The RV770 Story: Documenting ATI's Road to Success
by Anand Lal Shimpi on December 2, 2008 12:00 AM EST- Posted in
- GPUs
Re-evaluating Strategy, Creating the RV770 in 2005
Remembering what lead to success rather than the success itself is generally more important, and around 2005 ATI had another R300 moment. What made R300 successful was ATI re-evaluating the way it made GPUs and deciding on something that made sense. At the time, it made sense for ATI to work towards building the biggest chip possible, win at the high end and translate that into better, more competitive products at all other price points. It is worth mentioning that part of R300’s continued success was due to the fact that NVIDIA slipped up royally with the GeForce FX, it was the perfect storm and ATI capitalized. ATI built the biggest chip and NVIDIA had no real answer for some time to come.
Just as Intel bumped into the power wall when it tried to ramp Pentium 4 clock speeds to ridiculous levels, ATI was noticing that GPUs were getting a little too big for comfort. Design cycles were getting longer, die size was growing and financially there were some things that didn’t quite make sense when it came to making these large GPUs.
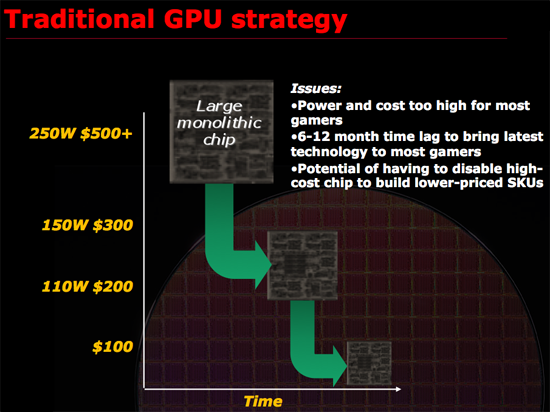
ATI asserted that a very large GPU, without the use of repair structures or harvesting (two techniques I’ll describe in a bit) may only have a 30% yield. That means for every 100 GPUs produced on a single wafer, only 30% of them would be fully functional and could be sold as advertised. Manufacturing these complex circuits is particularly expensive, those fab plants easily cost a couple of billion dollars to build and thus having most of your wafer go to waste isn’t really a good way of running a business.
Thankfully there are ways to improve that crappy 30% yield to a value north of 90%. The first is a technique generally known as repairability. The idea behind repairability is simple: build redundancy into your design. If you have a unit with 10 shader processors, actually build 11 but use one as a spare should there be a defect in any of the remaining processors. The same technique is often used for on-die memory, include additional cells so that a defect in one part of a cache won’t render the entire chip unusable. There are tradeoffs here however, if you build in too much repairability then you run the risk of having a die that’s large but offers no additional performance benefit. If you don’t build in enough repairability then your yield suffers.
Harvesting is another technique that all of you are quite familiar with, although its street name is feature binning. The idea here is that you assume that only a small percentage of the die on a wafer will be completely functional, but instead of throwing away the ones that aren’t fully functional, you disable features and sell them as a lower end part. For example, if your target architecture has 10 shader processors but only 30% of your production will have 10 working shader processors but 50% of the production will have 8 working units you’d sell a model with 10 SPs and a model with 8 SPs, the latter being at a reduced cost. This way instead of throwing away 70% of the wafer, you only throw away 20% - and if possible you could make a third SKU with fewer number of functional SPs and use close to 100% of the wafer.
Yields do improve over time, and what eventually happens if you build a product relying on harvesting is you hurt yourself financially. In the example above where you have two configurations of the same die, yields will eventually improve to the point where your 8 SP die could just as easily have 10 functional SPs but you have to sell them as reduced functionality parts because you’ve built up market demand for them. In a sense, you’re selling something worth $1 for $0.80. You could always create a new version of the chip with a smaller die, but that takes additional engineering resources, time and money.
The most recent public example of die harvesting was actually with NVIDIA’s GT200. The GeForce GTX 260 was simply a harvested version of the GTX 280 with 192 SPs vs. 240. As yields improved, NVIDIA introduced the GeForce GTX 260 Core 216 with 216 SPs. Note that NVIDIA didn’t use any repairability for the shader processors on GT200 there are no more than 240 functional SPs on a GT200 die, but that’s because NVIDIA would rely on harvesting anyway - if any of the 240 SPs didn’t work the chip would be branded as a GTX 260 or Core 216.
This is in stark contrast to RV770 where both versions of the GPU were functionally identical, the only differences were clock speeds and power requirements. But from a die standpoint, ATI didn’t have to sell any reduced versions of the chip to keep yields high.
Note that whether or not a company has to rely on harvesting doesn’t really impact the end user. In this case, the GeForce GTX 260 Core 216 actually benefitted the end user as it manages to deliver the same sort of value that AMD does with the Radeon HD 4870. It isn’t ideal for NVIDIA financially and if a company has to rely on harvesting for too long it will eventually take its toll, but I suspect that in the GT200 case NVIDIA will bail itself out with a 55nm revision of GT200 before things get too bad.
ATI didn’t want to build a GPU that would rely on excessive repair and harvesting to keep yields high. And then came the killer argument: building such a GPU was no longer in the best interests of its customers.
Sidenote: Building a GPU
Before we get too far down the rabbit hole it’s worth adding some perspective. ATI’s RV770 design took three years of work, that means ATI started in 2005. It takes about a year for manufacturability from tapeout to final product ship, another 1 - 1.5 years for design and another year for architecture.
The team that I met with in Santa Clara was talking about designs that would be out in 2012, we’re talking 4 TFLOPS of performance here, 4x the speed of RV770.
Decisions being made today are going to impact those products and in a sense it’s a big guessing game, ATI has no idea what NVIDIA will have in 2012 and NVIDIA has no idea what ATI will have. Each company simply tries to do the best it can for the customers and hopes they’ve got the right mix of performance, price and power.
To give you an idea of the intensity of some of these debates, Carrell debated, every evening, for three hours, for three weeks, the amount of repairability that would go into the RV770. Building redundant structures in the RV770 was an even bigger deal than before because ATI was going to be working within serious die constraints, simply making the chip bigger wasn’t an option. Repair structures in the RV770 wouldn’t add any performance but would increase the die size, on an already large chip that’s fine, but on a chip that’s supposed to target the sweet spot and can’t grow without limit it’s a big deal.








116 Comments
View All Comments
Chainlink - Saturday, December 6, 2008 - link
I've followed Anandtech for many years but never felt the need to respond to posts or reviews. I've always used anandtech as THE source of information for tech reviews and I just wanted to show my appreciation for this article.Following the graphics industry is certainly a challenge, I think I've owned most of the major cards mentioned in this insitful article. But to learn some of the background of why AMD/ATI made some of the decisions they did is just AWESOME.
I've always been AMD for CPU (won a XP1800+ at the Philly zoo!!!) and a mix of the red and green for GPUs. But I'm glad to see AMD back on track in both CPU and GPU especially (I actually have stock in them :/).
Thanks Anand for the best article I've read anywhere, it actually made me sign up to post this!
pyrosity - Saturday, December 6, 2008 - link
Anand & Co., AMD & Co.,Thank you. I'm not too much into following hardware these days but this article was interesting, informative, and insightful. You all have my appreciation for what amounts to a unique, humanizing story that feels like a diamond in the rough (not to say AT is "the rough," but perhaps the sea of reviews, charts, benchmarking--things that are so temporal).
Flyboy27 - Friday, December 5, 2008 - link
Amazing that you got to sit down with these folks. Great article. This is why I visit anandtech.com!BenSkywalker - Friday, December 5, 2008 - link
Is the ~$550 price point seen on ATi's current high end part evidence of them making their GPUs for the masses? If this entrire strategy is as exceptional as this article makes it out to be, and this was an effort to honestly give high end performance to the masses then why no lengthy conversation of how ATi currently offers, by a hefty margin, the most expensive graphics cards on the market? You even present the slide that demonstrates the key to obtaining the high end was scalability, yet you fail to discuss how their pricing structure is the same one nVidia was using, they simply chose to use two smaller GPUs in the place of one monolithic part. Not saying there is anything wrong with their approach at all- but your implication that it was a choice made around a populist mindset is quite out of place, and by a wide margin. They have the fastest part out, and they are charging a hefty premium for it. Wrong in any way? Absolutely not. An overall approach that has the same impact that nV or 3dfx before them had on consumers? Absolutely. Nothing remotely populist about it.From an engineering angle, it is very interesting how you gloss over the impact that 55nm had for ATi versus nVidia and in turn how this current direction will hold up when they are not dealing with a build process advantage. It also was interesting that quite a bit of time was given to the advantages that ATi's approach had over nV's in terms of costs, yet ATi's margins remain well behind that of nVidia's(not included in the article). All of these factors could have easily been left out of the article altogether and you could have left it as an article about the development of the RV770 from a human interest perspective.
This article could have been a lot better as a straight human interest fluff piece, by half bringing in some elements that are favorable to the direction of the article while leaving out any analysis from an engineering or business perspective from an objective standpoint this reads a lot more like a press release then journalism.
Garson007 - Friday, December 5, 2008 - link
Never in the article did it say anything about ATI turning socialistic. All it did mention was that they designed a performance card instead of an enthusiast one. How they approach to finally get to the enthusiast block, and how much it is priced, is completely irrelevant to the fact that they designed a performance card. This also allowed ATI to bring better graphics to lower priced segments because the relative scaling was much less than nVidia -still- has to undertake.The built process was mentioned. It is completely nVidia's prerogative to ignore a certain process until they create the architecture that works on one they already know; you are bringing up a coulda/woulda/shoulda situation around nVidia's strategy - when it means nothing to the current end-user. The future after all, is the future.
I'd respectfully disagree about the journalism statement, as I believe this to be a much higher form of journalism than a lot of what happens on the internet these days.
I'd also disagree with the people who say that AMD is any less secretive or anything. Looking in the article there is no real information in it which could disadvantage them in any way; all this article revealed about AMD is a more human side to the inner workings.
Thank you AMD for making this article possible, hopefully others will follow suit.
travbrad - Friday, December 5, 2008 - link
This was a really cool and interesting article, thanks for writing it. :)However there was one glaring flaw I noticed: "The Radeon 8500 wasn’t good at all; there was just no beating NVIDIA’s GeForce4, the Ti 4200 did well in the mainstream market and the Ti 4600 was king of the high end. "
That is a very misleading and flat-out false statement. The Radeon 8500 was launched in October 2001, and the Geforce 4 was launched in April 2002 (that's a 7 month difference). I would certainly hope a card launched more than half a year later was faster.
The Radeon 8500 was up against the Geforce3 when it was launched. It was generally as fast/faster than the similarly priced Ti200, and only a bit slower than the more expensive Ti500. Hardly what I would call "not good at all". Admittedly it wasn't nearly as popular as the Geforce3, but popularity != performance.
7Enigma - Friday, December 5, 2008 - link
That's all I have to say. As near to perfection as you can get in an article.hanstollo - Friday, December 5, 2008 - link
Hello, I've been visiting your site for about a year now and just wanted to let you know I'm really impressed with all of the work you guys do. Thank you so much for this article as i feel i really learned a whole lot from it. It was well written and kept me engaged. I had never heard of concepts like harvesting and repairability. I had no idea that three years went into designing this GPU. I love keeping up with hardware and really trust and admire your site. Thank you for taking the time to write this article.dvinnen - Friday, December 5, 2008 - link
Been reading this site for going on 8 years now and this article ranks up there with your best ever. As I've grown older and games have taken a back seat I find articles like this much more interesting. When a new product comes out I find myself reading the forwards and architectural bits of the articles and skipping over all the graphs to the conclusions.Anyways, just wish I was one of those brilliant programmers who was skilled enough to do massively parallelized programming.
quanta - Friday, December 5, 2008 - link
While the RV770 engineers may not have GDDR5 SDRAM to play with during its development, ATI can already use the GDDR4 SDRAM, which already has the memory bandwidth doubling that of GDDR5 SDRAM, AND it was already used in Radeon X1900 (R580+) cores. If there was any bandwidth superiority over NVIDIA, it was because of NVIDIA's refusal to switch to GDDR4, not lack of technology.