Intel's Larrabee Architecture Disclosure: A Calculated First Move
by Anand Lal Shimpi & Derek Wilson on August 4, 2008 12:00 AM EST- Posted in
- GPUs
Not Quite a Pentium, Not Quite an Atom: The Larrabee Core
Intel gave us enough information about Larrabee to begin a discussion of specifications, but not enough to even begin making any conclusions. We'll start with what we pretty much already know.
Intel's Larrabee is built out of a number of x86 cores that look, at a very high level, like this:
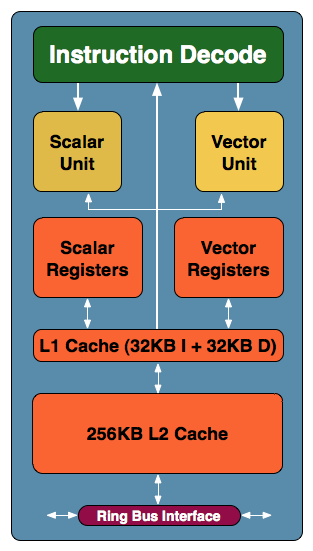
Each core is a dual-issue, in-order architecture loosely derived from the original Pentium microprocessor. The Pentium core was modified to include support for 64-bit operations, the updates to the x86 instruction set, larger caches, 4-way SMT/Hyper Threading and a 16-wide vector ALU.
While the team that ended up working on Atom may have originally worked on the Larrabee cores, there are some significant differences between Larrabee and Atom. Atom is geared towards much higher single threaded performance, with a deeper pipeline, a larger L2 cache and additional microarchitectural tweaks to improve general desktop performance.
| Intel Larrabee Core | Intel Pentium Core (P54C) | Intel Atom Core | |
| Manufacturing Process | 45nm | 0.60µm | 45nm |
| Simultaneous Multi-Threading | 4-way | 1-way | 2-way |
| Issue Width | dual-issue | dual-issue | dual-issue |
| Pipeline Depth | 5-stages (?) | 5-stages | 16-stages |
| Scalar Execution Resources | 2 x Integer ALUs (?) 1 x FPU (?) | 2 x Integer ALUs 1 x FPU | 2 x Integer ALUs 1 x FPU |
| Vector Execution Resources | 16-wide Vector ALU | None | 1 x SIMD SSE |
| L1 Cache (I/D) | 32KB/32KB | 8KB/8KB | 32KB/24KB |
| L2 Cache | 256KB | None (External) | 512KB |
| ISA | 64-bit x86 SSEn support? Parallel/Graphics? | 32-bit x86 | 64-bit x86 Full Merom ISA compatibility |
Larrabee on the other hand is more Pentium-like to begin with; Intel states that Larrabee's execution pipeline is "short" and followed up with us by saying that it's closer to the 5-stage pipeline of the original Pentium than the 16-stage pipeline of Atom. While both Atom and Larrabee support SMT (Simultaneous Multi-Threading), Larrabee can work on four threads concurrently compared to two on Atom and one on the original Pentium.
L1 cache sizes are similar between Larrabee and Atom, but Larrabee gets a full 32KB data cache compared to 24KB on Atom. If you remember back to our architectural discussion of Atom, the smaller L1 D-cache was a side effect of going to a register file instead of a small signal array for the cache. Die size increased but operating voltage decreased, forcing Atom to have a smaller L1 D-cache but enabling it to reach lower power targets. Larrabee is a little less constrained and thus we have conventional balanced L1 caches, at 4x the size of that in the original Pentium.
The Pentium had no on-die L2 cache, it relied on external SRAM to be installed on the motherboard. In order to maintain good desktop performance Atom came equipped with a 512KB L2 cache, while each Larrabee core will feature a 256KB L2 cache. Larrabee's architecture does stress the importance of large, fast caches as you'll soon see, but 256KB is the right size for Intel's architecture at this point. Larrabee's default OpenGL/DirectX renderer is tile based and it turns out that most 64x64 or 128x128 tiles with 32-bit color/32-bit Z can fit in a 128KB space, leaving an additional 128KB left over for caching additional data. And remember, this is just on one Larrabee core - the whole GPU will be built out of many more.
The big difference between Larrabee, Pentium and Atom is in the vector execution side. The original Pentium had no SIMD units, Atom added support for SSE and Larrabee takes a giant leap with a massive 16-wide vector ALU. This unit is able to work on up to 16 32-bit floating point operations simultaneously, making it far wider than any of the aforementioned cores. Given the nature of the applications that Larrabee will be targeting, such a wide vector unit makes total sense.
Other changes to the Pentium core that made it into Larrabee are things like 64-bit x86 support and hardware prefetchers, although it is unknown as to how these compare to Atom's prefetchers. It is a fair guess to say that prefetching will include optimizations for data parallel situations, but whether this is in addition to other prefetch technology or a replacement for it is something we'll have to wait to find out.








101 Comments
View All Comments
NeonFlak - Thursday, November 15, 2012 - link
"Remember that Larrabee won't ship until sometime in 2009 or 2010, the first chips aren't even back from the fab yet, so not wanting to discuss how many cores Intel will be able to fit on a single Larrabee GPU makes sense. "