Nehalem - Everything You Need to Know about Intel's New Architecture
by Anand Lal Shimpi on November 3, 2008 1:00 PM EST- Posted in
- CPUs
Integrated Memory Controller
In Nehalem’s un-core lies a number of DDR3 memory controllers, on-die and off of the motherboard - finally. The first incarnation of Nehalem will ship with a triple-channel DDR3 memory controller, meaning that DDR3 DIMMs will have to be installed in sets of three in order to get peak bandwidth. Memory vendors will begin selling Nehalem memory kits with three DIMMs just for this reason. Future versions of Nehalem will ship with only two active controllers, but at the high end and for the server market we’ll have three.
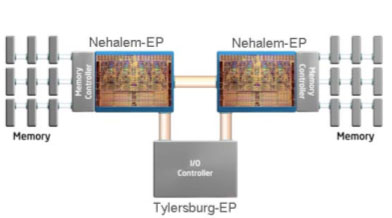
With three DDR3 memory channels, Nehalem will obviously have tons of memory bandwidth, which will help feed its wider and hungrier cores. A side effect of a tremendous increase in memory bandwidth is that Nehalem’s prefetchers can work much more aggressively.
I haven’t talked about Nehalem’s server focus in a couple of pages so here we go again. With Xeon and some server workloads, Core 2’s prefetchers were a bit too aggressive so for many enterprise applications the prefetchers were actually disabled. This mostly happened with applications that had very high bandwidth utilization, where the prefetchers would kick in and actually rob the system of useful memory bandwidth.
With Nehalem the prefetcher aggressiveness can be throttled back if there’s not enough available bandwidth.
QPI
When Intel made the move to an on-die memory controller it needed a high speed interconnect between chips, thus the Quick Path Interconnect (QPI) was born. I’m not sure whether or not QPI or Hyper Transport is a better name for this.
Each QPI link is bi-directional supporting 6.4 GT/s per link. Each link is 2-bytes wide so you get 12.8GB/s of bandwidth per link in each direction, for a total of 25.6GB/s of bandwidth on a single QPI link.
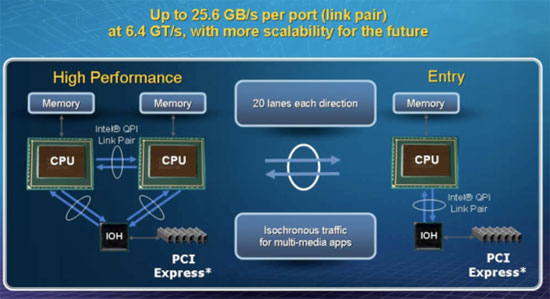
The high end Nehalem processors will have two QPI links while mainstream Nehalem chips will only have one.
The QPI aspect of Nehalem is much like HT with AMD’s processors, now developers need to worry about Intel systems being a NUMA platform. In a multi-socket Nehalem system, each socket will have its own local memory and applications need to ensure that the processor has its data in the memory attached to it rather than memory attached to an adjacent socket.
Here’s one area where AMD having being so much earlier with an IMC and HT really helps Intel. Much of the software work that has been done to take advantage of AMD’s architecture in the server world will now benefit Nehalem.
New Instructions
With Penryn, Intel extended the SSE4 instruction set to SSE4.1 and in Nehalem Intel added a few more instructions which Intel is calling SSE4.2.
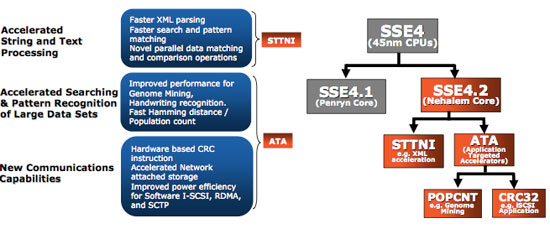
The future of Intel’s architectural extensions beyond Nehalem lie in the Advanced Vector Extensions (AVX), which add support for 256-bit vector operations. AVX is an intermediate step between where SSE is today and where Larrabee is going with its instruction set. At some point I suspect we may see some sort of merger between these two ISAs.









35 Comments
View All Comments
smilingcrow - Thursday, August 21, 2008 - link
You do realise that you aren’t meant to drink the snakeoil as it can rot your brain….JarredWalton - Friday, August 22, 2008 - link
I don't think Nehalem will "fail" at running games... in fact I expect it to be faster than Penryn at equivalent clocks. I just don't expect it to be significantly faster. We'll know soon enough, though.chizow - Friday, August 22, 2008 - link
I'd agree with the OP, maybe with a different choice of words. Also, Johan seems to disagree with you Jarred, citing the decreased L2 and slower L3 along with similar maximum clock speeds as to why Nehalem may perform worst than Penryn at the same clocks in games. We've already seen a very preliminary report substantiating this from Hexus:http://www.hexus.net/content/item.php?item=15015&a...">http://www.hexus.net/content/item.php?item=15015&a...
There's still a lot of questions about overclockability as well without a FSB. It appears Nehalem will run slightly hotter and draw a bit more power under load than Penryn with similar maximum clockspeeds when overclocked.
What's most disappointing is all of these new, hyped features seem to amount to squat with Nehalem. Where's the benefit of the IMC? Where's the benefit of the triple channel memory bus? Where's the benefit of HT? I know....I know...its for the server market/HPC crowd, but no one finds it odd that something like an IMC is resulting in negligible gaming gains when it was such a boon for AMD's Athlon 64?
All in all, very disappointing for the Gamer/Enthusiast as we'll most likely have to wait for Westmere for a significant improvement over Penryn (or even Kentsfield) in games.
cornelius785 - Sunday, August 24, 2008 - link
From looking at that article, I have doubts that it could be worse than penryn in games. I also doubt that the performance increase is going to be the same as it was for Core 2. People are expecting this and since their figuring out that their unrealistic expectations can't be realized in Nehalem, they call Nehalem trash and say they'll go back to amd, ignoring the fact that Intel is still king in gaming with EXISTING processors. It is also not like 50 fps at extremely high setting and resolution isn't playable.JarredWalton - Friday, August 22, 2008 - link
Given that is early hardware, most likely not fully optimized, and performance is still substantially better than the QX6800 in several gaming tests (remember I said clock-for-clock I expected it to be faster, not necessarily faster than a 3.2GHz part when it's running at 2.93GHz).... Well, it's going to be close, but overall I think the final platform will be faster. Johan hasn't tested any games on the platform, so that's just speculation. Anyway, it's probably going to end up being a minor speed bump for gaming, and a big boost everywhere else.Felofasofanz - Thursday, August 21, 2008 - link
It was my understanding that tick was the new architecture and tock was the shrink. I thought Conroe was tick, Penryn tock, then Nehalem tick, and the 32nm shrink tock?npp - Thursday, August 21, 2008 - link
I think we're facing a strange issue right now, and it's about the degree of usefulness of Core i7 for the average user. Enterprise clients will surely benefit a lot from all the improvements introduced, but I would have hard time convincing my friends to upgrade from their E8400...And it's not about badly-threaded applications, the ones an average user has installed simply don't require such immense computing power. Look at your browser, or e-mail client - the tasks they execute are pretty well split over different threads, but they simply don't need 8 logical CPUs to run fast, most of them simply sit idle. It's a completely different matter that many applications who happen to be resource-hungry can't be parallelized to a reasonable degree - think about encryption/decryption, or similar, for example.
It seems to me that the Gustafson's law begins to speak here - if you can't escape your seqential code, make your task bigger. So expect something like UltraMegaHD soon, then try to transcode it in real time... But then again... who needs that? It seems like a cowardly manner to me.
Is it that software is laging behing technology? We need new OSes, completely different ways of interaction with our computers in order to justify so much GFLOPs on the desktop, in my opinion. Or that's at least what I'm dreaming of. The level of man-machine interaction has barely changed since the mouse was invented, and modern OSes are very similar to the very first OSes with a GUI, maybe somewhere in the 80s, or even earlier. But for that time span CPUs have increased their capabilities almost exponentially, can you spot a problem here?
The issue becomes clearer if we talk about 16-threaded octacores... God, I can't think of an application that would require that. (Let's be honest - most people don't transcode video or fold proteins all the time...). I think it would be great if a new Apple or Microsoft would emerge from some small garage, to come and change the old picture for good. The only way to justify technology would be to change the whole user-machine paradigm significantly, going the old way leads to nowhere, I suspect.
gamerk2 - Tuesday, August 26, 2008 - link
Actually, Windows is the biggest bottleneck there is. Windows doesn't SCALE. It does limited tasks well, but breaks under heavy loads.Even the M$ guys are realizing this. Midori will likely be the new post-windows OS after Vista SP2 (windows 7).
smilingcrow - Thursday, August 21, 2008 - link
So eventually we may end up with a separate class of systems that are akin to ‘proper’ sports cars with prices to match. Intel seemingly already sees this as a potential which is why they are releasing a separate high end platform for Nehalem. Unless a new killer app or two is found that appeals to the mainstream I can’t see many people wanting to pay a large premium for these systems since as the entry level performance continues to rise less and less people require anything more than what they offer.One thing mitigating against this is the current relatively low cost of workstation/server Dual Processor components which should continue to be affordable due to the strong demand for them within businesses. It’s foreseeable that it might eventually be more cost affective to build a DP workstation system than a UP high end desktop. This matches Apple’s current product range where they completely miss out on high end UP desktops and jump straight from mid range UP desktop to DP workstation.
retardliquidator - Thursday, August 21, 2008 - link
... think again.more luck next time before starting the flamebait about not two bytes wide but 20bits.
effective usable speed is exactly 2bytes, as with 10/8 coding you need 20bits to encode your 16 relevant ones.
you fail at failing.