The SSD Anthology: Understanding SSDs and New Drives from OCZ
by Anand Lal Shimpi on March 18, 2009 12:00 AM EST- Posted in
- Storage
The Trim Command: Coming Soon to a Drive Near You
We run into these problems primarily because the drive doesn’t know when a file is deleted, only when one is overwritten. Thus we lose performance when we go to write a new file at the expense of maintaining lightning quick deletion speeds. The latter doesn’t really matter though, now does it?
There’s a command you may have heard of called TRIM. The command would require proper OS and drive support, but with it you could effectively let the OS tell the SSD to wipe invalid pages before they are overwritten.
The process works like this:
First, a TRIM-supporting OS (e.g. Windows 7 will support TRIM at some point) queries the hard drive for its rotational speed. If the drive responds by saying 0, the OS knows it’s a SSD and turns off features like defrag. It also enables the use of the TRIM command.
When you delete a file, the OS sends a trim command for the LBAs covered by the file to the SSD controller. The controller will then copy the block to cache, wipe the deleted pages, and write the new block with freshly cleaned pages to the drive.
Now when you go to write a file to that block you’ve got empty pages to write to and your write performance will be closer to what it should be.
In our example from earlier, here’s what would happen if our OS and drive supported TRIM:
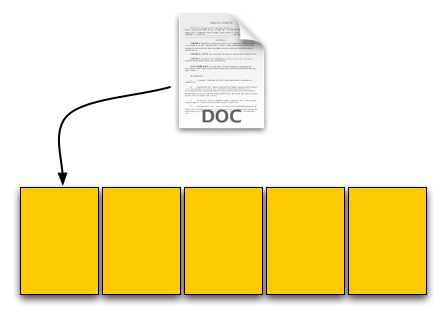
Our user saves his 4KB text file, which gets put in a new page on a fresh drive. No differences here.
Next was a 8KB JPEG. Two pages allocated; again, no differences.
The third step was deleting the original 4KB text file. Since our drive now supports TRIM, when this deletion request comes down the drive will actually read the entire block, remove the first LBA and write the new block back to the flash:

The TRIM command forces the block to be cleaned before our final write. There's additional overhead but it happens after a delete and not during a critical write.
Our drive is now at 40% capacity, just like the OS thinks it is. When our user goes to save his 12KB JPEG, the write goes at full speed. Problem solved. Well, sorta.

While the TRIM command will alleviate the problem, it won’t eliminate it. The TRIM command can’t be invoked when you’re simply overwriting a file, for example when you save changes to a document. In those situations you’ll still have to pay the performance penalty.
Every controller manufacturer I’ve talked to intends on supporting TRIM whenever there’s an OS that takes advantage of it. The big unknown is whether or not current drives will be firmware-upgradeable to supporting TRIM as no manufacturer has a clear firmware upgrade strategy at this point.
I expect that whenever Windows 7 supports TRIM we’ll see a new generation of drives with support for the command. Whether or not existing drives will be upgraded remains to be seen, but I’d highly encourage it.
To the manufacturers making these drives: your customers buying them today at exorbitant prices deserve your utmost support. If it’s possible to enable TRIM on existing hardware, you owe it to them to offer the upgrade. Their gratitude would most likely be expressed by continuing to purchase SSDs and encouraging others to do so as well. Upset them, and you’ll simply be delaying the migration to solid state storage.








250 Comments
View All Comments
strikeback03 - Thursday, March 19, 2009 - link
If you get Newegg's specials, one of the codes is for the 30GB for $103 with a $20MIR, so $83 with shipping if the rebate comes through. At the size I would want (~120) the Super Talent undercuts the OCZ slightly.Does anyone know if you can install the firmware of one maker to another maker's SSD? For example, assuming both the Ultradrive ME and the Vertex use the same Indilinx controller, and say Super Talent chose to release it with the firmware which optimizes for higher sequential speeds, would the user be able to choose the firmware which optimizes for less latency?
Testtest - Wednesday, March 18, 2009 - link
Ah, no editing?!A-Data's "300 plus" SSD also uses the Indilinx controller.
vailr - Wednesday, March 18, 2009 - link
"The Anatomy of a SSD" should instead read: "The Anatomy of an SSD"Flunk - Wednesday, March 18, 2009 - link
Yes, because S is a vowel...abudd - Wednesday, March 18, 2009 - link
Assuming SSD = "es-es-dee" then "an SSD" is right. If it *sounds* like a vowel, use "an".JarredWalton - Wednesday, March 18, 2009 - link
Yes, *but* SSD could also be read as "Solid State Drive" instead of "ess ess dee", in which case you would say "a SSD". I tend to read it as "ess ess dee", but Anand thinks of those letters as "Solid State Drive".Potato, potato, tomato, tomato... let's call the whole thing off!
Azsen - Thursday, March 19, 2009 - link
When reading acronyms you're supposed to think of them as the letters, i.e. when you see RAM, you think "ram" straight off not Random Access Memory. When you see "IBM" you think "eye bee emm" not International Business Machines etc etc. It would take ages to read an article if you had to stop and think out all the full wording of acronyms as you're reading them.I'm going with the correction of "Anatomy of an SSD". Correct English fullstop.
JarredWalton - Thursday, March 19, 2009 - link
By your comment, you suggest two different things, and that's really okay. That was my point: when you see "RAM" you probably thing "ram" as in the animal... not "Are A Em". You say "a RAM stick" not "an RAM stick". I'd guess most people think of SATA as "Ess A Tee A", but if you talk to most computer techs that are in the know, it's "say-te" so you would say "a SATA drive".And you know, I'm sure plenty of people will agree with the correct way of saying SATA, and that's perfectly okay. English really is a very flexible thing - particularly in the tech world - and rarely is there an "always right" way of saying things. If Anand wants to say "a SSD" and others want to say "an SSD", I'm not going to try to declare one group or the other correct. They both are, depending on your viewpoint.
"I believe the world is neither black nor white, but only shades of gray."
Pythias - Friday, March 20, 2009 - link
Can't have gray without black and white.7Enigma - Wednesday, March 18, 2009 - link
HAHAHA. What a tool. I love it when people critique grammar.....and get it wrong.