The Radeon HD 4850 & 4870: AMD Wins at $199 and $299
by Anand Lal Shimpi & Derek Wilson on June 25, 2008 12:00 AM EST- Posted in
- GPUs
That Darn Compute:Texture Ratio
With its GT200 GPU, NVIDIA increased compute resources by nearly 90% but only increased texture processing by 25%, highlighting a continued trend in making GPUs even more powerful computationally. Here's another glance at the GT200's texture address and filter units:
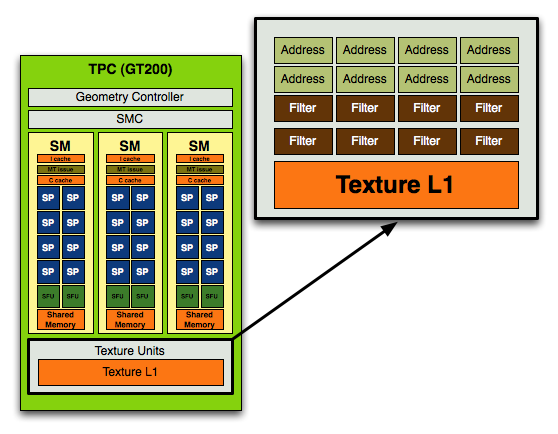
Each TPC, of which there are 10, has eight address and eight filter units. Now let's look at RV770:
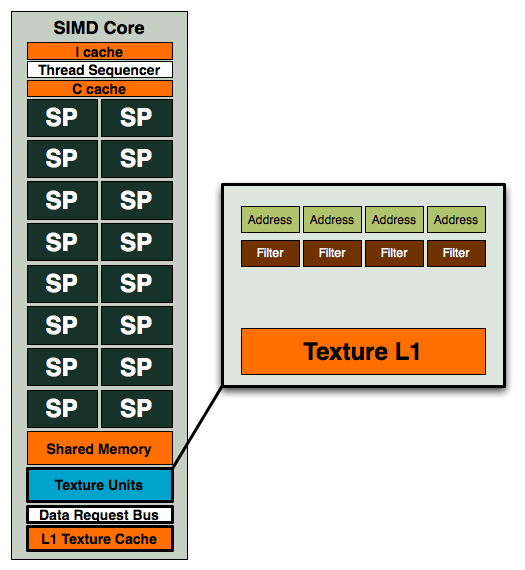
Four address and four filter units, while AMD maintains the same 1:1 address-to-filter ratio that NVIDIA does, the ratio of compute-to-texture in RV770 is significantly higher.
| AMD RV770 | AMD RV670 | NVIDIA GT200 | NVIDIA G92 | |
| # of SPs | 160 | 64 | 240 | 128 |
| Texture Address/Filter Units | 40 / 40 | 16 / 16 | 80 / 80 | 64 / 64 |
| Compute to Texture Ratio | 4:1 | 4:1 | 3:1 | 2:1 |
The table above illustrates NVIDIA's trend of increasing the compute to texture ratio from 2:1 in G92 to 3:1 in GT200. AMD arguably overshot with RV670 and its 4:1 ratio and thus didn't need to adjust it with RV770. Even while staying still at 4:1 with RV770, AMD's ratio is still more aggressively geared towards compute than NVIDIA's is. That does mean that more texture bound games will do better on NVIDIA hardware (at least proportionally), while more compute intensive games may do better on RV770.
AMD did also make some enhancements to their texture units as well. By doing some "stuff" that they won't tell us about, they improved the performance per mm^2 by 70%. Texture cache bandwidth has also been doubled to 480 GB/s while bandwidth between each L1 cache and L2 memory is 384 GB/s. L2 caches are aligned with memory channels of which there are four interleaved channels (resulting in 8 L2 caches).
Now that texture units are linked to both specific SIMD cores and individual L1 texture caches, we have an increase in total texturing ability due to the increase in SIMD cores with RV770. This gives us a 2.5x increase in the number of 8-bit per component textures we can fetch and bilinearly filter per clock, but only a 1.25x increase in the number of fp16 textures (as fp16 runs at half rate and fp32 runs at one quarter rate). It was our understanding that fp16 textures could run at full speed on R600, so the 1.25x increase in performance for half rate texturing of fp16 data makes sense.
Even though fp32 runs at quarter rate, with the types of texture fetches we would need to do, AMD says that we could end up being external memory bandwidth bound before we are texture filtering hardware bound. If this is the case, then the design decision to decrease rates for higher bit-depth textures makes sense.
| AMD RV770 | AMD RV670 | |
| L1 Texture Cache | 10 x 16KB (160KB total) | 32KB |
| L2 Texture Cache | I can has cache size? | 256KB |
| Vertex Cache | ? | 32KB |
| Local Data Share | 16KB | None |
| Global Data Share | 16KB | ? |
Even though AMD wouldn't tell us L1 cache sizes, we had enough info left over from the R600 time frame to combine with some hints and extract the data. We have determined that RV770 has 10 distinct 16k caches. This is as opposed to the single shared 32k L1 cache on R600 and gives us a total of 160k of L1 cache. We know R600's L2 cache was 256k, and AMD told us RV770 has a larger L2 cache, but they wouldn't give us any hints to help out.








215 Comments
View All Comments
natty1 - Thursday, June 26, 2008 - link
There's no good reason to pull that garbage. People assume they are seeing raw numbers when they read these reviews.DerekWilson - Sunday, June 29, 2008 - link
i don't understand what you mean by raw numbers ... these are the numbers we got in our tests ...we can't do crossfire on the nvidia board we tested and we can't do sli on the intel board we tested ...
we do have another option (skulltrail) but people seemed not to like that we went there ... and it was a pain in the ass to test with. plus fb-dimm performance leaves something to be desired.
in any case, without testing every solution in two different platforms we did the best we could in the time we had. it might be interesting to look at testing single card performance in two different platforms for all cards, but that will have to be a separate article and would be way to tough to do for a launch.
Denithor - Wednesday, June 25, 2008 - link
In Bioshock in the multiGPU section the SLI 9800GTX+ seems to fall down on the job. In all other benches this SLI beats out the GTX 280 easily, here it fails miserably. While even the SLI 8800GT beats the GTX 280. Methinks something's wrong here.jamstan - Wednesday, June 25, 2008 - link
Egg's got them for 309.99. I'm gonna run 2 4870s in CF. I planned on using a P45 board but I am wondering if the P45s X8 per card will bottleneck the bandwidth and if I should go with an X48 board instead? When I research CF all I seem to find is "losing any bandwidth at X8 versus X16 is "debateable". What I'm thinking is that 8 pipelines can handle 4GBs so if I look at the 4870s 3.6 Gbs of memory bandwidth then X8 should be able to handle the 4870 without any performance hits. It that correct or am I all wet?jamstan - Friday, June 27, 2008 - link
I contacted ATI and they said I was correct. A P45 board only running X8 per card in CF will bottleneck the massive DDR5 bandwidth of the 4870s. If you're gonna CF 2 4870s use an X38 or X48 board.SVM79 - Wednesday, June 25, 2008 - link
I created an account just to say how awesome this article was. It was really nice to see all the technical details laid out and compared to the competition. I was lucky to get in on that $150 hd4850 price at best buy last week and I am hoping the future drivers with improve performance even more. Please keep up the good work on these articles!!!DerekWilson - Sunday, June 29, 2008 - link
Wow, Anand and I are honored.We absolutely appreciate the feedback we've gotten from all of you guys (even the bad stuff cause it helps us refine our future articles).
of course we enjoy the good stuff more :-)
thanks again, everyone.
D3SI - Wednesday, June 25, 2008 - link
Long time reader, first time postergreat article, very informative
looks like the 4870 is the card to get, cant be beat at that price
and yes a lot of posters are reading way too much into it "you're biased waaa waaa boo hoo"
just get the facts from the article (thats what the charts and graphs are for) and then make your decision, if you cant do simple math and come to the conclusion yourself that the $300 card is a better buy than the $650 then you deserve to get ripped off.
joeschleprock - Wednesday, June 25, 2008 - link
nVidia just got their pussy smoked.kelectron - Wednesday, June 25, 2008 - link
a very important comparison is missing. for those who want to go in for a multi-GPU setup, the 260 SLI vs 4870 CF is a very important consideration since SLI scaling has always been better than CF, and the 260 scales very very well.in that case, if nvidia responds by reducing the price on the 260, the 260 SLI could be the real winner here. but sadly there were no 260 SLI benches.
please give us a 260 SLI vs 4870 CF review.