | "Used" |
| Intel X25-E | 31.7 MB/s | |
| Intel X25-M | 39.3 MB/s | 23.1 MB/s |
| JMicron JMF602B MLC | 0.02 MB/s | 0.02 MB/s |
| JMicron JMF602Bx2 MLC | 0.03 MB/s | 0.03 MB/s |
| OCZ Summit | 12.8 MB/s | 0.77 MB/s |
| OCZ Vertex | 8.2 MB/s | 2.41 MB/s |
| Samsung SLC | 2.61 MB/s | 0.53 MB/s |
| Seagate Momentus 5400.6 | 0.81 MB/s | - |
| Western Digital Caviar SE16 | 1.26 MB/s | - |
| Western Digital VelociRaptor | 1.63 MB/s | - |
Note that the “used” performance should be the slowest you’ll ever see the drive get. In theory, all of the pages are filled with some sort of data at this point.
All of the drives, with the exception of the JMicron based SSDs went down in performance in the “used” state. And the only reason the JMicron drive didn’t get any slower was because it is already bottlenecked elsewhere; you can’t get much slower than 0.03MB/s in this test.
These are pretty serious performance drops; the OCZ Vertex runs at nearly 1/4 the speed after it’s been used and Intel’s X25-M can only crunch through about 60% the IOs per second that it did when brand new.
So are SSDs doomed? Is performance going to tank over time and make these things worthless?
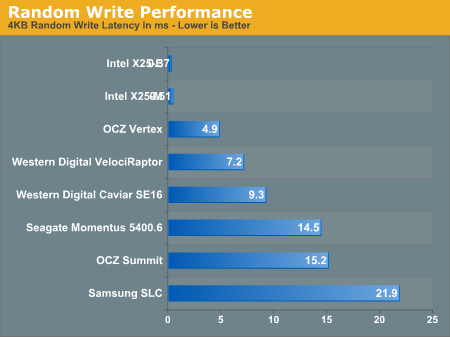
"Used" SSD performance vs. conventional hard drives.
Pay close attention to the average write latency in the graph above. While Intel’s X25-M pulls an extremely fast sub-0.3ms write latency normally, it levels off at 0.51ms in its used mode. The OCZ Vertex manages a 1.43ms new and 4.86ms used. There’s additional overhead for every write but a well designed SSD will still manage extremely low write latencies. To put things in perspective, look at these drives at their worst compared to Western Digital’s VelociRaptor.The degraded performance X25-M still completes write requests in around 1/8 the time of the VelociRaptor. Transfer speeds are still 8x higher as well.
Note that not all SSDs see their performance drop gracefully. The two Samsung based drives perform more like hard drives here, but I'll explain that tradeoff much later in this article.
How does this all translate into real world performance? I ran PCMark Vantage on the new and used Intel drive to see how performance changed.
| PCMark Overall Score | New | "Used" | % Drop |
| Intel X25-M | 11902 | 11536 | 3% |
| OCZ Summit | 10972 | 9916 | 9.6% |
| OCZ Vertex | 11253 | 9836 | 14.4% |
| Samsung SLC | 10143 | 9118 | 10.1% |
| Seagate Momentus 5400.6 | 6817 | - | - |
| Western Digital VelociRaptor | 7500 | - | - |
The real world performance hit varies from 0 - 14% depending on the drive. While the drives are still faster than a regular hard drive, performance does drop in the real world by a noticeable amount. The trim command would keep the drive’s performance closer to its peak for longer, but it would not have prevented this from happening.
| PCMark Vantage HDD Test | New | "Used" | % Drop |
| Intel X25-M | 29879 | 23252 | 22% |
| JMicron JMF602Bx2 MLC | 11613 | 11283 | 3% |
| OCZ Summit | 25754 | 16624 | 36% |
| OCZ Vertex | 20753 | 17854 | 14% |
| Samsung SLC | 17406 | 12392 | 29% |
| Seagate Momentus 5400.6 | 3525 | - | |
| Western Digital VelociRaptor | 6313 | - |
HDD specific tests show much more severe drops, ranging from 20 - 40% depending on the drive. Despite the performance drop, these drives are still much faster than even the fastest hard drives.








250 Comments
View All Comments
strikeback03 - Thursday, March 19, 2009 - link
If you get Newegg's specials, one of the codes is for the 30GB for $103 with a $20MIR, so $83 with shipping if the rebate comes through. At the size I would want (~120) the Super Talent undercuts the OCZ slightly.Does anyone know if you can install the firmware of one maker to another maker's SSD? For example, assuming both the Ultradrive ME and the Vertex use the same Indilinx controller, and say Super Talent chose to release it with the firmware which optimizes for higher sequential speeds, would the user be able to choose the firmware which optimizes for less latency?
Testtest - Wednesday, March 18, 2009 - link
Ah, no editing?!A-Data's "300 plus" SSD also uses the Indilinx controller.
vailr - Wednesday, March 18, 2009 - link
"The Anatomy of a SSD" should instead read: "The Anatomy of an SSD"Flunk - Wednesday, March 18, 2009 - link
Yes, because S is a vowel...abudd - Wednesday, March 18, 2009 - link
Assuming SSD = "es-es-dee" then "an SSD" is right. If it *sounds* like a vowel, use "an".JarredWalton - Wednesday, March 18, 2009 - link
Yes, *but* SSD could also be read as "Solid State Drive" instead of "ess ess dee", in which case you would say "a SSD". I tend to read it as "ess ess dee", but Anand thinks of those letters as "Solid State Drive".Potato, potato, tomato, tomato... let's call the whole thing off!
Azsen - Thursday, March 19, 2009 - link
When reading acronyms you're supposed to think of them as the letters, i.e. when you see RAM, you think "ram" straight off not Random Access Memory. When you see "IBM" you think "eye bee emm" not International Business Machines etc etc. It would take ages to read an article if you had to stop and think out all the full wording of acronyms as you're reading them.I'm going with the correction of "Anatomy of an SSD". Correct English fullstop.
JarredWalton - Thursday, March 19, 2009 - link
By your comment, you suggest two different things, and that's really okay. That was my point: when you see "RAM" you probably thing "ram" as in the animal... not "Are A Em". You say "a RAM stick" not "an RAM stick". I'd guess most people think of SATA as "Ess A Tee A", but if you talk to most computer techs that are in the know, it's "say-te" so you would say "a SATA drive".And you know, I'm sure plenty of people will agree with the correct way of saying SATA, and that's perfectly okay. English really is a very flexible thing - particularly in the tech world - and rarely is there an "always right" way of saying things. If Anand wants to say "a SSD" and others want to say "an SSD", I'm not going to try to declare one group or the other correct. They both are, depending on your viewpoint.
"I believe the world is neither black nor white, but only shades of gray."
Pythias - Friday, March 20, 2009 - link
Can't have gray without black and white.7Enigma - Wednesday, March 18, 2009 - link
HAHAHA. What a tool. I love it when people critique grammar.....and get it wrong.